requirejs源码分析,使用注意要点
本文将深度剖析require.js代码,为了是大家更高效、正确的去使用它,本文不会介绍require的基本使用!
概要
先来一个流程图来概要一下大概流程
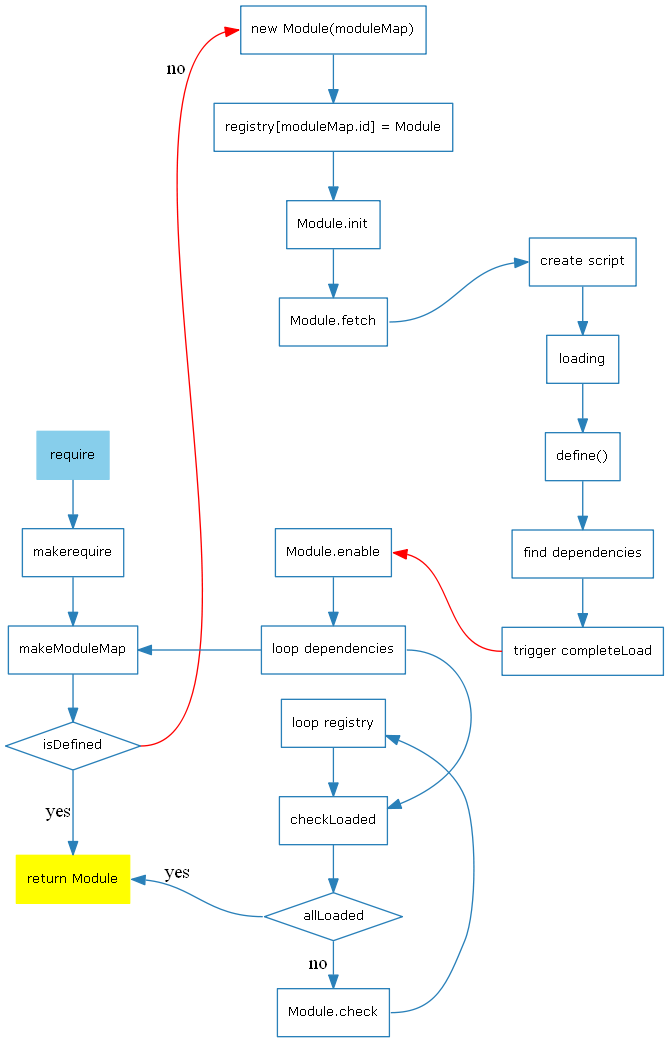
在require中,根据AMD(Asynchronous Module Definition)的思想,即异步模块加载机制,其思想就是把代码分为一个一个的模块来分块加载,这样无疑可以提高代码的重用。
在整个require中,主要的方法就两个:require和define,我们先来聊聊require
require
require作为主函数来引入我们的“模块”,require会从自身的的存储中去查找对应的defined模块,如果没有找到,则这时这个模块有可以存在三种状态:loading, enabling, defining,这里有可能就疑惑了,为什么还会有这么多状态呢?
这就是require中要注意的地方,如果模块还没有被加载,那么它的这三种状态出现的时机是:
- loading
文件还没有加载完毕 - enabling
对该模块的依赖进行加载和模块化 - defining
对正在处理的模块进行加载,并运行模块中的callback
有同学就问了,为什么会出现这么多的状态呢?js不是单线程操作吗?拿过来直接加载不就完了吗?哪来这么多事呢。而这就是require的神奇之处,我们先来瞅一瞅require的load方法的主要代码:
req.load = function (context, moduleName, url) {
var config = (context && context.config) || {},
node;
if (isBrowser) {
//create a async script element
node = req.createNode(config, moduleName, url);
//add Events [onreadystatechange,load,error]
.....
//set url for loading
node.src = url;
//insert script element to head and start load
currentlyAddingScript = node;
if (baseElement) {
head.insertBefore(node, baseElement);
} else {
head.appendChild(node);
}
currentlyAddingScript = null;
return node;
} else if (isWebWorker) {
.........
