

(1)在文章开头给出Github项目地址。(1')
项目地址:https://github.com/JerryYouxin/sudoku
(2)在开始实现程序之前,在下述PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(0.5')
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1020 | 1540 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 120 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 60 | 90 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 50 | 80 |
| · Test Report | · 测试报告 | 50 | 100 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan · | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1215 | 1770 |
(3)看教科书和其它资料中关于Information Hiding, Interface Design, Loose Coupling的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。(5')
信息隐藏,对于面向对象的程序设计而言,信息隐藏对于将对象封装,避免外来操作对其进行盲目乃至错误的操作,在具体实施上主要是通过只提供接口读入和得到结果,避免其中的具体实现的过程对外暴露,从而导致不安全的访问。我们在合作代码的时候,尽量只给互相提供相互之间所需要的接口,避免因为看到内部代码而导致的过度操作,以提高程序的安全性与健壮性。
interface design 和loose coupling实际上在很大程度上提高了我们工作的效率。这两者都使我们能够专注于自身所要完成的那一部分代码中,使得个人的工作具体化,简单化,而不要求我们必须具有着眼整个完整项目的能力,也避免了我们在拥有这种能力之前过于好高骛远或者不敢下手,从而浪费时间,松耦合和接口设计使得我们能够专心做好自己的事情,不必过度分心从而导致的效率下降,同时,只提供接口和松耦合的方式也使得我们彼此的代码不互相干扰,从而导致双方共同的困难。
4)计算模块接口的设计与实现过程
计算模块接口的设计与实现过程
计算模块接口如下(Core类中的成员函数):
void generate(int number,int mode,int result[][81]);
void generate(int number,int lower,int upper,bool unique,int result[][81]);
void generate(int number,int result[][81]); // generate final states
bool solve(int puzzle[],int solution[]);
void solve(int number,int *puzzle,int *solution);
int read_sudoku(int **puzzle,const char* filename);
int write_sudoku(int number,int *puzzle,const char* filename);
bool check_valid(int *solution);
int check_valid(int number,int *solution);
