
福大软工1816 · 第二次作业
福大软工1816 · 第二次作业
1. Github地址
https://github.com/jimons/personal-project
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 400 | 20 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 240 |
| · Design Spec | · 生成设计文档 | 20 | 50 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 70 | 45 |
| · Coding | · 具体编码 | 50 | 120 |
| · Code Review | · 代码复审 | 50 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 200 |
| Reporting | 报告 | 100 | 160 |
| · Test Repor | · 测试报告 | 10 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 80 | 100 |
| 合计 | 965 | 1365 |
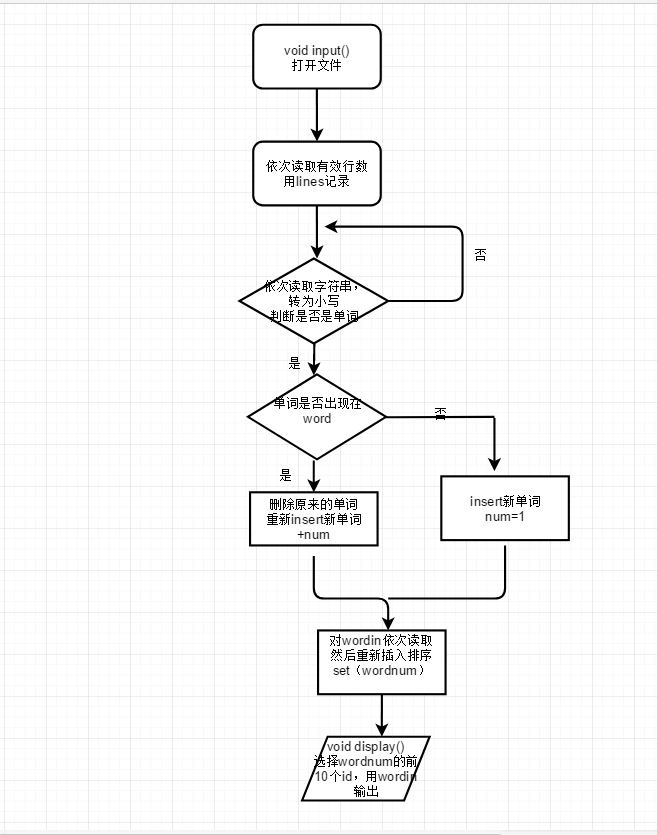
3. 解题思路描述
-
统计文件的字符数:
打开文件,然后依次读入,判断它们的ASCII码是否是在1——127之间,如果是则累加,如果不是,则不管它继续遍历。
-
统计文件的单词总数:
重新再打开一次文件,然后每次读入一行判断是否是单词,如果前面4个是字母,则这行一直遍历到不是字母和数字的其他符号,都确定为分隔;一旦确定为分隔符后,又用substr()减去前面的字母,剩余的字符串继续判断是否为字母,不过判断的时候需要注意到是数字+字母*4+组成的单词还是分隔符+字母*4+,如果前者,则不计入单词,后者则计入。这个计算单词数我是定为int words_count()来调用。
-
统计文件的有效行数:
这个我是根据逐行读取,然后一行一行判断,主要就是判断是否为空行。我是根据一行读下来,如果下一行读是空行,而该行的上面一行也是空行,则确定该行为空行,就不加,否则行数就++。
-
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词:
这个我利用了set函数,然后利用哈希树,将e1的频数*100000(好多个)+e2.字母*27*27*27(依次减少,因为26个字母),然后就直接vector,依次排出来啦!这个一次就成功了,前面的代码真的是改到我要吐血了!
