

MySQL 5.7 Replication 相关新功能说明
背景:
MySQL5.7在主从复制上面相对之前版本多了一些新特性,包括多源复制、基于组提交的并行复制、在线修改Replication Filter、GTID增强、半同步复制增强等。因为都是和复制相关,所以本文将针对这些新特性放一起进行说明,篇幅可能稍长,本文使用的MySQL版本是5.7.13。
1,多源复制(多主一从)
MySQL在5.7之后才支持多源复制,之前介绍过MariaDB 多主一从 搭建测试说明,现在介绍如何在MySQL上做多主一从,具体的方法说明可以查看官方文档。
原理:多源复制加入了一个叫做Channel的概念, 每一个Channel都是一个独立的Slave,都有一个IO_THREAD和SQL_THREAD。原理和普通复制一样。我们只需要对每一个Master执行Change Master 语句,只需要在每个语句最后使用For Channel来进行区分。由于复制的原理没有改变,在没有开启GTID的时候Master的版本可以是MySQL5.5、5.6、5.7。并且从库需要master-info-repository、relay-log-info-repository设置为table,否则会报错:
ERROR 3077 (HY000): To have multiple channels, repository cannot be of type FILE; Please check the repository configuration and convert them to TABLE.
① 测试环境:
5台主机(1从4主):
MySQL5.5 : 10.0.3.202 MySQL5.6 : 10.0.3.162 MySQL5.7 : 10.0.3.141 MySQL5.7 : 10.0.3.219 MySQL5.7 : 10.0.3.251
② 复制账号:
mysql> CREATE USER 'repl'@'10.0.3.%' IDENTIFIED BY 'Repl_123456'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'10.0.3.%'; Query OK, 0 rows affected (0.00 sec)
③ Change:这里先说明通过binlog文件名和position的普通复制,后面会专门介绍GTID的复制。10.0.3.251(MySQL5.7)做从库,这里需要注意:从的版本若是5.7.x~5.7.13,主的版本不能是MySQL5.5,因为MySQL5.5没有server_uuid函数。该问题在MySQL5.7.13里修复(Bug #22748612)。
CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_LOG_FILE='mysql-bin-3306.000001',MASTER_LOG_POS=154 FOR CHANNEL 't22'; CHANGE MASTER TO MASTER_HOST='10.0.3.162',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=120 FOR CHANNEL 't21'; CHANGE MASTER TO MASTER_HOST='10.0.3.202',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_LOG_FILE='mysql-bin-3306.000001',MASTER_LOG_POS=107 FOR CHANNEL 't10'; CHANGE MASTER TO MASTER_HOST='10.0.3.219',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_LOG_FILE='mysql-bin-3306.000001',MASTER_LOG_POS=154 FOR CHANNEL 't23';
④ 相关操作:
查看单个channel的状态:
show slave status for channel 't10'\G
停止单个channel的同步:
stop slave for channel 't10';
开启单个channel的同步:
start slave for channel 't10';
重置单个channel:
reset slave all for channel 't10';
查看所有channel:
show slave status\G
停止所有channel:
stop slave;
开启所有channel:
start slave;
跳过一个channel的报错(类似MariaDB的default_master_connection):


channel 't10' 报错: mysql> show slave status for channel 't10'\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.0.3.202 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin-3306.000001 Read_Master_Log_Pos: 827 Relay_Log_File: mysqld-relay-bin-t10.000006 Relay_Log_Pos: 767 Relay_Master_Log_File: mysql-bin-3306.000001 Slave_IO_Running: Yes Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1062 Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 0 failed executing transaction 'ANONYMOUS' at master log mysql-bin-3306.000001, end_log_pos 800. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any. Skip_Counter: 0 Exec_Master_Log_Pos: 646 Relay_Log_Space: 1303 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 1062 Last_SQL_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 0 failed executing transaction 'ANONYMOUS' at master log mysql-bin-3306.000001, end_log_pos 800. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any. Replicate_Ignore_Server_Ids: Master_Server_Id: 5 Master_UUID: Master_Info_File: mysql.slave_master_info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: 160725 19:10:08 Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: t10 Master_TLS_Version:
处理方法:先停止所有的channel,再执行 sql_slave_skip_counter,接着开启报错的channel,最后开启所有的channel。
一: #stop all slaves stop slave; # set skip counter set global sql_slave_skip_counter=1; # start slave that shall skip one entry start slave for channel 't10'; set global sql_slave_skip_counter=0; # start all other slaves start slave; 二: 也可以直接停掉错误的channel,再skip: stop slave for channel 't10'; set global sql_slave_skip_counter=1; start slave for channel 't10';
⑤ 监控:系统库performance_schema增加了一些replication的监控表:
mysql> show tables like 'replicat%'; +-------------------------------------------+ | Tables_in_performance_schema (replicat%) | +-------------------------------------------+ | replication_applier_configuration |###查看各个channel是否配置了复制延迟 | replication_applier_status |###查看各个channel是否复制正常(service_state)以及事务重连的次数 | replication_applier_status_by_coordinator |###查看各个channel是否复制正常,以及复制错误的code、message和时间 | replication_applier_status_by_worker |###查看各个channel是否复制正常,以及并行复制work号,复制错误的code、SQL和时间 | replication_connection_configuration |###查看各个channel的连接配置信息:host、port、user、auto_position等 | replication_connection_status |###查看各个channel的连接信息 | replication_group_member_stats |### | replication_group_members |### +-------------------------------------------+
...
2,在线调整Replication Filter
在上面搭建的主从基础上,进行过滤规则的添加,比如需要过滤dba_test数据库:
先关闭sql线程,要是在多源复制中,是关闭所有channel的sql thread。 mysql> stop slave sql_thread; Query OK, 0 rows affected (0.01 sec) #过滤1个库 mysql> CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB=(dba_test); #过滤2个库 mysql> CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB=(dba_test1,dba_test); Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; Query OK, 0 rows affected (0.04 sec)
通过show slave status 查看:
Replicate_Do_DB:
Replicate_Ignore_DB: dba_test1,dba_test
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
比如设置同步dba_test2库中t1开头的表:
mysql> stop slave sql_thread; Query OK, 0 rows affected (0.01 sec) mysql> CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE =('dba_test2.t1%'); Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; Query OK, 0 rows affected (0.04 sec)
还原成默认值,即设置成空():
mysql> stop slave sql_thread; Query OK, 0 rows affected (0.01 sec) mysql> CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=(); Query OK, 0 rows affected (0.00 sec) mysql> CHANGE REPLICATION FILTER Replicate_Ignore_DB=(); Query OK, 0 rows affected (0.00 sec) mysql> CHANGE REPLICATION FILTER Replicate_Wild_Ignore_Table=(); Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; Query OK, 0 rows affected (0.04 sec)
用红色字体标记的这个参数就是设置在配置文件的参数,如上面的几个参数既可以在命令行里执行(5.7)也可以在配置文件里添加。注意一点是在线执行完后,一定要在配置文件里写,以免重启后失效。
...
