

面向对象进阶
概要:1.程序规范
2.面向对象相关内置方法
3.反射
4.魔法方法
5.面试题,经典指派例子
6.三个常用模块 hashlib logging configparser
程序规范
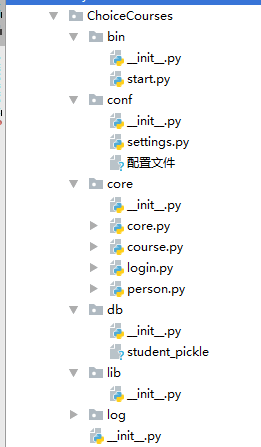
1.bin目录--存放执行脚本
里面有一个start.py文件,作文执行程序的开始


import os import sys BaseDir = os.path.dirname(os.path.dirname(os.getcwd())) #获取包的路径 sys.path.append(BaseDir) #把包添加到导入搜索路径 from ChoiceCourses.core import core core.main()
2.conf目录---存放配置文件
3.core目录---存放核心逻辑代码
4.db目录---存放数据库文件
5.lib目录---存放自定义的模块与包
6.log目录---存放日志
#=============>bin目录:存放执行脚本 #start.py import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import core from conf import my_log_settings if __name__ == '__main__': my_log_settings.load_my_logging_cfg() core.run() #=============>conf目录:存放配置文件 #config.ini [DEFAULT] user_timeout = 1000 [egon] password = 123 money = 10000000 [alex] password = alex3714 money=10000000000 [yuanhao] password = ysb123 money=10 #settings.py import os config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini') user_timeout=10 user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),\ 'db') #my_log_settings.py """ logging配置 """ import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = r'%s\log' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg() #=============>core目录:存放核心逻辑 #core.py import logging import time from conf import settings from lib import read_ini config=read_ini.read(settings.config_path) logger=logging.getLogger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)} def auth(func): def wrapper(*args,**kwargs): if current_user['user']: interval=time.time()-current_user['login_time'] if interval < current_user['timeout']: return func(*args,**kwargs) name = input('name>>: ') password = input('password>>: ') if config.has_section(name): if password == config.get(name,'password'): logger.info('登录成功') current_user['user']=name current_user['login_time']=time.time() return func(*args,**kwargs) else: logger.error('用户名不存在') return wrapper @auth def buy(): print('buy...') @auth def run(): print(''' 购物 查看余额 转账 ''') while True: choice = input('>>: ').strip() if not choice:continue if choice == '1': buy() if __name__ == '__main__': run() #=============>db目录:存放数据库文件 #alex_json #egon_json #=============>lib目录:存放自定义的模块与包 #read_ini.py import configparser def read(config_file): config=configparser.ConfigParser() config.read(config_file) return config #=============>log目录:存放日志 #all2.log [2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
isinstancefrom collections import Iterable
print(isinstance(range(10),Iterable)) #判断是不是可迭代序列
print(isinstance(10,int)) #type(10) is int type的方法更好一点
判断一个对象是不是这个类的实例,如果这个类有父类,那么这个对象也是其父类的对象
class Foo(object):pass obj = Foo() print(isinstance(obj, Foo)) #判断第一个参数是否是第二个参数的对象,返回一个布尔值 print(isinstance(obj, object))
issubclass()
: 判断两个类是不是父子关系,接受两个参数(子类,父类)
反射
2 python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
1.getattr 获取属性
class SB:
def __init__(self,name):
self.name = name
def happy(self,x):
print('sb %s is happy'%self.name)
return x+'aaaaaa'
jinghong = SB('景弘') #实例化对象
func = getattr(jinghong,'happy') #相当于jinghong.happy
ret = getattr(jinghong,'name') #相当于jinghong.name
# func2 = getattr(jinghong,'sleep') #没有这个属性或者方法就会报错
func('bbb') #sb 景弘 is happy
print(ret) #景弘
2.hasattr 检查是否含有某属性
class Login():
def login(self):
print('login')
def register(self):
print('register')
l = Login() #实例化对象
f = input('func >>>') #用户输入字符串
if hasattr(l,f): #判断f是否是对象l的属性
getattr(l,f)() #如果是的话获得方法名,加()直接执行 相当于l.login
3.setattr 设置属性
class SB:
def __init__(self,name):
self.name = name
def happy(self,x):
print('sb %s is happy'%self.name)
return x+'aaaaaa'
jinghong = SB('景弘')
setattr(jinghong,'sex','female') #设置jinghong对象的sex属性为female
print(jinghong.sex) #female
4.delattr 删除属性
class SB:
def __init__(self,name):
self.name = name
def happy(self,x):
print('sb %s is happy'%self.name)
return x+'aaaaaa'
jinghong = SB('景弘')
setattr(jinghong,'sex','female') #设置jinghong对象的sex属性为female
delattr(jinghong,'sex')
print(jinghong.sex) #没有会报错
class Foo(object): staticField = "old boy" def __init__(self): self.name = 'wupeiqi' def func(self): return 'func' @staticmethod def bar(): return 'bar' print getattr(Foo, 'staticField') print getattr(Foo, 'func') print getattr(Foo, 'bar') 类也是对象
#!/usr/bin/env python # -*- coding:utf-8 -*- import sys def s1(): print 's1' def s2(): print 's2' this_module = sys.modules[__name__] hasattr(this_module, 's1') getattr(this_module, 's2') 反射当前模块成员
导入其他模块,利用反射查找该模块是否存在某个方法