4. 设计实现过程
应作业要求,代码组织如下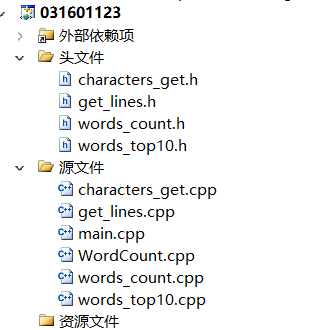
1.get_lines()
注释:这个代码就是从文件中读取出来,然后++,就可以了。
int get_lines() { fp2 = fopen("WordCount.txt","r+"); char c,ch='0'; int lines=0; while((c = fgetc(fp2)) != EOF) { if(c == '\n' && ch != '\n') lines++; ch = c; } if(ch != '\n') lines++; return lines; }
2.characters_get()
注释:这个也是从文件夹中再读取出来,然后直接就可以得到所有的字符数。
int characters_get() { int characters=0; fp1 = fopen("WordCount.txt","r+"); char c; while((c = fgetc(fp1)) != EOF) { if(c >= 0 && c <= 127) characters++; } return characters; }
3.这两个分别是计算单词的数目和top10,top10是直接用set函数,vector然后输出来的。
void words_top10() int words_count()
4.下面这个就是主函数main()
注释:按题目要求依次输出characters、lines、words、以及字典顺序的单词。
int main() { double t = clock(); int lines,words,characters; characters=characters_get(); cout<<"characters:"<<characters<<endl; lines=get_lines(); cout<<"lines:"<<lines<<endl; words=words_count(); cout<<"words:"<<words<<endl; words_top10(); cout<<"< Elapsed Time: "<<(clock()-t)/CLOCKS_PER_SEC<<" >"<<endl; return 0; }
5.头文件:
注释:用结构体与set函数、哈希结合使用来构造字典排序的作用,还是蛮暴力的。
#include<stdio.h> #include<iostream> #include<stdlib.h> #include<cmath> #include<vector> #include<cstring> #include<stack> #include<set> #include<string.h> #include<ctime> using namespace std; #define MAXN 15000//宏定义 FILE *fp1,*fp2; struct word{ char letter[100]; int num; int id; }; struct compare{ bool operator()(const word& e1, const word& e2)const{ if( e1.letter[0]*27*27*27*27*27*27+e1.letter[1]*27*27*27*27*27+e1.letter[2]*27*27*27*27+e1.letter[3]*27*27*27+e1.letter[4]*27*27+e1.letter[5]<=e2.letter[0]*27*27*27*27*27*27+e2.letter[1]*27*27*27*27*27+e2.letter[2]*27*27*27*27+e2.letter[3]*27*27*27+e2.letter[4]*27*27+e2.letter[5]) return true; return false; } }; struct comparenum{ bool operator()(const word& e1, const word& e2)const{ if(e1.num*100000000000000000+e2.letter[0]*27*27*27*27*27*27+e2.letter[1]*27*27*27*27*27+e2.letter[2]*27*27*27*27+e2.letter[3]*27*27*27+e2.letter[4]*27*27+e2.letter[5]>=e2.num*100000000000000000+ e1.letter[0]*27*27*27*27*27*27+e1.letter[1]*27*27*27*27*27+e1.letter[2]*27*27*27*27+e1.letter[3]*27*27*27+e1.letter[4]*27*27+e1.letter[5]) return true; return false; } }; set<word,compare>wordin; set<word,comparenum>wordnum; int idnum[10];
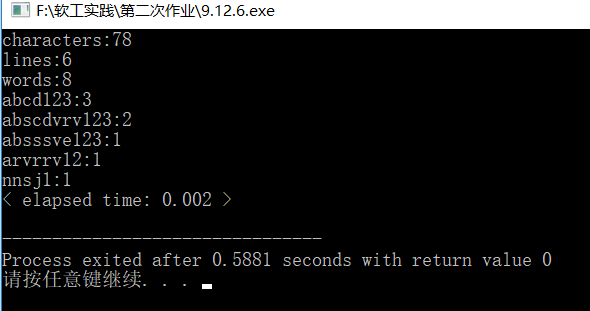
Dev-c++测试:
测试案例:

测试结果:
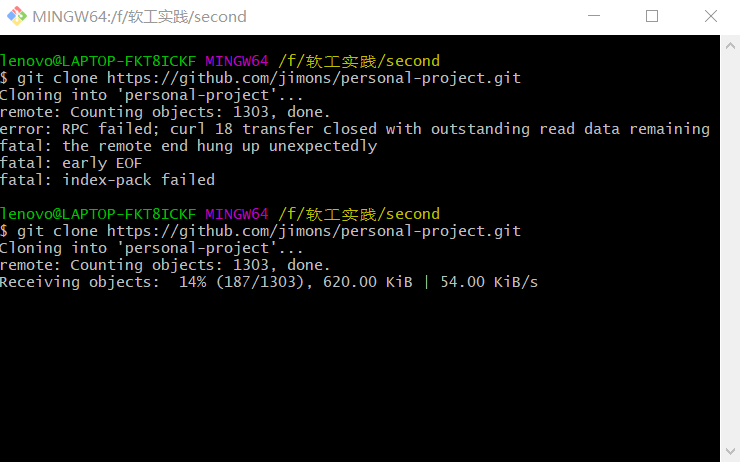
准备将代码copy 到VS上时,首先在git clone 时候,我一直在怀疑是网络的问题,结果每到39%的时候,我就在手机热点与无线之间来回切换,切换一次它就失败一次,重新来过.....结果百度才发现..它就是这么慢。。。。。。。。。。
5.个人收获
- 我为什么不早点做?!!!!!我在干嘛!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
- 看到这个作业的时候,我刚开始,还是找不到题目在哪里的,然后过了两天才开始仔仔细细的找题目怎么做,所以时间也就浪费掉了,导致现在修改完代码后,git没来得及学习,就要提交博客了.....
- 通过这个作业,结合我暑假时候写的程序代码,用上了vector、哈希、以及set函数等这些数据结构,算是对数据结构温故了一遍吧,但是这仅仅只是一个程序而已,跟软件相比还是................
- 我在写代码之前有看了邹欣老师的《构建之法》前面一点点和老师给的博客,感觉博客比较容易看得懂呀!!!!
- 最后,下一次作业,我一定要一发下来就做!!!!一定要!!!!!