3,基于组提交(LOGICAL_CLOCK)的并行复制
①:原理说明
MySQL5.7通过参数--slave-parallel-type=MySQL 5.7并行复制实现原理与调优。type进行控制并行复制的方式,可选值有DATABASE(默认)和LOGICAL_CLOCK,详细的说明可以看
MySQL5.6版本之前,Slave服务器上有两个线程:I/O线程和SQL线程。I/O线程负责接收二进制日志(更准确的说是二进制日志的event),SQL线程进行回放二进制日志。
MySQL5.6的并行复制是基于库的(database),开启并行复制SQL线程就变为了coordinator线程,coordinator线程主要负责以前两部分的内容:判断可以并行执行,那么选择worker线程执行事务的二进制日志;判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的worker线程执行完成之后,再执行当前的日志。对于有多个数据库的实例,开启并行的执行SQL,对从库能有较大的提升。但对单个库,开启多线程复制,性能可能比单线程还差。
MySQL5.7的并行复制是基于组提交(LOGICAL_CLOCK),即master服务器上是怎么并行执行的slave上就怎样进行并行回放,很好的解决了主从复制延迟的问题。主要思想是一个组提交的事务都是可以并行回放到从,原理是基于锁的冲突检测,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差。
总的来说就是:并发线程执行不同的事务只要在同一时刻能够commit(说明线程之间没有锁冲突),那么master节点就可以将这一组的事务标记并在slave机器上安全的进行并发重放主库提交的事务。所以尽可能的使所有线程能在同一时刻提交可以,可以极大的提高slave机器并发执行事务的数量使主备数据同步。有兴趣的可以看MySQL和MariaDB实现对比。
相关参数:
binlog_group_commit_sync_delay:表示binlog提交后等待延迟多少时间再同步到磁盘,单位是微秒,默认0,不延迟。设置延迟可以让多个事务在用一时刻提交,提高binlog组提交的并发数和效率,从而提高slave的吞吐量。
binlog_group_commit_sync_no_delay_count:表示在等待上面参数超时之前,如果有足够多的事务,则停止等待直接提交。单位是事务数,默认0。
上面提到一个组提交的事务都是可以并行回放到从,那么如何知道事务是否在一组中?在MySQL 5.7版本中,其设计方式是将组提交的信息存放在GTID中。那么如果用户没有开启GTID功能,即将参数gtid_mode设置为OFF呢?故MySQL 5.7又引入了称之为Anonymous_Gtid的二进制日志event类型,如:
mysql> SHOW BINLOG EVENTS in 'mysql-bin-3306.000004' limit 5; +-----------------------+-----+----------------+-----------+-------------+-----------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+-----+----------------+-----------+-------------+-----------------------------------------+ | mysql-bin-3306.000004 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.13-6-log, Binlog ver: 4 | | mysql-bin-3306.000004 | 123 | Previous_gtids | 1 | 154 | | | mysql-bin-3306.000004 | 154 | Anonymous_Gtid | 1 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin-3306.000004 | 219 | Query | 1 | 306 | BEGIN | | mysql-bin-3306.000004 | 306 | Intvar | 1 | 338 | INSERT_ID=3462831 | +-----------------------+-----+----------------+-----------+-------------+-----------------------------------------+
关于event_type的更多信息可以看:MySQL【Row】下的 Event_type和MySQL【statement】下的 Event_type,这里Gtid有自己类型的event。这意味着在MySQL 5.7版本中即使不开启GTID,每个事务开始前也是会存在一个Anonymous_Gtid,而这GTID中就存在着组提交的信息。通过上述的SHOW BINLOG EVENTS,我们并没有发现有关组提交的任何信息。但是通过mysqlbinlog工具,用户就能发现组提交的内部信息:
root@t22:~# mysqlbinlog mysql-bin-3306.000004 | grep last_committed #160726 23:40:09 server id 1 end_log_pos 302010138 CRC32 0xf5950910 Anonymous_GTID last_committed=1566 sequence_number=1567 #160726 23:40:09 server id 1 end_log_pos 302010676 CRC32 0xb9b3038c Anonymous_GTID last_committed=1566 sequence_number=1568 #160726 23:40:09 server id 1 end_log_pos 302011214 CRC32 0x30f1ec4e Anonymous_GTID last_committed=1566 sequence_number=1569 #160726 23:40:09 server id 1 end_log_pos 302011752 CRC32 0x44443efe Anonymous_GTID last_committed=1566 sequence_number=1570 #160726 23:40:09 server id 1 end_log_pos 302012290 CRC32 0x79fe16ec Anonymous_GTID last_committed=1566 sequence_number=1571 #160726 23:40:09 server id 1 end_log_pos 302012828 CRC32 0x5ab82ffa Anonymous_GTID last_committed=1567 sequence_number=1572 #160726 23:40:09 server id 1 end_log_pos 302013366 CRC32 0x84be9418 Anonymous_GTID last_committed=1571 sequence_number=1573 #160726 23:40:09 server id 1 end_log_pos 302013904 CRC32 0x9c8945e1 Anonymous_GTID last_committed=1571 sequence_number=1574 #160726 23:40:09 server id 1 end_log_pos 302014442 CRC32 0x7949a96a Anonymous_GTID last_committed=1571 sequence_number=1575 #160726 23:40:09 server id 1 end_log_pos 302014980 CRC32 0xfce4bad5 Anonymous_GTID last_committed=1571 sequence_number=1576 #160726 23:40:09 server id 1 end_log_pos 302015518 CRC32 0x41b1077a Anonymous_GTID last_committed=1572 sequence_number=1577
可以发现较之原来的二进制日志内容多了last_committed和sequence_number,last_committed表示事务提交的时候,上次事务提交的编号。如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。例如上述last_committed为1566的事务有5个,表示组提交时提交了5个事务,而这5个事务在从上可以并行执行。
② 开启并行复制:只需要在slave开启参数:
[mysqld] # * slave slave_parallel_workers = 4 ###并行复制的线程数 slave_parallel_type = LOGICAL_CLOCK ###并行复制的类型,默认database master_info_repository = table relay_log_info_repository = table relay_log_recovery = 1
③ 强一致性的提交顺序:
通过参数slave_preserve_commit_order可以控制Slave上的binlog提交顺序和Master上的binlog的提交顺序一样,保证GTID的顺序。该参数只能用于开启了logical clock并且启用了binlog的复制。即对于多线程复制,该参数用来保障事务在slave上执行的顺序与relay log中的顺序严格一致。
比如两个事务依次操作了2个DB:A和B,尽管事务A、B分别被worker X、Y线程接收,但是因为线程调度的问题,有可能导致A的执行时机落后于B。如果经常是“跨DB”操作,那么可以考虑使用此参数限定顺序。当此参数开启时,要求任何worker线程执行事务时,只有当前事务中之前的所有事务都执行后(被其他worker线程执行),才能执行和提交。(每个事务中,都记录了当前GTID的privious GTID,只有privious GTID被提交后,当前GTID事务才能提交)
开启该参数可能会有一点的消耗,因为会让slave的binlog提交产生等待。