#!/usr/bin/env python # -*- coding:utf-8 -*- def test(): print('from the test')
#!/usr/bin/env python # -*- coding:utf-8 -*- """ 程序目录: module_test.py index.py 当前文件: index.py """ import module_test as obj #obj.test() print(hasattr(obj,'test')) getattr(obj,'test')()
魔法方法
所有魔法方法整理:http://bbs.fishc.com/forum.php?mod=viewthread&tid=48793&extra=page%3D1%26filter%3Dtypeid%26typeid%3D403
1. __repr__ 和 __str__和__fromat__
__repr__定义当被repr()调用时的行为
__str__定义当被str()调用时的行为
自定制格式化字符串__format__
format_dict={ 'nat':'{obj.name}-{obj.addr}-{obj.type}',#学校名-学校地址-学校类型 'tna':'{obj.type}:{obj.name}:{obj.addr}',#学校类型:学校名:学校地址 'tan':'{obj.type}/{obj.addr}/{obj.name}',#学校类型/学校地址/学校名 } class School: def __init__(self,name,addr,type): self.name=name self.addr=addr self.type=type def __repr__(self): return 'School(%s,%s)' %(self.name,self.addr) def __str__(self): return '(%s,%s)' %(self.name,self.addr) def __format__(self, format_spec): # if format_spec if not format_spec or format_spec not in format_dict: #如果format_spec是Felse或者不存在于列表 format_spec='nat' #就设置fromat_spec 等于第一项 nat fmt=format_dict[format_spec] return fmt.format(obj=self) s1=School('oldboy1','北京','私立') print('from repr: ',repr(s1)) #触发__repr__ print('from str: ',str(s1)) #触发__str__ print(s1) #触发__str__ ''' str函数或者print函数--->obj.__str__() repr或者交互式解释器--->obj.__repr__() 如果__str__没有被定义,那么就会使用__repr__来代替输出 注意:这俩方法的返回值必须是字符串,否则抛出异常 ''' print(format(s1,'nat')) #oldboy1-北京-私立 print(format(s1,'tna')) #私立:oldboy1:北京 print(format(s1,'tan')) #私立/北京/oldboy1 print(format(s1,'')) #oldboy1-北京-私立
class B: def __str__(self): return 'str : class B' def __repr__(self): return 'repr : class B' b = B() print('%s' % b) #str : class B print('%r' % b) #repr : class B
2. __del__ 析构方法
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,
所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
class Foo: def __del__(self): print('执行我啦') f1=Foo() del f1 print('------->') #输出结果 执行我啦 -------> 简单示范
3. item系列
class Foo: def __init__(self,name): self.name=name def __getitem__(self, item): print(self.__dict__[item]) def __setitem__(self, key, value): self.__dict__[key]=value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key) def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item) f1=Foo('sb') f1['age']=18 f1['age1']=19 #触发__setitem__ del f1.age1 #触发__delattr__ del f1['age'] #触发__delitem__ f1['name']='alex' print(f1.__dict__)
4.__new__
class A: def __init__(self): #对象初始化时触发 self.x = 1 print('in init function') def __new__(cls, *args, **kwargs): #创建对象时最先触发 print('in new function') return object.__new__(A, *args, **kwargs) a = A() print(a.x) #输出顺序 # in new function # in init function # 1
单例模式 实例始终只有一个 他的属性可以随着你的改变而改变
class Teacher: #创建一个老师类 __isinstance = None #创建一个私有静态变量来装裸着的对象 def __new__(cls, *args, **kwargs): #创建一个裸着的对象 if not cls.__isinstance: #如果__isinstance属性为None cls.__isinstance = object.__new__(cls) #用object.__new__创建一个裸着的对象 return cls.__isinstance #返回一个对象 def __init__(self,name,cloth): #self就是cls.__isinstance返回的对象 self.name = name #给self的name属性赋值 self.cloth = cloth #给self的cloth属性赋值 刘老师 = Teacher('刘永熹','白色') print(刘老师.name) 王老师 = Teacher('王庆帅','黑色') 王老师2 = Teacher('王庆帅','黑色') 王老师3 = Teacher('王庆帅','黑色') 王老师4 = Teacher('王庆帅','黑色') print(刘老师.name) print(王老师) print(王老师2) print(王老师3) print(王老师4)
class Singleton: def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance one = Singleton() two = Singleton() two.a = 3 print(one.a) # 3 # one和two完全相同,可以用id(), ==, is检测 print(id(one)) # 29097904 print(id(two)) # 29097904 print(one == two) # True print(one is two) 单例模式
5.__call__
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
class Foo: def __init__(self): pass def __call__(self, *args, **kwargs): print('__call__') obj = Foo() # 执行 __init__ obj() # 执行 __call__
6.__len__
class A: def __init__(self): self.a = 1 self.b = 2 def __len__(self): return len(self.__dict__) a = A() print(len(a))
7.__hash__
class A: def __init__(self): self.a = 1 self.b = 2 def __hash__(self): return hash(str(self.a)+str(self.b)) a = A() print(hash(a))
8.__eq__ 定义等于号的行为: x == y 调用x.__eq__(y)
class A: def __init__(self): self.a = 1 self.b = 2 def __eq__(self,obj): if self.a == obj.a and self.b == obj.b: return True a = A() b = A() print(a == b)
经典例子
class FranchDeck: ranks = [str(n) for n in range(2,11)] + list('JQKA') suits = ['红心','方板','梅花','黑桃'] def __init__(self): self._cards = [Card(rank,suit) for rank in FranchDeck.ranks for suit in FranchDeck.suits] def __len__(self): return len(self._cards) def __getitem__(self, item): return self._cards[item] deck = FranchDeck() print(deck[0]) from random import choice print(choice(deck)) print(choice(deck))
