
Python下Tesseract Ocr引擎及安装介绍
1、Tesseract介绍
tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码可以在这里下载。
实际使用tesseract ocr也有两种方式:1- 动态库方式 libtesseract 2 - 执行程序方式 tesseract.exe
由于本人也是python菜鸟一个,所以方式1暂时不会,只好采取方式2。
2、Tesseract安装包下载
Tesseract的release版本下载地址:https://github.com/tesseract-ocr/tesseract/wiki/Downloads,这里需要注意这一段话:
Currently, there is no official Windows installer for newer versions.
意思就是官方不提供最新版windows平台安装包,只有相对略老的3.02.02版本,其下载地址:https://sourceforge.net/projects/tesseract-ocr-alt/files/。
最新版3.03和3.05版本,都是三方维护和管理的安装包,有好几个发行机构,分别是:
3rd party Windows exe's/installer
-
binaries compiled by @egorpugin (ref issue # 209)https://www.dropbox.com/s/8t54mz39i58qslh/tesseract-3.05.00dev-win32-vc19.zip?dl=1
You have to install VC2015 x86 redist from microsoft.com in order to run them. Leptonica is built with all libs except for libjp2k.
- http://domasofan.spdns.eu/tesseract/
总结一下:
2、德国曼海姆大学发行的3.05版本下载地址,http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.00dev.exe
3、Simon Eigeldinger (@DomasoFan) 维护的另一个版本:http://3.onj.me/tesseract/,值得称道的是,这个网址里还有一个比较详细的说明。
以上版本如果在下载时发现无法下载,可以首先试试迅雷,其次,可能就需要FQ了。
本人使用的是官方发布的3.02版本,也就是链接1.
3、Tesseract ocr使用说明
安装之后,默认目录C:\Program Files (x86)\Tesseract-OCR,你需要把这个路径放到你操作系统的path搜索路径中,否则后面使用起来会不方便。
在安装目录C:\Program Files (x86)\Tesseract-OCR下可以看到 tesseract.exe这个命令行执行程序。
tesseract语法如下:
例如:tesseract 1.png output-l eng -psm 7 ,表示采取单行文本方式,使用英语字库识别1.png这个图片文件,识别结果输出到当前目录output.txt文件中。
1 D:\python\lnypcg\test>tesseract 2 Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...] 3 4 pagesegmode values are: 5 0 = Orientation and script detection (OSD) only. 6 1 = Automatic page segmentation with OSD. 7 2 = Automatic page segmentation, but no OSD, or OCR 8 3 = Fully automatic page segmentation, but no OSD. (Default) 9 4 = Assume a single column of text of variable sizes. 10 5 = Assume a single uniform block of vertically aligned text. 11 6 = Assume a single uniform block of text. 12 7 = Treat the image as a single text line. #-psm 7 表示用单行文本识别 13 8 = Treat the image as a single word. 14 9 = Treat the image as a single word in a circle. 15 10 = Treat the image as a single character. 16 -l lang and/or -psm pagesegmode must occur before anyconfigfile. #-l eng 代表使用英语识别 17 18 Single options: 19 -v --version: version info 20 --list-langs: list available languages for tesseract engine
4、Tesseract ocr使用实例
现在有一个经过灰度处理之后的验证码文件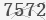 ,在命令行中调用tesseract.exe实现默认,并把识别出来的文本输出到output.txt文本文件中。
,在命令行中调用tesseract.exe实现默认,并把识别出来的文本输出到output.txt文本文件中。
(如何灰度处理,在python里可以使用PIL库,先挖个坑,下次写。)
1 D:\python\lnypcg\test>dir 2 驱动器 D 中的卷没有标签。 3 卷的序列号是 36D9-CDC7 4 5 D:\python\lnypcg\test 的目录 6 7 2016-06-02 23:28 <DIR> . 8 2016-06-02 23:28 <DIR> .. 9 2016-06-02 22:02 462 1.png 10 1 个文件 462 字节 11 2 个目录 25,733,357,568 可用字节 12 13 D:\python\lnypcg\test>tesseract 1.png output -l eng 14 Tesseract Open Source OCR Engine v3.02 with Leptonica 15 16 D:\python\lnypcg\test>type output.txt 17 7572 18 19 20 D:\python\lnypcg\test>
总结,tesseract是一个挺不错的OCR引擎,目前的问题是最新的中文资料相对较少,过时、不准确的信息偏多,把这几天的琢磨的结果分享给大家,希望对大家有所帮助。