④ 并行复制的测试:测试的工具是sysbench,之前介绍过sysbench安装、使用和测试,现在使用sysbench的0.5版本,不支持--test=oltp,需要用lua脚本来代替。可以看可以看sysbench安装、使用、结果解读和使用sysbench对mysql压力测试。
分2种情况:一种是原始的单线程复制,或则是基于database的复制,第二种是MySQL5.7基于组提交的并行复制。
1)单线程复制:这里用insert.lua脚本的目的是想在纯写入的条件下,看从是否有延迟。
mysql> show variables like 'slave_parallel%'; +------------------------+----------+ | Variable_name | Value | +------------------------+----------+ | slave_parallel_type | DATABASE | | slave_parallel_workers | 0 | +------------------------+----------+
生成测试数据和表:生成4张表,存储引擎为innodb,100万数据。
sysbench --test=/usr/share/doc/sysbench/tests/db/insert.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=dba_test --oltp-table-size=1000000 --oltp_tables_count=4 --rand-init=on --mysql-user=zjy --mysql-password=zjy prepare
压力测试:更多的压力测试见MySQL压力测试基准值
sysbench --test=/usr/share/doc/sysbench/tests/db/insert.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=dba_test --num-threads=8 --oltp-table-size=1000000 --oltp_tables_count=4 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=600 --max-requests=0 --percentile=99 --mysql-user=zjy --mysql-password=zjy run
清理:
sysbench --test=/usr/share/doc/sysbench/tests/db/insert.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=dba_test --num-threads=8 --oltp-table-size=1000000 --oltp_tables_count=4 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=600 --max-requests=0 --percentile=99 --mysql-user=zjy --mysql-password=zjy cleanup
测试结果:
因为主从在同一台PC机上,性能不高。从上面5分钟的压测结果来看:有延迟,最大延迟达到360s;从库QPS保持在2000左右。因为压测只在一个库里,所以database的并行复制和单线程复制效果一样。
2)并行复制:
mysql> show variables like 'slave_parallel%'; +------------------------+---------------+ | Variable_name | Value | +------------------------+---------------+ | slave_parallel_type | LOGICAL_CLOCK | | slave_parallel_workers | 8 | +------------------------+---------------+
按照上面的方法生成数据和表、压测。测试结果:
因为主从在同一台PC机上,性能不高。从上面5分钟的压测结果来看:有延迟,最大延迟达到180s;从库QPS保持在3500左右。对比单线程的并发,确实提升了50%,但是还是有延迟。可以修改一个参数binlog_group_commit_sync_delay来优化。
本次的测试目的是想说明并行复制能够提高从库服务器的利用率和可用性,提升多少还要看服务器性能。本文测试的环境是一个普通的PC机,主从数据库在一起,并且使用insert.lua的纯写入脚本,IO争用的厉害,只能看到一点优势。有兴趣的可以使用oltp.lua脚本和主从分开进行测试。更多的一些测试说明可以看MySQL 5.7并行复制实现原理与调优。
4,Gtid功能的增强
之前介绍过MySQL5.6 新特性之GTID,GTID的基本概念可以看这篇文章,在MySQL5.7中对Gtid做了一些增强,现在进行一些说明。
GTID即全局事务ID(global transaction identifier),GTID实际上是由UUID+TID(Sequence Number)组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。下面是一个GTID的具体形式:
4e659069-3cd8-11e5-9a49-001c4270714e:1
GTID的目的是简化复制的使用过程和降低复制集群维护的难度,不再依赖Master的binlog文件名和文件中的位置。
CHANGE MASTER TO MASTER_LOG_FILE=‘Master-bin.000010’, MASTER_LOG_POS=‘214’; 简化成: CHANGE MASTER TO MASTER_AUTO_POSITION=1;
MASTER_AUTO_POSITION的原理:
MySQL Server记录了所有已经执行了的事务的GTID,包括复制过来的(可以通过select @@global.gtid_executed查看)。
Slave记录了所有从Master接收过来的事务的GTID(可以通过Retrieve_gtid_set查看)。
Slave连接到Master时,会把gtid_executed中的gtid发给Master,Master会自动跳过这些事务,只将没有复制的事务发送到Slave去。
上面介绍的是GTID的基本概念,GTID相关变量:
binlog_gtid_simple_recovery :MySQL5.7.7之后默认on,这个参数控制了当mysql启动或重启时,mysql在搜寻GTIDs时是如何迭代使用binlog文件。该参数为真时,mysql-server只需打开最老的和最新的这2个binlog文件,gtid_purged参数的值和gtid_executed参数的值可以根据这些文件中的Previous_gtids_log_event或者Gtid_log_event计算得出。这确保了当mysql-server重启或清理binlog时,只需打开2个binlog文件。当这个参数设置为off,在mysql恢复期间,为了初始化gtid_executed,所有以最新文件开始的binlog都要被检查。并且为了初始化gtid_purged,所有的binlog都要被检查。这可能需要非常长的时间,建议开启。注意:MySQL5.6中,默认为off,调整这个选项设置也同样会提升性能,但是在一些特殊场景下,计算gtids值可能会出错。而保持这个选项值为off,能确保计算总是正确。
enforce_gtid_consistency:默认off,可选值有on和warn。根据该变量的值,服务器只允许可以安全使用GTID记录的语句通过,强制GTID一致性。在启用基于GTID复制之前将此变量需要设置为on。
OFF :不检测是否有GTID不支持的语句和事务。 Warn :当检测到不支持GTID的语句和事务,返回警告,并在日志中记录。 ON :当检测到不支持GTID的语句和事务,返回错误。
gtid_mode:控制是否开启GTID,默认OFF。可选值有OFF、OFF_PERMISSIVE、ON、ON_PERMISSIVE。
OFF :不产生GTID,Slave只接受不带GTID的事务 OFF_PERMISSIVE :不产生GTID,Slave即接受不带GTID的事务,也接受带GTID的事务 ON_PERMISSIVE :产生GTID,Slave即接受不带GTID的事务,也接受带GTID的事务 ON :产生GTID,Slave只能接受带GTID的事务。
session_track_gtids:控制用于捕获GTIDs和在OK PACKE返回的跟踪器。
OFF :关闭 OWN_GTID :返回当前事务产生的GTID ALL_GTIDS :返回系统执行的所有GTID,也就是GTID_EXECUTED
gtid_purged:已经被删除的binlog的事务。
gtid_owned: 表示正在执行的事务的gtid以及对应的线程ID。
gtid_executed:表示已经在该实例上执行过的事务(mysql.gtid_executed), 执行RESET MASTER会将该变量置空(清空mysql.gtid_executed),可以通过设置GTID_NEXT执行一个空事务,来影响GTID_EXECUTED。GTID_NEXT是SESSION级别变量,表示下一个将被使用的GTID。
gtid_executed_compression_period:默认1000个事务,表示控制每执行多少个事务,对此表(mysql.gtid_executed)进行压缩。
介绍了GTID的概念和变量,现在说下MySQL5.7下GTID增强的一些特性:
①:在线开启GTID。MySQL5.6开启GTID的功能需要重启服务器生效。
mysql> set global gtid_mode=on; ERROR 1788 (HY000): The value of @@GLOBAL.GTID_MODE can only be changed one step at a time: OFF <-> OFF_PERMISSIVE <-> ON_PERMISSIVE <-> ON. Also note that this value must be stepped up or down simultaneously on all servers. See the Manual for instructions.