bool check_same(int number,int *solution);
其中generate(int number, int result)用回溯法进行终局的搜索(可以参考我的个人项目的博客)。在实现生成只有唯一解的数独时,先用上述终局生成函数生成数独终局,再进行挖空,每次挖空后用解数独函数来求解数独,该函数可以返回数独解的数量,由此可以判断是否为唯一解。如果不是唯一解的数独则回溯不挖空,并再查看下一个空是否可以挖(这是一个递归)。代码如下:
bool Core::__generate_unique(int num, int maxNum, int index, int result[]) {
if(index>=81||maxNum<=num) return maxNum<=num;
int x = result[index];
result[index] = 0;
if(isUniqueSolve(result)) {
return __generate_unique(num+1,maxNum,index+1,result);
}
else {
result[index] = x;
return __generate_unique(num,maxNum,index+1,result);
}
}
void Core::generate(int number,int lower,int upper,bool unique,int result[][81]) {
if(number<1||number>10000) throw NumException();
if(lower>upper||lower<0||upper>64) throw RangeException();
if(unique) {
generate(number,result);
#pragma omp parallel for
for(int n=0;n<number;++n) {
int num = lower;//rand()%(upper-lower+1)+lower;
__generate_unique(0,num,0,result[n]);
}
} else {
generate(number,result);
for(int n=0;n<number;++n) {
int num = rand()%(upper-lower+1)+lower;
for(int i=0;i<81;++i) {
if(81-i+1<=num) {
result[n][i] = 0;
--num;
}
else {
double r = rand()/(double)RAND_MAX;
if(r<0.5) {
result[n][i] = 0;
--num;
}
}
}
}
}
}
在检查函数上,Core类提供了三个接口以供检查数独合法性等信息:
// check functions
bool check_valid(int *solution);
int check_valid(int number,int *solution);
bool check_same(int number,int *solution);
其中check_valid为检查输入数独是否为合法数独,即每个数字都是0~9之间的整数且符合数独的规则要求。如果是合法的bool check_valid(int)会返回true,int check_valid(int,int)会返回0,否则为非法数独。其中bool类型的需要保证输入的数独是只有一个的,且所有的函数输入都至少分配好足够的内存空间。
我实现了其中的-m生成部分。
我的-m生成难度的是基于挖的空的数量和空间自由度两个方面决定。
一般而言,肯定是挖空越多总体趋势上难度越大。
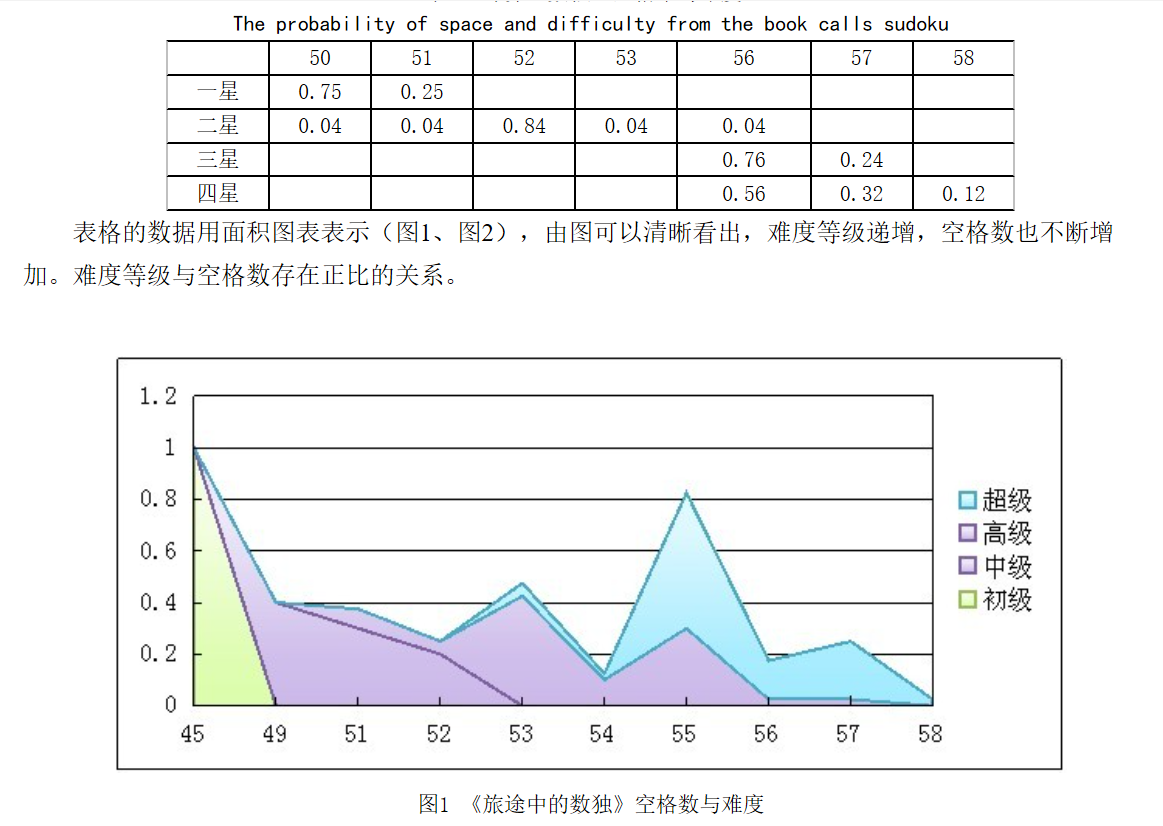