class FranchDeck: ranks = [str(n) for n in range(2,11)] + list('JQKA') suits = ['红心','方板','梅花','黑桃'] def __init__(self): self._cards = [Card(rank,suit) for rank in FranchDeck.ranks for suit in FranchDeck.suits] def __len__(self): return len(self._cards) def __getitem__(self, item): return self._cards[item] def __setitem__(self, key, value): self._cards[key] = value deck = FranchDeck() print(deck[0]) from random import choice print(choice(deck)) #抽取一张,需要知道列表的长度,重新定义__len__方法 print(choice(deck)) from random import shuffle shuffle(deck) print(deck[:5]) 纸牌游戏2
class Person: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex def __hash__(self): return hash(self.name+self.sex) def __eq__(self, other): if self.name == other.name and self.sex == other.sex:return True p_lst = [] for i in range(84): p_lst.append(Person('egon',i,'male')) print(p_lst) print(set(p_lst)) 一道面试题
常用模块补充 hashlib logging configparser
常用模块:http://www.cnblogs.com/Eva-J/articles/7228075.html#_label12
1.hashlib 摘要算法
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?') print md5.hexdigest() 计算结果如下: d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5()
md5.update('how to use md5 in ')
md5.update('python hashlib?')
print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in ')
sha1.update('python hashlib?')
print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
检验文件一致性
# #检验文件的一致性的 import os filesize = os.path.getsize('文章') #os.path.getsize('文章')得到这个文件有多少个字节 f = open('文章','rb') #二进制方式读 md5_obj = hashlib.md5() #用md5方法 while filesize > 0 : readsize = 10 if filesize>10 else filesize #大于10就读十个字节,小于或等于10就读剩下的字节 content = f.read(readsize) #一次读十个字节 md5_obj.update(content) filesize -= readsize #总自己长度减掉每次读的 print(md5_obj.hexdigest()) #计算出md5值
存储密码文件
存储密文密码 f = open('userinfo','w') md5 = hashlib.md5() md5.update(b'3714') md5_value = md5.hexdigest() f.write('alex|%s\n'%md5_value) f.close()
登录验证
pwd = input('pwd : ') f = open('userinfo') alex_info = f.readline().strip() user,passwd = alex_info.split('|') md5 = hashlib.md5(b'salt') #(b'zhou') 是加言 md5.update(bytes(pwd,encoding='utf-8')) print(md5.hexdigest()) if passwd == md5.hexdigest(): print('登录成功')
md5 单向的,只能摘要成密文,不能反解
对于一个长字符串分次update的结果和一次update的结果相同
检测文件一致性
文字文件:逐行读
视频文件:按字节读
密码的密文存储
暴力破解 撞库
md5加盐的过程
2.logging模块
函数式简单配置
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message') #默认等级,低于这个等级的不打印
logging.error('error message')
logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:

import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='/tmp/test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
配置参数
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
logger对象配置
import logging logger = logging.getLogger()
# 创建一个handler,用于写入日志文件 fh = logging.FileHandler('test.log') # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')
封装成函数使用
def log(filename):
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler(filename,encoding='utf-8')
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
sh = logging.StreamHandler()
formatter2 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
sh.setFormatter(formatter2)
logger.addHandler(sh)
return logger
logger = log('log')
logger.debug('debug hello')
logger.warning('你好')
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过
fh.setLevel(logging.Debug)单对文件流设置某个级别。
3.configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
创建文件
来看一个好多软件的常见文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as configfile:
config.write(configfile)
查找文件
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read('example.ini')
print(config.sections()) # ['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print('bitbucket.org' in config) # True
print(config['bitbucket.org']["user"]) # hg
print(config['DEFAULT']['Compression']) #yes
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org>
for key in config['bitbucket.org']: # 注意,有default会默认default的键
print(key)
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
增删改操作
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('yuan')
config.remove_section('bitbucket.org')
config.remove_option('topsecret.server.com',"forwardx11")
config.set('topsecret.server.com','k1','11111')
config.set('yuan','k2','22222')
config.write(open('new2.ini', "w"))