mysql> set global gtid_mode=OFF_PERMISSIVE; Query OK, 0 rows affected (0.17 sec) mysql> set global gtid_mode=ON_PERMISSIVE; Query OK, 0 rows affected (0.14 sec)
#等一段时间, 让不带GTID的binlog events在所有的服务器上执行完毕
mysql> set global gtid_mode=ON; ERROR 3111 (HY000): SET @@GLOBAL.GTID_MODE = ON is not allowed because ENFORCE_GTID_CONSISTENCY is not ON. mysql> set global enforce_gtid_consistency=on; Query OK, 0 rows affected (0.00 sec) mysql> set global gtid_mode=ON; Query OK, 0 rows affected (0.16 sec)
在线开启GTID的步骤:不是直接设置gtid_mode为on,需要先设置成OFF_PERMISSIVE,再设置成ON_PERMISSIVE,再把enforce_gtid_consistency设置成ON,最后再将gtid_mode设置成on,如上面所示。若保证GTID重启服务器继续有效,则需要再配置文件里添加:
gtid-mode=on enforce-gtid-consistency=on
在线启用GTID功能的好处:不需要重启数据库,配置过程在线,整个复制集群仍然对外提供读和写的服务;不需要改变复制拓扑结构;可以在任何结构的复制集群中在线启用GTID功能。
②:存储GTID信息到表中,slave不需要再开启log_bin和log_slave_updates。表存在在mysql.gtid_executed,MySQL5.6上GTID只能存储在binlog中,所以必须开启Binlog才能使用GTID功能。
如何记录GTID到表中?这里有2种情况:
1)如果开启了binlog,在切换binlog时将当前binlog的所有GTID插入gtid_executed表中。插入操作等价于一个或多个INSERT语句。
INSERT INTO mysql.gtid_executed(UUID, 1, 100)
2)如果没有开启binlog,每个事务在提交之前会执行一个等价的INSERT的操作。 此操作是该事务的一部分,和事务的其他操作整体保持原子性。 需要保证gtid_executed是innodb存储引擎。
BEGIN; ... INSERT INTO mysql.gtid_executed(UUID, 101, 101); COMMIT;
为什么把GTID记录到表中,原因是什么?
MySQL5.6中必须配置参数log_slave_updates的最重要原因在于当slave重启后,无法得知当前slave已经运行到的GTID位置,因为变量gtid_executed是一个内存值,所以MySQL 5.6的处理方法就是启动时扫描最后一个二进制日志,获取当前执行到的GTID位置信息。如果不小心将二进制日志删除了,那么这又会带来灾难性的问题。因此MySQL5.7将gtid_executed这个值给持久化了。因为gtid写表了,表gtid_executed中的记录会增长,所以MySQL 5.7又引入了新的线程,用来对此表进行压缩,通过参数gtid_executed_compression_period用来控制每执行多少个事务,对此表进行压缩,默认值为1000个事务。
表(mysql.gtid_executed)压缩前后对比:
压缩前: +--------------------------------------+----------------+--------------+ | source_uuid | interval_start | interval_end | +--------------------------------------+----------------+--------------+ | xxxxxxxx-4733-11e6-91fe-507b9d0eac6d | 1 | 1 | +--------------------------------------+----------------+--------------+ | xxxxxxxx-4733-11e6-91fe-507b9d0eac6d | 2 | 2 | +--------------------------------------+----------------+--------------+ | xxxxxxxx-4733-11e6-91fe-507b9d0eac6d | 3 | 3 | +--------------------------------------+----------------+--------------+ 压缩后: +--------------------------------------+----------------+--------------+ | source_uuid | interval_start | interval_end | +--------------------------------------+----------------+--------------+ | xxxxxxxx-4733-11e6-91fe-507b9d0eac6d | 1 | 3 | +--------------------------------------+----------------+--------------+
通过命令:SET GLOBAL gtid_executed_compression_period = N(事务的数量) 来控制压缩频率。
③:GTID受限制的语句。
1)使用CREATE TABLE ... SELECT... 语句。
2)事务中同时使用了支持事务和不支持事务的引擎。
3)在事务中使用CREATE/DROP TEMPORARY TABLE。
不支持的语句出现,会报错:
ERROR 1786 (HY000): Statement violates GTID consistency:...
④:测试,具体GTID的测试可以看看MySQL5.6 新特性之GTID。
注意:主和从要一起开启GTID,只开启任意一个都会报错:
Last_IO_Errno: 1593 Last_IO_Error: The replication receiver thread cannot start because the master has GTID_MODE = ON and this server has GTID_MODE = OFF.
搭建GTID的复制环境,可以查看官方文档。
MySQL5.7.4之前的slave必须要开启binlog和log_slave_updates,之后不需要开启,原因上面已经说明。
slave 关闭了binlog: mysql> show variables like 'log_%'; +----------------------------------------+-------------------------------+ | Variable_name | Value | +----------------------------------------+-------------------------------+ | log_bin | OFF | | log_slave_updates | OFF | +----------------------------------------+-------------------------------+
执行change:
mysql> CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1; Query OK, 0 rows affected, 2 warnings (0.29 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec) mysql> show slave status\G
GTID复制增加了一个master_auto_position参数,该参数不能和master_log_file和master_log_pos一起出现,否则会报错:
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
检查是否开启了GTID的复制:
Master上: mysql> show processlist\G; *************************** 1. row *************************** Id: 4 User: repl Host: 10.0.3.219:35408 db: NULL Command: Binlog Dump GTID Time: 847 State: Master has sent all binlog to slave; waiting for more updates Info: NULL Rows_sent: 0 Rows_examined: 0 mysql> show binlog events in 'mysql-bin-3306.000002'; +-----------------------+-----+----------------+-----------+-------------+---------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +-----------------------+-----+----------------+-----------+-------------+---------------------------------------------+ | mysql-bin-3306.000002 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.13-6-log, Binlog ver: 4 | | mysql-bin-3306.000002 | 123 | Previous_gtids | 1 | 194 | 7b389a77-4423-11e6-8e6b-00163ec0a235:1-4 | | mysql-bin-3306.000002 | 194 | Gtid | 1 | 259 | SET @@SESSION.GTID_NEXT= '7b389a77-4423-11e6-8e6b-00163ec0a235:5' | | mysql-bin-3306.000002 | 259 | Query | 1 | 346 | BEGIN | | mysql-bin-3306.000002 | 346 | Query | 1 | 475 | use `dba_test`; insert into gtid values(1,'AAAAA'),(2,'BBBBBB') | | mysql-bin-3306.000002 | 475 | Xid | 1 | 506 | COMMIT /* xid=35 */ | +-----------------------+-----+----------------+-----------+-------------+---------------------------------------------+
⑤:错误跳过和异常处理:gtid_next、gtid_purged。之前的文章MySQL5.6 新特性之GTID介绍了如何跳过一些常见的复制错误,这里再大致的说明下大致的处理步骤。
mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Slave_IO_Running: Yes Slave_SQL_Running: No Last_Errno: 1062 Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 0 failed executing transaction '7b389a77-4423-11e6-8e6b-00163ec0a235:10' at master log mysql-bin-3306.000002, end_log_pos 1865. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
GTID的复制对于错误信息的可读性不好,不过可以通过错误代码(1062)或监控表(replication_applier_status_by_worker)查看:
mysql> select * from performance_schema.replication_applier_status_by_worker where LAST_ERROR_NUMBER=1062\G *************************** 1. row *************************** CHANNEL_NAME: WORKER_ID: 1 THREAD_ID: NULL SERVICE_STATE: OFF LAST_SEEN_TRANSACTION: 7b389a77-4423-11e6-8e6b-00163ec0a235:10 #出现错误的GTID LAST_ERROR_NUMBER: 1062 LAST_ERROR_MESSAGE: Worker 0 failed executing transaction '7b389a77-4423-11e6-8e6b-00163ec0a235:10' at master log mysql-bin-3306.000002, end_log_pos 1865; Error 'Duplicate entry '1' for key 'uk_id'' on query. Default database: 'dba_test'. Query: 'insert into gtid values(1,'ABC')' LAST_ERROR_TIMESTAMP: 2016-07-28 13:21:48
可以看到具体SQL的报错信息。那如何跳过错误信息呢?开启GTID不能使用sql_slave_skip_counter跳过错误:
ERROR 1858 (HY000): sql_slave_skip_counter can not be set when the server is running with @@GLOBAL.GTID_MODE = ON. Instead, for each transaction that you want to skip, generate an empty transaction with the same GTID as the transaction
使用GTID跳过错误的方法:找到错误的GTID跳过(通过Exec_Master_Log_Pos去binlog里找GTID,或则通过上面监控表找到GTID,也可以通过Executed_Gtid_Set算出GTID),这里使用监控表来找到错误的GTID。找到GTID之后,跳过错误的步骤:
mysql> stop slave; #停止同步 Query OK, 0 rows affected (0.02 sec) mysql> set @@session.gtid_next='7b389a77-4423-11e6-8e6b-00163ec0a235:10'; #跳过错误的GTID,可以不用session,用session的目的是规范 Query OK, 0 rows affected (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) #提交一个空事务,因为设置gtid_next后,gtid的生命周期就开始了,必须通过显性的提交一个事务来结束,否则报错:ERROR 1790 (HY000): @@SESSION.GTID_NEXT cannot be changed by a client that owns a GTID.
mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> set @@session.gtid_next=automatic; #设置回自动模式 Query OK, 0 rows affected (0.00 sec) mysql> start slave; Query OK, 0 rows affected (0.02 sec)
2)gtid_purged(IO线程报错):事务被purge之后再进行change的场景。
Master: mysql> show master logs; +-----------------------+-----------+ | Log_name | File_size | +-----------------------+-----------+ | mysql-bin-3306.000001 | 983 | | mysql-bin-3306.000002 | 836 | | mysql-bin-3306.000003 | 685 | +-----------------------+-----------+ 3 rows in set (0.00 sec) mysql> purge binary logs to 'mysql-bin-3306.000003'; Query OK, 0 rows affected (0.09 sec) mysql> show master logs; +-----------------------+-----------+ | Log_name | File_size | +-----------------------+-----------+ | mysql-bin-3306.000003 | 685 | +-----------------------+-----------+ 1 row in set (0.00 sec) Slave: mysql> CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1; Query OK, 0 rows affected, 2 warnings (0.32 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec) mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Slave_IO_Running: No Slave_SQL_Running: Yes Last_IO_Errno: 1236 Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
因为是IO线程报错,通过监控表等上面说的方法看不到GTID信息,但错误信息提示的意思是主使用了purge binary log,导致复制失败。因为通过GTID的复制都是没有指定MASTER_LOG_FILE和MASTER_LOG_POS的,所以通过GTID复制都是从最先开始的事务开始,而最开始的binlog被purge了,导致报错。解决办法:
#在主上执行,查看被purge的GTID: mysql> show variables like 'gtid_purged'; +---------------+------------------------------------------+ | Variable_name | Value | +---------------+------------------------------------------+ | gtid_purged | 7b389a77-4423-11e6-8e6b-00163ec0a235:1-5 | +---------------+------------------------------------------+
#在从上执行: mysql> stop slave; Query OK, 0 rows affected (0.00 sec) mysql> set global gtid_purged='7b389a77-4423-11e6-8e6b-00163ec0a235:1-5'; #设置和主一样的purge Query OK, 0 rows affected (0.01 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec) mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Slave_IO_Running: Yes Slave_SQL_Running: Yes
关于gtid_purge还有一个场景,就是新建(还原)一个从库(把主库备份还原到新的从库):
1:主库执行备份: root@t22:~# mysqldump -uroot -p123 --default-character-set=utf8 --master-data=2 --set-gtid-purged=ON dba_test > dba_test.sql 2:检查目标实例(新从库)是否有GTID的脏数据: mysql> select * from mysql.gtid_executed; ##是否有数据 mysql> show variables like 'gtid_purged'; ##是否有值 3:如果上面的查询都是空的,表示该实例Gtid还没被使用,可以直接还原。若上面的查询结果是有数据库的,则需要在该实例上执行: mysql> reset master; #执行到上面的查询不到结果,再接下去执行。若是多源复制,需要先执行stop slave,再reset master 4:还原数据: root@t23:~# mysql -uroot -p123 --default-character-set=utf8 dba_test <dba_test.sql 要是第2步查出来GTID是有脏数据的话,还原会报错: ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty. 5:change同步: CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1;
3)Gtid和多源复制应用测试
上面已经介绍了基于binlog和position的老版复制,现在在这个基础上加上GTID,看看会有什么问题。
CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1 FOR CHANNEL 't22'; CHANGE MASTER TO MASTER_HOST='10.0.3.162',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1 FOR CHANNEL 't21'; CHANGE MASTER TO MASTER_HOST='10.0.3.219',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1 FOR CHANNEL 't23'; 因为channel t10是MySQL5.5版本,不支持GTID功能,而从库开启了GTID的功能,所以在开启GTID的情况下,MySQL5.5到MySQL5.7的复制是建立不起来的
补充:主从要么都开启GTID,要么都关闭GTID,开启任意一个会报错,复制不成功。
基于GTID的多源复制如何跳过某个channel的错误?因为每个MySQL实例的GTID都不一样,所以直接用gtid_next来跳过具体错误的gtid就行了,不需要纠结到底是哪个channel了。具体跳过错误的步骤和上面错误跳过和异常处理里的方法一致。下面是多源复制的接收执行的信息:(1从3主,要是从库开启了binlog,则在executed_gtid_set里会有4行)
Retrieved_Gtid_Set: 3b8ec9cb-4424-11e6-9780-00163e7a3d5a:1-11 Executed_Gtid_Set: 3b8ec9cb-4424-11e6-9780-00163e7a3d5a:1-11, 7a9582ef-382e-11e6-8136-00163edc69ec:1-4, 7b389a77-4423-11e6-8e6b-00163ec0a235:1-6