难度等级的增加,空格数总体趋势递增,不同难度等级的题目空格数也一样的情况。我们得出初步结论,简单按照空格的数目多少来划分数独题目的难易程度是不全面的。同样空格数的数独题目,空格数分布位置的不同对难度等级也造成影响。
在这种思维下,我们提出自由度的概念:,数独的难度等级与行、列、宫格内的空格数存在着联系。提出以空格自由度衡量数独的难度等级。数独的空格自由度,指除掉空格本身,空格所在行、列、九宫内的空格数总和。

我们通过这两个方面的思维,将空格从20到55分为3个区间,自由度从700到1300分为三个区间,难度的划分是只要一个条件达到了相应区间就可以认为达到了要求。
这样我们可以在第一次个人项目的基础上,随即进行挖空,直至满足了条件。
可以参考
http://www.cnblogs.com/candyhuang/archive/2011/12/21/2153668.html
(5)阅读有关UML的内容:https://en.wikipedia.org/wiki/Unified_Modeling_Language。画出UML图显示计算模块部分各个实体之间的关系(画一个图即可)。(2’)
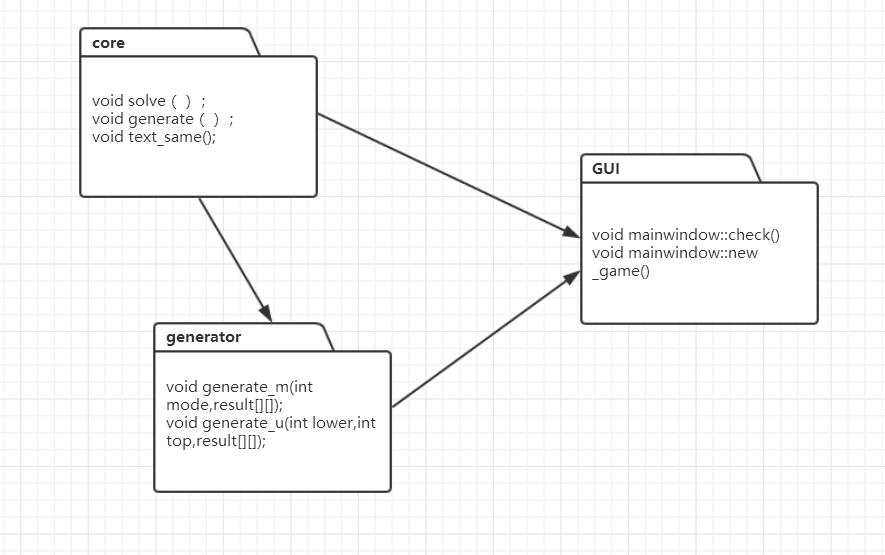
UML图
计算模块接口部分的性能改进
原来的回溯算法性能很低,所以在求解上,由个人项目时的回溯法改为了快速求解精确覆盖问题的DLX算法。但是在实现后却发现加速并不明显,甚至还有些慢。在最耗时间的生成唯一解的情况下,用VS性能分析后得到如下图:
[1]!(http://images2017.cnblogs.com/blog/1224149/201710/1224149-20171015145603137-289738865.png)
由于我截图的时候代码有些改动导致函数名并不能正常显示。图中最耗时间的是DLXSolver中的solve函数,由于查找唯一解时挖空是递归搜索,所以这是很正常的现象。但是注意到第二位的那个new函数,是分配空间的函数,这个耗时也很长,这是为什么?看看代码,发现在将数独问题转换为精准覆盖问题时会申请内存空间来建立双向十字链表来存储稀疏矩阵。由于原来的实现为一个节点一个节点进行内存分配,所以只要改为刚开始统一分配好一批节点后,后面按需所配即可。改进后速度有了大大提高.
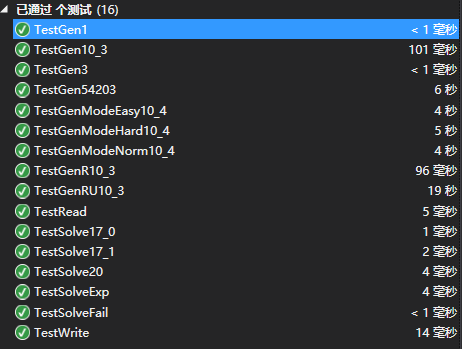
计算模块部分单元测试展示
单元测试思路为每个主要的函数都进行测试。I/O操作的单元测试,其中refRes是一个合法的数独数组:
TEST_METHOD(TestRead)
{
Core core;
int refRes[]={
...
};
int* result;
core.read_sudoku(&result,"sudokuexp.txt");
for(int i=0;i<162;++i)
Assert::AreEqual(refRes[i],result[i]);
delete[] result;
}
TEST_METHOD(TestWrite)
{
Core core;
int refRes[]={
...
};
int* result;
core.write_sudoku(2,refRes,"sudoku.txt");
core.read_sudoku(&result,"sudoku.txt");
for(int i=0;i<162;++i)
Assert::AreEqual(refRes[i],result[i]);
delete[] result;
}
对于generate,对于每个不同大小的输入、不同类型的接口进行测试,并在最后调用检查函数check_valid和check_same来验证正确性。
TEST_METHOD(TestGen...)
