
一、基本信息
- 本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
- 项目 Git地址 :https://gitee.com/ntucs/PairProg/tree/SE020_021
- 成员:1613072020 周展 1613072021 屈聪聪
- 开发环境 Centos 7 64位 Python 3.7.1
二、项目分析
Task1:基本任务
- 程序运行模块(方法、函数)介绍
读文件到缓冲区
def process_file(dst): # 读文件到缓冲区
global file
global count
try: # 打开文件
file=open(dst,'r',encoding='ISO-8859-1')
f= open(dst, 'r', encoding='ISO-8859-1')
except IOError as s:
print('IOError',s)
return None
try: # 读文件到缓冲区
bvffer=file.read()
except:
print("Read File Error!")
return None
lines=f.readlines()
for line in lines:
line=line.strip()
if len(line)!=0:
count+=1
else:
continue
file.close()
f.close()
return bvffer
存放如字典模块
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
content=bvffer.lower()
content = content.replace('\n', ' ')
regex=re.compile('[^a-zA-Z0-9\s]')
content_result=regex.sub('',content)
content_result.lower()
content_result=content_result.split(' ')
while '' in content_result:
content_result.remove('')
#print(content_result)
for word in content_result:
if word in list_stopwords:
continue
else:
if re.match('[a-zA-z]{4,}[a-zA-Z0-9]{0,}',word,re.I)!=None:
if word_freq.__contains__(word):
word_freq[word] = word_freq[word] + 1
else:
word_freq[word] = 1
else:
continue
return word_freq
单词出现次数进行排序输出
def output_result(word_freq):
out=open('result.txt','w')
if word_freq:
print('lines:',count,file=out)