注意:因为是多源复制,所以从上的mysql.gtid_executed和gtid_purged看到有多行信息:
mysql> show variables like '%gtid_purged%'\G *************************** 1. row *************************** Variable_name: gtid_purged Value: 3b8ec9cb-4424-11e6-9780-00163e7a3d5a:1-18, 7a9582ef-382e-11e6-8136-00163edc69ec:10-12, 7b389a77-4423-11e6-8e6b-00163ec0a235:12-13 1 row in set (0.00 sec) mysql> select * from mysql.gtid_executed; +--------------------------------------+----------------+--------------+ | source_uuid | interval_start | interval_end | +--------------------------------------+----------------+--------------+ | 3b8ec9cb-4424-11e6-9780-00163e7a3d5a | 1 | 14 | | 3b8ec9cb-4424-11e6-9780-00163e7a3d5a | 15 | 15 | | 3b8ec9cb-4424-11e6-9780-00163e7a3d5a | 16 | 16 | | 3b8ec9cb-4424-11e6-9780-00163e7a3d5a | 17 | 17 | | 3b8ec9cb-4424-11e6-9780-00163e7a3d5a | 18 | 18 | | 7a9582ef-382e-11e6-8136-00163edc69ec | 10 | 10 | | 7a9582ef-382e-11e6-8136-00163edc69ec | 11 | 11 | | 7a9582ef-382e-11e6-8136-00163edc69ec | 12 | 12 | | 7b389a77-4423-11e6-8e6b-00163ec0a235 | 12 | 12 | | 7b389a77-4423-11e6-8e6b-00163ec0a235 | 13 | 13 | +--------------------------------------+----------------+--------------+
所以再新建(还原)一个channel的从库(mysqldump下来),需要保证上面2个变量没有数据(保证GTID信息干净),也需要执行
mysql> reset master;
但是由于其他channel的从库一直有数据写入,会导致mysql.gtid_executed和gtid_purged一直有数据。所以需要停止所有从库同步再清理gtid:
mysql> stop slave; #停止所有库的同步,防止GTID变量数据有数据。 Query OK, 0 rows affected (0.05 sec) mysql> reset master; #清理gtid信息 Query OK, 0 rows affected (0.00 sec) mysql> show variables like '%gtid_purged%'\G *************************** 1. row *************************** Variable_name: gtid_purged Value: 1 row in set (0.00 sec) mysql> select * from mysql.gtid_executed; Empty set (0.00 sec)
最后还原,建立一个新的channel从库:
root@t24:~# mysql -uroot -p123 t23 < t23.sql mysql> CHANGE MASTER TO MASTER_HOST='10.0.3.219',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_AUTO_POSITION=1 FOR CHANNEL 't23';
注意:主从复制的实例版本最好是同一个大版本,如:主从都是5.7。若主是5.6,从是5.7的话,可能会出现意想不到的bug。因为老版本(5.6)对于有些event没有记录并行复制的信息,对于开启并行复制的从(5.7)会报错:
Slave_IO_Running: Yes Slave_SQL_Running: No Last_SQL_Errno: 1755 Last_SQL_Error: Cannot execute the current event group in the parallel mode. Encountered event Gtid, relay-log name ./mysqld-relay-bin-demo_clinic.000004, position 3204513 which prevents execution of this event group in parallel mode. Reason: The master event is logically timestamped incorrectly..
上面这个解决办法就是(bug页面也提到了)让slave设置不并行复制:
stop slave; #关闭 set global slave_parallel_workers =0; #设置不并行 start slave; #开启
要是多源从库的话,则需要:
mysql> stop slave for channel 'xx'; #先关闭出错的channel的复制 mysql> set global slave_parallel_workers=0; #设置成单线程复制,只对stop slave之后设置的channel有效,因为没有stop的channel线程一直在连接(不受影响) Query OK, 0 rows affected (0.00 sec) mysql> start slave for channel 'xx'; #开启复制
在下面图标记出来的地方看出:其中的一个channel从库是单线程复制,其他channel都是多线程复制。

当然这报错也可以直接用上面介绍的gtid_next跳过和重新change master来解决,但这只是治标不治本的做法。
...
5,半同步复制增强
MySQL默认的复制都是异步的,在服务器崩溃时丢失事务是使用异步复制不可避免的结果。而5.5之后推出的一项新功能:半同步复制,可以限制事务丢失的数量。关于MySQL5.5/5.6的半同步复制可以看初识 MySQL 5.5、5.6 半同步复制,现在说明下MySQL5.7在5.6/5.5的基础上增强了几点功能:
1)无数据丢失
MySQL5.6/5.5半同步复制的原理:提交事务的线程会被锁定,直到至少一个Slave收到这个事务,由于事务在被提交到存储引擎之后才被发送到Slave上,所以事务的丢失数量可以下降到最多每线程一个。因为事务是在被提交之后才发送给Slave的,当Slave没有接收成功,并且Master挂了,会导致主从不一致:主有数据,从没有数据。如下面的情况:(AFTER_COMMIT)
客户端执行一个事务,master接收到之后提交后并把事务发送给slave,在发送的期间网络出现波动,但要等待slave把binlog写到本地的relay-log,然后给master一个返回信息,等待以rpl_semi_sync_master_timeout参数设置的超时为准(默认为10秒)响应。在这等待的10秒里,其他会话查可以看到Master上的事务,此时一旦master发生宕机,由于事务没有发送给slave,而master已经提交了,导致数据不一致。 例子: A客户端执行的事务将字段Z从0修改为1。 1.A提交事务到master 2.master写binlog 3.master commit事务到存储引擎,再把事务发送给slave 4.master commit成功了! 说明:此时还未收到slave确认,A还在等待slave的响应,但是另外客户端B已经可以看到字段Z为1了。假如此时master崩溃,如果slave实际收到刚才的事务仅仅是master未收到确认,那么此时slave的数据还是正确的也是Z=1,客户端切换到slave后,都看到Z=1,但是如果slave没有实际收到刚才的事务,那么此时slave上的z=0,导致主从数据不一直。