{
Core core;
const int N = ...; // MAXIMUM
//int result[N][81];
int* result = new int[N*81];
core.generate(N,(int(*)[81])result);
Assert::AreEqual(core.check_valid(N,(int*)result),0);
Assert::IsTrue(core.check_same(N,(int*)result));
delete[] result;
}
Solve函数同样,读入测试数据后调用solve接口进行解题,然后用check_valid进行正确性检查。
TEST_METHOD(TestSolveExp)
{
Core core;
const int N = 2; // MAXIMUM
int* result = new int[N*81];
//int result[N][81];
int* puzzle;
core.read_sudoku(&puzzle,"sudokuexp.txt");
core.solve(N,puzzle,(int*)result);
Assert::AreEqual(core.check_valid(N,(int*)result),0);
Assert::IsTrue(core.check_same(N,(int*)result));
delete[] result;
delete[] puzzle;
}
单元测试结果如下:
(7)看Design by Contract, Code Contract的内容:
http://en.wikipedia.org/wiki/Design_by_contract
http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx
描述这些做法的优缺点, 说明你是如何把它们融入结对作业中的。(5')
这两种做法指的都是约定性地进行代码工作,两个人实现就两者要进行对接的函数的条件,参数条件(包括参数的取值范围,类型),各自明确在什么条件下,接受什么条件的指令,不满足条件的可以不接受,这种方式的优点在于能够更好地敦促双方按照实现的约定严格书写代码,提高的代码的鲁棒性和健壮性,有可能促成高水平工程的完成,但是缺点在于如果两个人水平有一定差距的话,不利于两个人更加方便地进行合作编程,会导致木桶效应的发生。
计算模块部分异常处理说明
计算模块异常有四类:RangeException,NumException,ModeException,InvalidSudokuException。每个异常都在函数刚开始进行参数检查时,如果参数异常则抛出相关异常。单元测试如下,以下面为例:
TEST_METHOD(TestInvalidSudokuException)
{
Core core;
const int N = 1; // MAXIMUM
int puzzle[] ={
9, 9, 8, 0, 6, 0, 1, 2, 4,
2, 3, 7, 4, 5, 1, 9, 6, 8,
1, 4, 6, 0, 2, 0, 3, 5, 7,
0, 1, 2, 0, 7, 0, 5, 9, 3,
0, 7, 3, 0, 1, 0, 4, 8, 2,
4, 8, 0, 0, 0, 5, 6, 0, 1,
7, 0, 4, 5, 9, 0, 8, 1, 6,
8, 1, 0, 7, 4, 6, 2, 0, 0,
3, 0, 5, 0, 8, 0, 7, 0, 9,
};
int result[81]={ 0 };
try {
Assert::IsFalse(core.check_valid(puzzle));
Assert::AreEqual(core.check_valid(1,puzzle),1);
core.solve(puzzle,(int*)result);
Assert::Fail();
}
catch(InvalidSudokuException e) {
}
}
(10)界面模块的详细设计过程。在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。(5')
首先是一个计时的工具,通过Qlabel来实现,在时间能够走得情况下(通过全局变量changable来控制),将time_show增长,并且将其的分钟数和秒数set到两个label的txt上面,就是先了记时的功能。

void MainWindow::time_change()
{
if(time_changable==true)
{
time_show++;
int minute=time_show/60;
int second=time_show%60;
char str1[3];
char str2[3];
sprintf(str1,"%02d",minute);
sprintf(str2,"%02d",second);
minute_->setText(str1);
second_->setText(str2);
}
接下来是各个控制按钮,它们的类型都是QPushButton,它们之间有一定的逻辑关系,比如在刚刚按下new_game按钮的时候,除了restart和new_game之外的按钮都是不能按下的,而一旦选择了数独中的按钮,那么根据选择的是原先就有的,新填上的还是现在为止还没有填上的,不同的按钮会分别转换为可选中和不可选中的状态,以下面的代码为例
void MainWindow::pause()
{
if(Pause->text().compare("Pause")==0)
{
time_changable=false;
for(int i=0;i<81;i++)
{
follow[i]->setEnabled(false);
}
for(int j=0;j<9;j++)
{
fillin[j]->setEnabled(false);
}
Remind_Me->setEnabled(false);
Check->setEnabled(false);