}
};
req.createNode = function (config, moduleName, url) {
var node = config.xhtml ?
document.createElementNS('http://www.w3.org/1999/xhtml', 'html:script') :
document.createElement('script');
node.type = config.scriptType || 'text/javascript';
node.charset = 'utf-8';
node.async = true;
return node;
};
rquire使用的是script标签去拿js,细心的同学会注意到node上设定了async属性(异步加载script标签),并且在标签上绑定了load等事件,当文件loading完成后,则要做的主要工作是执行completeLoad事件函数,但是要注意的是这时候把script加载完成后,立即执行的是script标签内部的内容,执行完后才触发的completeLoad事件,而在我们的模块里面,一定要用define函数来对模块进行定义,所以这里我们先穿插着来讲讲define干了什么
define乱入
define顾名思义是去定义一个模块,它只是单纯的去定义吗?错,我不会告诉你define做了你想象不到的最神奇的事情,来瞅瞅define的代码
define = function (name, deps, callback) {
var node,
context;
//do for multiple constructor
......
//If no name, and callback is a function, then figure out if it a
//CommonJS thing with dependencies.
if (!deps && isFunction(callback)) {
deps = [];
//Remove comments from the callback string,
//look for require calls, and pull them into the dependencies,
//but only if there are function args.
if (callback.length) {
callback
.toString()
.replace(commentRegExp, '')
.replace(cjsRequireRegExp, function (match, dep) {
deps.push(dep);
});
deps = (callback.length === 1 ? ['require'] : ['require', 'exports', 'module']).concat(deps);
}
}
//If in IE 6-8 and hit an anonymous define() call, do the interactive work.
if (useInteractive) {
node = currentlyAddingScript || getInteractiveScript();
if (node) {
if (!name) {
name = node.getAttribute('data-requiremodule');
}
context = contexts[node.getAttribute('data-requirecontext')];
}
}
//add to queue line
if (context) {
context.defQueue.push([name, deps, callback]);
context.defQueueMap[name] = true;
} else {
globalDefQueue.push([name, deps, callback]);
}
};
这就是define函数,代码不是很多,但是新奇的东西却是有一个!!!那就是代码中对callback.toString()文本来进行正则匹配,哇,这是什么鬼呢?我们看看这两个replace中的正则表达式是什么样的
commentRegExp = /(\/\*([\s\S]*?)\*\/|([^:]|^)\/\/(.*)$)/mg;
cjsRequireRegExp = /[^.]\s*require\s*\(\s*["']([^'"\s]+)["']\s*\)/g;
第一个正则是用来支掉callback中的注释的,而第二个正则是用来匹配callback.toString()文本中的require(.....),并将.....这个字段push到queue中,这个方法是不是很变态?现在让我们来接着回到require的completeLoad函数
require回归
rquire的compeleteLoad函数又做了什么呢?二话不说,扔一段代码来看看:
completeLoad : function (moduleName) {
var found,
args,
mod,
shim = getOwn(config.shim, moduleName) || {},
shExports = shim.exports;
takeGlobalQueue();
while (defQueue.length) {
args = defQueue.shift();
if (args[0] === null) {
args[0] = moduleName;
//If already found an anonymous module and bound it
//to this name, then this is some other anon module
//waiting for its completeLoad to fire.
if (found) {
break;
}
found = true;
} else if (args[0] === moduleName) {
//Found matching define call for this script!
found = true;
}
callGetModule(args);
}
context.defQueueMap = {};
//Do this after the cycle of callGetModule in case the result
//of those calls/init calls changes the registry.
mod = getOwn(registry, moduleName);
if (!found && !hasProp(defined, moduleName) && mod && !mod.inited) {
if (config.enforceDefine && (!shExports || !getGlobal(shExports))) {
if (hasPathFallback(moduleName)) {
return;
} else {
return onError(makeError('nodefine',
'No define call for ' + moduleName,
null,
[moduleName]));
}
} else {
//A script that does not call define(), so just simulate
//the call for it.
callGetModule([moduleName, (shim.deps || []), shim.exportsFn]);
}
}
checkLoaded();
}
这个函数主要是去做了从queue中拿出来define里push进去的字符串,并调用callGetModule去调用模块,callGetModule又去做了什么
function callGetModule(args) {
//Skip modules already defined.
if (!hasProp(defined, args[0])) {
getModule(makeModuleMap(args[0], null, true)).init(args[1], args[2]);
}
}
在require内部,有一个defined全局变量来储存已经定义好的模块,如果这个模块目前没有定义,那就再做下面的makeModuleMap,这个方法则是用来实现对当前module信息的组装,并生成一个Map,它将会返回以下的值:
return {
prefix : prefix,
name : normalizedName,
parentMap : parentModuleMap,
unnormalized : !!suffix,
url : url,
originalName : originalName,
isDefine : isDefine,
id : (prefix ?