print('words:' + str(word_freq.__len__()),file=out)
for word in word_freq[:10]:
print(word[0],':',word[1],file=out)
out.close()
排序
def dic_sorted(dict):
return sorted(dict.items(), key=lambda x: x[1], reverse=True)
def load_stopwords():
global list_stopwords
file_stopwords=open('stopwords.txt','r',encoding='utf-8')
content=file_stopwords.readlines()
for word in content:
list_stopwords.append(word)
主函数
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
word_freq=dic_sorted(word_freq)
#print(word_freq)
output_result(word_freq)
- 程序算法的时间、空间复杂度分析
时间复杂度为O(n),空间复杂度为O(n)
- 程序运行案例截图

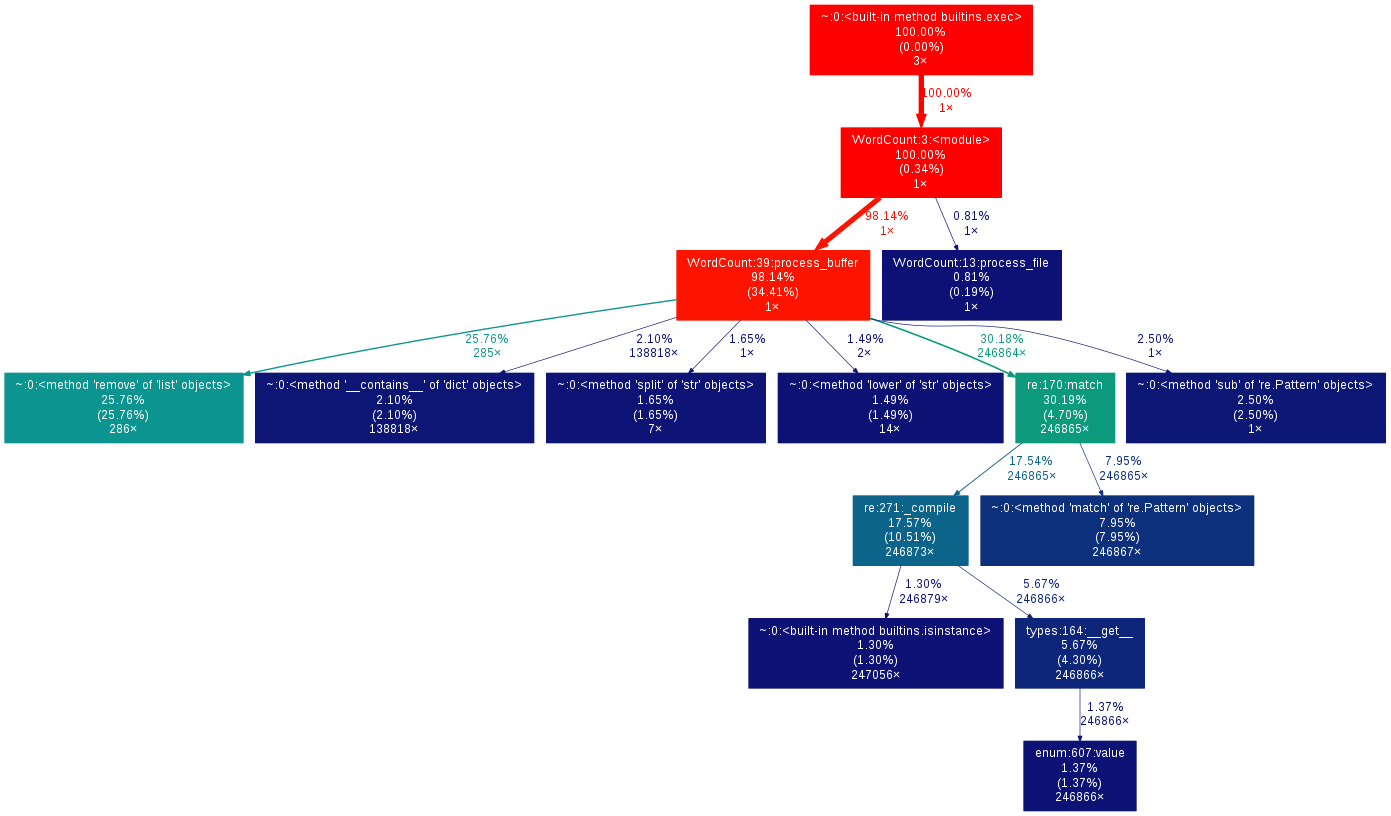
三、性能分析
四、其他
- 结对编程时间开销
本次结对编程之前我们做了很多有关python语言的学习,所以在实际编程的时候花的时间并不算多,大概在4-5小时之间。
- 结队编程照片

五、事后分析与总结
- 简述结对编程时,针对某个问题的讨论决策过程
针对不少问题如同关于输出排序功能的实现,我收到了屈聪聪同学的不少启发,他优秀的编程能力和思路是我们组的巨大助力。
一开始统计行数的时候,发现文件打开之后read是空的,经过研究后发现,进行open()操作之后,不能进行多次read()操作。讨论后决定使用多次open操作 来解决问题。关于input.txt,一开始是ansi编码的,结果发现read的时候报错,原因是编码不对。最后一律把input.txt转换为utf-8编码后才解决报错。
- 评价对方:请评价一下你的合作伙伴,又哪些具体的优点和需要改进的地方,这个部分两人都要提供自己的看法
周展对屈聪聪的评价:编程能力优秀,交流清晰,很好的帮助同组的我理解内容,在这次结对编程中他让我了解到了一个优秀的队友对于整个团队至关重要,也意识到自己的不足之处,我从他的身上学到了很多。
屈聪聪对周展的评价:虽然不熟悉python语言,但仍然在一旁认真学习,也提出了不少意见完善程序,也积极撰写报告,分担了不少压力。
- 评价整个过程:关于结对过程的建议
结对的过程我们分析和认清了自己的工作定位,让实际效率提升了不少。团队内工作分配至关重要,如果分配工作出现问题,双方的工作都处于自己不擅长的领域,效率就会很低,而且没有工作的热情,也就是所谓的1+1<2。团队内处理一些问题也需要互相交流,我们组的两个人都属于比较健谈的人,所以处理起问题也并不含糊。
- 其它
结对编程这种经历在学校内也是很少有的,这种经历可以让我们以后走入工作岗位的时候可以做好心理准备。