Wipe->setEnabled(false);
Pause->setText("Continue");
}
else
{
if(Pause->text().compare("Continue")==0)
{
time_changable=true;
for(int i=0;i<81;i++)
{
follow[i]->setEnabled(true);
}
Remind_Me->setEnabled(true);
Check->setEnabled(true);
Wipe->setEnabled(true);
Pause->setText("Pause");
}
}
for(int j=0;j<9;j++)
{
fillin[j]->setEnabled(false);
}
}
void MainWindow::wipe()
{
QString str1=last_button->objectName();
Wipe->setEnabled(false);
QString tmp;
for(int j = 0; j < str1.length(); j++)
{
if(str1[j] >= '0' && str1[j] <= '9')
tmp.append(str1[j]);
}
bool ok;
int index=tmp.toInt(&ok,10);
if((last_button->text().compare("")!=0)&&sudukuinto[index]==0)
{
follow[index]->setText("");
nowsuduku[index]=0;
}
for(int j=0;j<9;j++)
{
fillin[j]->setEnabled(false);
}
}
最后的成品大概是这样的,可以计时、选择难度、开新局,重新此局,删除填过的空。
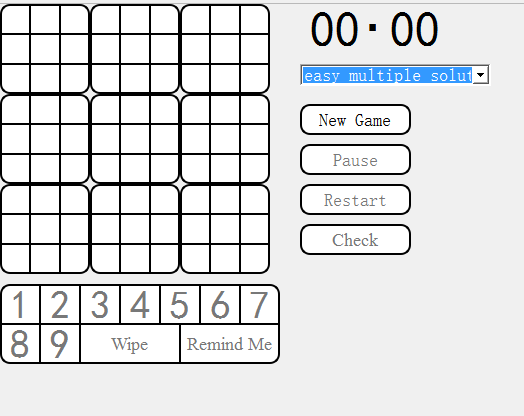
(11)界面模块与计算模块的对接。详细地描述UI模块的设计与两个模块的对接,并在博客中截图实现的功能。(4')
通过与难度生成(-m),求解的函数对接来实现UI模块求解的全过程。
void Core::generate(int number,int mode,int result[][81]) {
if(number<1||number>10000) throw NumException();
if(mode!=1&&mode!=2&&mode!=3) throw ModeException();
int i = 0;
int free_degree = 0;
int sudoku_num = 0;
int num = 0;
int the_time = 0;
int hollow_num = 0;
for (sudoku_num = 0; sudoku_num < number; sudoku_num++)
{
generate(1,(int(*)[81])result[sudoku_num]);
free_degree = 0;
num = 0;
if (mode == 1)
{
hollow_num=rand() % 9 + 40;
if (the_time == 0)
{
for (int ii = 0;; ii = ii + 2)
{
上面这部分是实现难度生成的代码,而这部分的代码通过什么样的方式与UI的工程相联系起来呢,主要是通过动态链接库所生成的代码库,UI通过调用来实现的。在UI的显示类中将core定义为其中的一个属性,然后通过调用生成和求解的方法将相应的结果返回到UI模块的一个变量result中,再通过UI的settext将其显示在图形界面上。
具体代码思想大概是这样:

private:
QPushButton *follow[81];
QPushButton *fillin[10];
QPushButton *Remind_Me;
QPushButton *Restart;
QPushButton *New_Game;
QPushButton *Check;
QPushButton *Pause;
QPushButton *Wipe;
QComboBox *choose_;
QLabel *minute_;
QLabel *second_;
Core core;
core.generate(1,diff,result[i]);
QString mode=ui->centralWidget->findChild<QComboBox*>("choose")->currentText();
bool a=false;
switch( QMessageBox::question(this, "begin a new game?",
"you choose "+mode+" ,are you sure"),
QMessageBox::Ok | QMessageBox::Cancel,QMessageBox::Ok )
(12)描述结对的过程,提供非摆拍的两人在讨论的结对照片。(1')

(13)看教科书和其它参考书,网站中关于结对编程的章节,例如:
http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html
说明结对编程的优点和缺点。
结对的每一个人的优点和缺点在哪里 (要列出至少三个优点和一个缺点)。(5')
结对编程的优点在于两个人之间可以互相合作着编程,可以避免很多平时个人编程中所出现的错误,但是因为结对编程必然要以一个人的代码为主要模板,这就导致另一个人在参与的过程中会有一些生疏和不习惯,比较多的时间都用来理解对方的代码,其次,则是合作编程在时间上有时候不太好掌握,有时候会导致进度不统一,一个人早做完而另一个一直在做的情况也可能出现。
同伴优点:代码能力出众,软工大佬;代码知识较为广泛,能够解决很多以前没有接触过方面的问题,大大加快了最后将前端和后端融合的进度;对于测试方面有足够的知识,对于程序的正确性方面做出了很大贡献。
缺点:缺乏足够合理的沟通导致进度不够统一,影响了效率。