prefix + '!' + normalizedName :
normalizedName) + suffix
};
然后再去调用getModule,这也是require里面来组装module的主要方法,在require内部定义了Module类,而这个方法则会为当前的ModuleMap,其中包含了这个模块的路径等信息。这里要注意的是getModule方法里面拥有一个基于全局context的registry变量,这里则是用来保存根据ModuleMap来实例化的Module,并将其保存在了registry变量中(立即保存的Module只是一个空壳,后面实例中介绍),后面会介绍代码的重用如何实现的。
我们直接来看看Module类是长什么样的:
Module = function (map) {
this.events = getOwn(undefEvents, map.id) || {};
this.map = map;
this.shim = getOwn(config.shim, map.id);
this.depExports = [];
this.depMaps = [];
this.depMatched = [];
this.pluginMaps = {};
this.depCount = 0;
};
Module.prototype = {
//init Module
init : function (depMaps, factory, errback, options) {},
//define dependencies
defineDep : function (i, depExports) {},
//call require for plugins
fetch : function () {},
//use script to load js
load : function () {},
//Checks if the module is ready to define itself, and if so, define it.
check : function () {},
//call Plugins if them exist and defines them
callPlugin : function () {},
//enable dependencies and call defineDep
enable : function () {},
//register event
on : function (name, cb) {},
//trigger event
emit : function (name, evt) {}
}
new一个Module后,使用init来对Module对象进行初始化,并主要传入其的依赖数组和工厂化方法。这这么多的方法里,主要的两个方法则是enable和check方法,这两个方法是对方法,当init里调用enable后,下来将要进行的就是一个不断重复的过程,但是过程的主角在一直改变。
递归
上面说的这个过程那就是在初始化Model的时候去查找它的依赖,再去用load方法异步地去请求依赖,而依赖又是一个个Module,又会再对自己自身的依赖的依赖进行查找。由于这个过程都是异步进行的,所以都是通过事件监听回调来完成调用的,我们来举下面的例子:
如
- A 的依赖有 B C
- B 的依赖有 C D
- C 的依赖有 A B
这是一个很绕的例子,如A,B,C都有自己的方法,而我们在实现时都互相调用了各自的方法,我们姑且不讨论这种情况的现实性。
当如果我去require("A")时,require去查找defined中是否有A模块,如果没有,则去调用makeModuleMap来为即将调用的模块实例一个ModuleMap并加入到defined中,再用ModuleMap实例化一个Module加入到registry中,但是这时候的Module是一个空壳,它是只存储了一些模块相关的依赖等,模块里的exports或者callback是还没有被嵌进来,因为这个文件根本没有被加载呀!
注册时触发Module.init方法去异步加载文件(使用script)。加载完毕后,触发A里的define函数,define函数通过参数或callback里查找A模块需要的依赖,即B和C模块,将B,C加入到A的依赖数组中。这时则触发completeLoad函数,这时complete再去从queue中遍历,调用callGetModule去查找B、C模块,这时则会创建B和C模块的ModuleMap,根据ModuleMap去实例化空壳Module,(调用异步load加载,再触发define等,继续查找依赖…………),再接下来会做checkLoaded,我们看看这个函数:
function checkLoaded() {
var err,
usingPathFallback,
waitInterval = config.waitSeconds * 1000,
//It is possible to disable the wait interval by using waitSeconds of 0.
expired = waitInterval && (context.startTime + waitInterval) < new Date().getTime(),
noLoads = [],
reqCalls = [],
stillLoading = false,
needCycleCheck = true;
//Do not bother if this call was a result of a cycle break.
if (inCheckLoaded) {
return;
}
inCheckLoaded = true;
//Figure out the state of all the modules.
eachProp(enabledRegistry, function (mod) {
var map = mod.map,
modId = map.id;
//Skip things that are not enabled or in error state.
if (!mod.enabled) {
return;
}
if (!map.isDefine) {
reqCalls.push(mod);
}
if (!mod.error) {
//If the module should be executed, and it has not
//been inited and time is up, remember it.
