

Linux进程线程学习笔记:进程创建
Linux进程线程学习笔记:进程创建
周银辉
各位同学,转换下思维,这里说的是“进程”, 不是“线程”,OK,我们开始
“进程”二字似乎总有那么些“只可意会不可言传”的韵味,维基百科是这样来解释的:
进程(英语:Process,台湾译作行程)是计算机中已运行程序的物理。进程本身不会运行,是线程的容器。程序本身只是指令的集合,进程才是程序(那些指令)的真正运行。若干进程有可能与同一个程序相关系,且每个进程皆可以同步(循序)或不同步(平行)的方式独立运行(多线程即每一个线程都代表一个进程)。现代计算机系统可在同一段时间内加载多个程序和进程到存储器中,并借由时间共享(或称多任务),以在一个处理器上表现出同时(平行性)运行的感觉。同样的,使用多线程技术的操作系统或计算机架构,同样程序的平行进程,可在多 CPU 主机或网络上真正同时运行(在不同的 CPU 上)。进程为现今分时系统的基本运作单位。
也有朋友如此来阐述,
一个可以执行的程序;
和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等);
程序的执行上下文(execution context)
我更希望将这些简化一下(或许不太准确):指令和执行指令所需的环境,指令可以理解成“代码”,环境可以理解成“上下文”
系统用一个叫做“进程表”的东西来维护中系统中的进程,进程表中的一个条目维护着存储着一个进程的相关信息,比如进程号,进程状态,寄存器值等等...
当分配给进程A的“时间片”使用完时,CPU会进行上下文切换以便运行其他进程,比如进程B,这里所谓的“上下文切换”,主要就是在操作那个“进程表”,其将进程A的相关信息(上下文)保存到其对应的进程表项中, 与之相反,其会从对应于进程B的进程表项中读取相关信息并运行之。
那么,如果进程A新建了一个进程C呢?教程表会多这样一个表项,并且该表项拥有一个唯一的ID,也就是进程号(PID),进程表项的其他值大部分与进程A的相同,具体说来,就是C和A共享代码段,并且C将A的数据空间,堆栈等复制一份 ,然后从A创建C的地方开始运行。
A和C的相似度极大,除了以下方面(来自这里: http://opengroup.org/onlinepubs/007908775/xsh/fork.html ):
The new process (child process) is an exact copy of the calling process (parent process) except as detailed below.
-
The child process has a unique process ID.
-
The child process ID also does not match any active process group ID.
-
The child process has a different parent process ID (that is, the process ID of the parent process).
-
The child process has its own copy of the parent's file descriptors. Each of the child's file descriptors refers to the same open file description with the corresponding file descriptor of the parent.
-
The child process has its own copy of the parent's open directory streams. Each open directory stream in the child process may share directory stream positioning with the corresponding directory stream of the parent.
-
The child process may have its own copy of the parent's message catalogue descriptors.
-
The child process' values of tms_utime, tms_stime, tms_cutime and tms_cstime are set to 0.
-
The time left until an alarm clock signal is reset to 0.
-
All semadj values are cleared.
-
File locks set by the parent process are not inherited by the child process.
-
The set of signals pending for the child process is initialised to the empty set.
-
Interval timers are reset in the child process.
-
If the Semaphores option is supported, any semaphores that are open in the parent process will also be open in the child process.
-
If the Process Memory Locking option is supported, the child process does not inherit any address space memory locks established by the parent process via calls to mlockall() or mlock().
-
Memory mappings created in the parent are retained in the child process. MAP_PRIVATE mappings inherited from the parent will also be MAP_PRIVATE mappings in the child, and any modifications to the data in these mappings made by the parent prior to calling fork()will be visible to the child. Any modifications to the data in MAP_PRIVATE mappings made by the parent after fork() returns will be visible only to the parent. Modifications to the data in MAP_PRIVATE mappings made by the child will be visible only to the child.
-
If the Process Scheduling option is supported, for the SCHED_FIFO and SCHED_RR scheduling policies, the child process inherits the policy and priority settings of the parent process during a fork() function. For other scheduling policies, the policy and priority settings on fork()are implementation-dependent.
-
If the Timers option is supported, per-process timers created by the parent are not inherited by the child process.
-
If the Message Passing option is supported, the child process has its own copy of the message queue descriptors of the parent. Each of the message descriptors of the child refers to the same open message queue description as the corresponding message descriptor of the parent.
-
If the Asynchronous Input and Output option is supported, no asynchronous input or asynchronous output operations are inherited by the child process.
从代码角度来看,创建一个新进程的函数声明如下:
其包含在 unistd.h 头文件中,其中pid_t是表示“type of process id”的32位整数, 至于函数的返回值,取决于在哪个进程中来检测该值,如果是在新创建的进程中,其为0;如果是在父进程中(创建新进程的进程),其为新创建的进程的id; 如果创建失败,则返回负值。
我们看下面的代码:

#include <unistd.h>
int main ()
{
printf("app start...\n");
pid_t id = fork();
if (id<0) {
printf("error\n");
}else if (id==0) {
printf("hi, i'm in new process, my id is %d \n", getpid());
}else {
printf("hi, i'm in old process, the return value is %d\n", id);
}
return 0;
}
为了方便理解,我在上面使用了getpid函数,其返回当前进程的id。
程序输出为:
hi, i'm in old process, the return value is 5429
hi, i'm in new process, my id is 5429
另外,看到不少资料上说“fork函数是少数返回两个值的函数”,我不赞成该说法,我猜想,其之所以看上去有着不同的值,是系统创建新进程并复制父进程相关资源时,故意根据创建状态放入了不同的值。
fork函数失败的原因主要是没有足够的资源来进行创建或者进程表满,如果是非root权限的账户,则可能被管理员设置了最大进程数。一个用户所能创建的最大进程数限制是很重要的,否则一句代码就可能把主机搞当机:for(;;) fork();
再看下面的代码:
#include <unistd.h>
int main ()
{
printf("app start...\n");
int counter = 0;
fork();
counter++;
printf("the counter value %d\n", counter);
return 0;
}
输出如下:
the counter value 1
the counter value 1
之所以会这样,画个图就明白了:
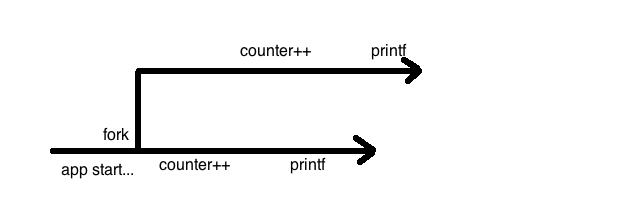
并且,新进程得到的是父进程的副本,所以,父子进程counter变量不会相互影响。
再来一个demo:
#include <unistd.h>
int main ()
{
printf("app start...");
fork();
return 0;
}
好奇怪是吧?情况是这样的:
当你调用printf时,字符串被写入stdout缓冲区(还没刷到屏幕上的哦),然后fork,子进程复制了父进程的缓冲区,所以子进程的stdout缓冲区中也包含了“app start ...”这个字符串,然后父子进程各自运行,当他们遇到return语句时,缓冲器会被强制刷新,然后就分别将“app start...”刷到了屏幕上。如果想避免,在fork前,调用fflush强制刷新下缓冲区就可以了,在字符串后面加上“\n”也可以,因为stdout是按行缓冲的。
哈,大概就这么多,至于如何创建一个新进程以运行一个新程序,稍候我会谈exec函数,它们两者相结合就可以了~






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2008-09-01 [Prism]Composite Application Guidance for WPF(6)——服务