MySQL5.7在Master事务提交的时间方面做了改进(rpl_semi_sync_master_wait_point:AFTER_COMMIT\AFTER_SYNC),事务是在提交之前发送给Slave(默认,after_sync),当Slave没有接收成功,并且Master宕机了,不会导致主从不一致,因为此时主还没有提交,所以主从都没有数据。MySQL5.7也支持和MySQL5.5\5.6一样的机制:事务提交之后再发给Slave(after_commit)。如下面的情况:(AFTER_SYNC)
客户端执行一个事务,master接收到之后就把事务发送给slave,slave收到事务之后,然后给master一个返回信息,master再提交事务。在slave返回信息的时间里(以rpl_semi_sync_master_timeout参数为准,默认为10秒),其他会话查看不到Master上的最新事务,因为master都还没提交事务,此时一旦master发生宕机,由于事务没有发送给slave,并且master也没有提交数据,主从数据都没有更改,所以不会出现数据不一致。 例子: A客户端执行的事务讲字段Z从0修改为1。
1.A提交事务到master 2.master写binlog
3.master发送事务给slave,不提交! 4.master等待slave确认 此时z=0,没有任何客户端能看到z=1的结果,因为master还没提交。 5.master收到slave确认,master开始commit到存储引擎 6.master commit成功了!master返回结果给客户端 说明:假如第4步时master崩溃,客户端切换到slave,如果slave接收到事务,并响应master,那么此时主从的z=1,如果slave未接收到事务和响应,那么此时z=0,无论哪种状态,对于所有客户端数据库都是一致,事务都没有丢失。
参数rpl_semi_sync_master_wait_point:该参数控制半同步复制在哪个点(提交后再等待响应还是响应后再提交)等待slave的响应,默认AFTER_SYNC(slave响应后再提交),可选值有AFTER_COMMIT(提交后再等待响应)。
after_commit:master把每一个事务写到二进制日志并保存到磁盘上,并且提交(commit)事务,再把事务发送给从库,开始等待slave的应答。响应后master返回结果给客户端,客户端才可继续。
after_sync :master把每一个事务写到二进制日志并保存磁盘上,并且把事务发送给从库,开始等待slave的应答。确认slave响应后,再提交(commit)事务到存储引擎,并返回结果给客户端,客户端才可继续。
总之,MySQL5.7是在Master收到Slave应答之后才Commit事务,MySQL5.6/5.5是在Master Commit之后才等待Slave的应答。MySQL5.7半同步的好处就是在确认事务复制到Slave之前,并发的其他线程看不到当前事务的数据。当Master故障时,要么提交的事务已经复制到Slave,要么全部都没提交,这样就保证了数据的一致性,推荐阅读MySQL 5.7 深度解析: 半同步复制技术。
2)更快的半同步复制。
MySQL5.5/5.6的半同步复制是一个单工通讯方式,master把事务发送完毕后,要接收和处理slave的应答,处理完应答之后才能继续发送下一个事务,示意图如下:
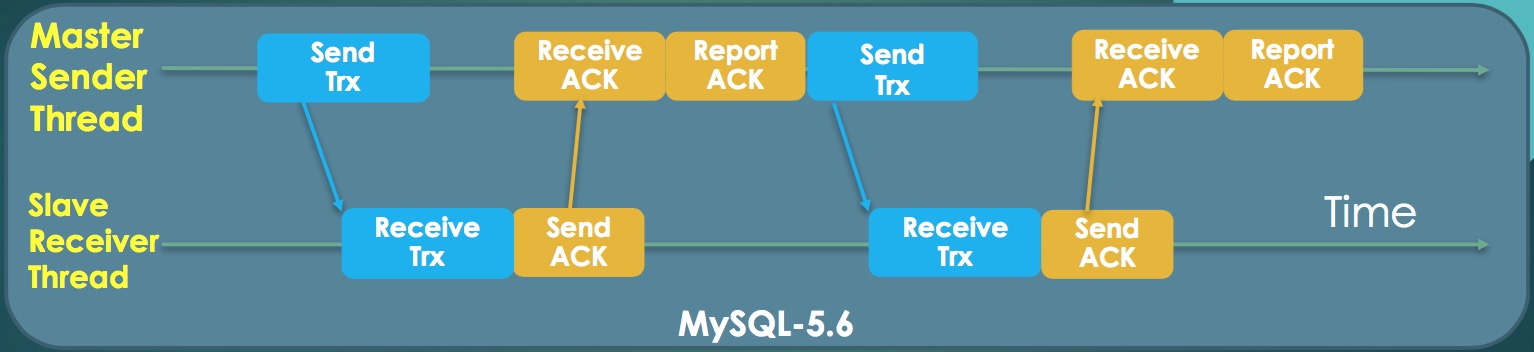
MySQL5.7的半同步复制创建了单独的应答接收线程,变成了双工模式,发送和接收互不影响。因为有了相应的线程处理,发送效率得到大幅提升,相比MySQL5.5/5.6延迟会小很多,性能得到大幅提升。示意图如下:
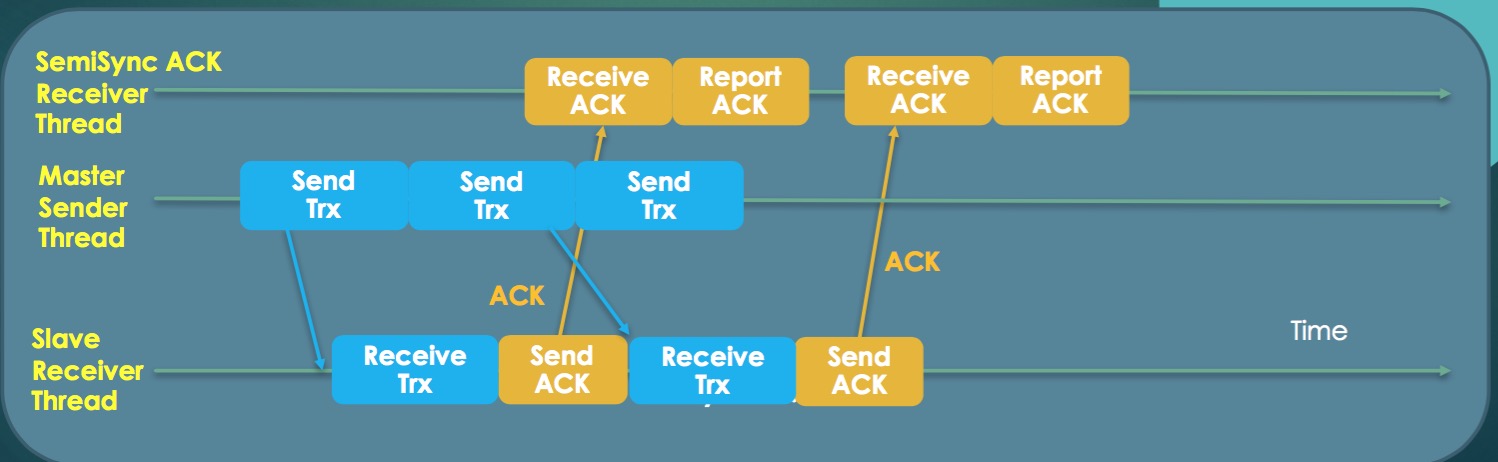
注意:MySQL5.7单独的应答接收线程在开启半同步复制的时候默认就创建了,不需要额外的设置。
3)等待多个Slave应答。
在半同步复制中,Master发送事务默认至少有一个Slave得到响应才能继续下一个事务。MySQL5.7之后用户可以设置应答的Slave数量,并且可以通过参数rpl_semi_sync_master_wait_for_slave_count:该变量控制slave应答的数量,默认是1,表示master接收到几个slave应答后才commit。在多从的环境下,设置大于1可以提高数据的可靠性。
如何建立半同步复制:可以看官方文档或则之前写的初识 MySQL 5.5、5.6 半同步复制
主上执行: mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; Query OK, 0 rows affected (0.07 sec) mysql> SET GLOBAL rpl_semi_sync_master_enabled=1; Query OK, 0 rows affected (0.00 sec) 为了保证重启后继续生效,需要在配置文件里加入:rpl_semi_sync_master_enabled = 1 从上执行: mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; Query OK, 0 rows affected (0.04 sec) mysql> SET GLOBAL rpl_semi_sync_slave_enabled = 1; Query OK, 0 rows affected (0.00 sec) 为了保证重启后继续生效,需要在配置文件里加入:rpl_semi_sync_slave_enabled = 1 开启复制:设置好半同步复制的插件和开启半同步功能之后,复制模式就默认用半同步了 mysql> CHANGE MASTER TO MASTER_HOST='10.0.3.141',MASTER_USER='repl',MASTER_PASSWORD='Repl_123456',MASTER_LOG_FILE='mysql-bin-3306.000001',MASTER_LOG_POS=154; Query OK, 0 rows affected, 2 warnings (0.30 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec) 开启成功后,slave的error log里会出现:半同步复制是跟 IO_THREAD 有直接关系,跟 SQL_THREAD 没关系。也就是说SLAVE 从库接收完二进制日志后给 master 主库一个确认,并不管relay-log中继日志是否正确执行完。即使SQL线程报错了,半同步复制还是不会切换成异步复制 [Note] Slave I/O thread: Start semi-sync replication to master 'repl@10.0.3.141:3306' in log 'mysql-bin-3306.000001' at position 154
如何监控半同步复制:可以看官方文档或则之前写的初识 MySQL 5.5、5.6 半同步复制