if (!mod.inited && expired) {
if (hasPathFallback(modId)) {
usingPathFallback = true;
stillLoading = true;
} else {
noLoads.push(modId);
removeScript(modId);
}
} else if (!mod.inited && mod.fetched && map.isDefine) {
stillLoading = true;
if (!map.prefix) {
//No reason to keep looking for unfinished
//loading. If the only stillLoading is a
//plugin resource though, keep going,
//because it may be that a plugin resource
//is waiting on a non-plugin cycle.
return (needCycleCheck = false);
}
}
}
});
if (expired && noLoads.length) {
//If wait time expired, throw error of unloaded modules.
err = makeError('timeout', 'Load timeout for modules: ' + noLoads, null, noLoads);
err.contextName = context.contextName;
return onError(err);
}
//Not expired, check for a cycle.
if (needCycleCheck) {
each(reqCalls, function (mod) {
breakCycle(mod, {}, {});
});
}
if ((!expired || usingPathFallback) && stillLoading) {
//Something is still waiting to load. Wait for it, but only
//if a timeout is not already in effect.
if ((isBrowser || isWebWorker) && !checkLoadedTimeoutId) {
checkLoadedTimeoutId = setTimeout(function () {
checkLoadedTimeoutId = 0;
checkLoaded();
}, 50);
}
}
inCheckLoaded = false;
}
这个函数对所有已在registry中的Module进行遍历,并来判断其是否已经完成了定义(定义是在Module.check函数里完成的,定义完成后ModuleMap.isDefined = true,并将其从registry中删除,其会将真正的模块内容注入到对应的defined中),注意这里有一个重要的地方,checkoutLoadTimeoutId是一个间隔为50ms的setTimeout函数,即当在加载的时候会不断轮询去查看所有模块是否已经加载好了,因为所有的模块都是异步进行加载的,所以这样可以完全保证所有模块进行完全加载,并进行了过期设定。
接着上面的例子讲,当加载B模块时,会去查找A和C模块,这时候A模块是已经加载的,但是不能确定C是否已经加载好,但是这时的C模块空壳Module已经加入到了registry中,所以这时会像上面去轮询C模块是否加载,C模块不加载好,是无法对B模块进行注入的,B模块在这一阶段仍是那一个registry里的空壳Module,直至C模块已经定义,B模块的depCount成为0,才可以继续运行去注入自己。在对模块进行define的时候,用上了defining,是为了防止内部的factory进行加工时,再去尝试去define这个Module,就像一个圈一样,掐断了它。
这就是整个require工作的流程,其中主要使用了异步加载,所以让这个思想变得异常的复杂,但是带来的却是性能上的优化,需要我们注意的是:
在使用require时,我们需要注意依赖包的引入,如果我们把B的改成define("B",[],callback),这时B是没有callback依赖预读,那么我们在引入A模块的时候异步加载了B和C模块,但是B模块里使用了C模块的方法,这里的B是直接运行的,并不去检测其的依赖包是否加载完毕,所以这时的B运行时碰到require("C")时,C模块是否加载好是不确定的,这时候代码会不会出问题就是网速的问题了……………………
小心
我们在使用时要小心define()的用法:
- define(name, dependencies, callback)
将依赖写在参数dependencies中,这样require时会对里面的依赖进行加载,加载完后才会执行callback - define(dependencies, callback)
同上 - define(name, callback)
直接在callback中require依赖,会对callback.toString()进行正则查找require(....),同样加载查找出的所有依赖并加载完后执行callback - define(callback)
同上
使用时千万不能在第一、二种情况下直接require依赖,这样并不能保障该模块是否已被定义下执行了callback。
在使用后两种情况时,必须要注意的一点是,在require中对callback使用了callback.length判断,如果回调中没有加参数,则不会进行callback.toString()进行查找,所以我们在这两种情况使用时务必要加上参数,哪怕是没用的,如define(function(require){})。
可以看出,require总是在自动的分析对模块的依赖并去加载它们,如果我们一次性在文件中都互相引入了所有模块,那就会使得整个模块化过程变得累赘不堪,就是说即使当前只需要两三个模块来完成页面,而其它很十几二十个模块都会被加载进来,虽然模块化达成了,但是效率却是下降了。所以在使用的使用我们要去智能地判断目前立即需要的模块,而非立即的模块我们可以在空闲时间进行加载,而并是不去影响主页面的加载和渲染,这在实现单页面应用时及其重要。
Finish.