主上: mysql> show variables like 'rpl_semi%'; +-------------------------------------------+------------+ | Variable_name | Value | +-------------------------------------------+------------+ | rpl_semi_sync_master_enabled | ON | | rpl_semi_sync_master_timeout | 10000 | | rpl_semi_sync_master_trace_level | 32 | | rpl_semi_sync_master_wait_for_slave_count | 1 | | rpl_semi_sync_master_wait_no_slave | ON | | rpl_semi_sync_master_wait_point | AFTER_SYNC | +-------------------------------------------+------------+ 6 rows in set (0.00 sec) mysql> show global status like 'rpl_semi%'; +--------------------------------------------+-------+ | Variable_name | Value | +--------------------------------------------+-------+ | Rpl_semi_sync_master_clients | 1 | | Rpl_semi_sync_master_net_avg_wait_time | 0 | | Rpl_semi_sync_master_net_wait_time | 0 | | Rpl_semi_sync_master_net_waits | 0 | | Rpl_semi_sync_master_no_times | 0 | | Rpl_semi_sync_master_no_tx | 0 | | Rpl_semi_sync_master_status | ON | | Rpl_semi_sync_master_timefunc_failures | 0 | | Rpl_semi_sync_master_tx_avg_wait_time | 0 | | Rpl_semi_sync_master_tx_wait_time | 0 | | Rpl_semi_sync_master_tx_waits | 0 | | Rpl_semi_sync_master_wait_pos_backtraverse | 0 | | Rpl_semi_sync_master_wait_sessions | 0 | | Rpl_semi_sync_master_yes_tx | 0 | +--------------------------------------------+-------+ 14 rows in set (0.00 sec) 从上: mysql> show variables like 'rpl_semi%'; +---------------------------------+-------+ | Variable_name | Value | +---------------------------------+-------+ | rpl_semi_sync_slave_enabled | ON | | rpl_semi_sync_slave_trace_level | 32 | +---------------------------------+-------+ 2 rows in set (0.00 sec) mysql> show global status like 'rpl_semi%'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Rpl_semi_sync_slave_status | ON | +----------------------------+-------+ 1 row in set (0.00 sec)
半同步成功开启之后,在主上show processlist可以看到:
Waiting for semi-sync ACK from slave;
针对上面的参数和变量说明:
主上: rpl_semi_sync_master_enabled:表示主上是否开启半同步复制功能,可以动态修改。可选值:ON\OFF rpl_semi_sync_master_timeout:为了防止半同步复制中主在没有收到S发出的确认发生堵塞,用来设置超时,超过这个时间值没有收到信息,则切换到异步复制,执行操作。默认为10000毫秒,等于10秒,这个参数动态可调,表示主库在某次事务中,如果等待时间超过10秒,那么则降级为异步复制模式,不再等待SLAVE从库。如果主库再次探测到,SLAVE从库恢复了,则会自动再次回到半同步复制模式。可以设置成1000,即1秒。 rpl_semi_sync_master_wait_for_slave_count:控制slave应答的数量,默认是1,表示master接收到几个slave应答后才commit。 rpl_semi_sync_master_wait_no_slave :当一个事务被提交,但是Master没有Slave连接,这时M不可能收到任何确认信息,但M会在时间限制范围内继续等待。如果没有Slave链接,会切换到异步复制。是否允许master每个事务提交后都要等待slave的接收确认信号。默认为on,每一个事务都会等待。如果为off,则slave追赶上后,也不会开启半同步复制模式,需要手工开启。 rpl_semi_sync_master_wait_point:该参数表示半同步复制的主在哪个点等待从的响应,默认AFTER_SYNC,在得到slave的应答后再commit,可选值AFTER_COMMIT。 从上: rpl_semi_sync_slave_enabled:表示从上是否开启半同步复制功能,可以动态修改。可选值:ON\OFF
Rpl_semi_sync_master_clients :说明支持和注册半同步复制的已连Slave数。
Rpl_semi_sync_master_net_avg_wait_time :master等待slave回复的平均等待时间,单位毫秒。
Rpl_semi_sync_master_net_wait_time :master总的等待时间。
Rpl_semi_sync_master_net_waits :master等待slave回复的的总的等待次数,即半同步复制的总次数,不管失败还是成功,不算半同步失败后的异步复制。
Rpl_semi_sync_master_no_times :master关闭半同步复制的次数。
Rpl_semi_sync_master_no_tx :master没有收到slave的回复而提交的次数,可以理解为master等待超时的次数,即半同步模式不成功提交数量。
Rpl_semi_sync_master_status :ON是活动状态(半同步),OFF是非活动状态(异步),用于表示主服务器使用的是异步复制模式,还是半同步复制模式。
Rpl_semi_sync_slave_status :Slave上的半同步复制状态,ON表示已经被启用,OFF表示非活动状态。
Rpl_semi_sync_master_tx_avg_wait_time :master花在每个事务上的平均等待时间。
Rpl_semi_sync_master_tx_wait_time :master总的等待时间。
Rpl_semi_sync_master_tx_waits :master等待成功的次数,即master没有等待超时的次数,也就是成功提交的次数
Rpl_semi_sync_master_wait_pos_backtraverse :master提交后来的先到了,而先来的还没有到的次数。
Rpl_semi_sync_master_wait_sessions :前有多少个session因为slave的回复而造成等待。
Rpl_semi_sync_master_yes_tx :master成功接收到slave的回复的次数,即半同步模式成功提交数量。
总之,关于半同步复制的测试说明可以看初识 MySQL 5.5、5.6 半同步复制这篇文章。半同步复制的好处:半同步复制可以有效的限制事务丢失的数量,更好的保证数据的安全和一致性;半同步复制的坏处:更新、插入、删除的速度要比异步复制要慢,因为多了一个"从返回信息给主"的步骤。要是出现异常:网络问题或则数据库问题,半同步复制和异步复制就会来回切换,导致主库的更新、插入、删除操作会受到影响。
...
总结:
本文从MySQL5.7的多源复制、基于组提交的并行复制、在线修改Replication Filter、GTID增强、半同步复制增强等比较常用的replication的特性进行了简单介绍和说明,后面会持续更新有遗漏的部分。可以看到MySQL5.7比之前的版本在复制上有了很大的提升,增加了不少功能。到现在为止,大致对MySQL5.7的相关特性方面进行了介绍:新增配置参数、安全相关特性、功能性能的提升,后面还会再介绍说明下MySQL5.7新增的sys库和innodb的N-gram分词。
参考文档
