

ICTCLAS分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统,该版的Free版开放了源代码,为初学者提供了宝贵的学习材料。我们可以在“http://sewm.pku.edu.cn/QA/”找到FreeICTCLASLinux.tar的C++代码。
可是目前该版本的ICTCLAS并没有提供完善的文档,所以阅读起来有一定的难度,所幸网上可以找到一些对ICTCLAS进行代码分析的文章,对理解分词系统的内部运行机制提供了很大的帮助。这些文章包括:
1)http://blog.csdn.net/group/ictclas4j/;《ICTCLAS分词系统研究(一)~(六)》作者:sinboy。
2)http://qxred.yculblog.com/post.1204714.html;《ICTCLAS 中科院分词系统 代码 注释 中文分词 词性标注》作者:风暴红QxRed 。
按照上面这些文章的思路去读ICTCLAS的代码,可以比较容易的理顺思路。然而在我阅读代码的过程中,越来越对ICTCLAS天书般的代码感到厌烦。我不得不佩服中科院计算所的人思维缜密,头脑清晰,能写出滴水不漏而又让那些“头脑简单”的人百思不得其解的代码。将一件本来很简单的事情做得无比复杂...
ICTCLAS中有一个名为CDynamicArray的类,存放在DynamicArray.cpp与DynamicArray.h两个文件中,这个DynamicArray是干什么用的?经过一番研究后终于明白是一个经过排序的链表。为了表达的更明白些,我们不妨看下面这张图:

(图一)
上面这张图是一个按照index值进行了排序的链表,当插入新结点时必须确保index值的有序性。DynamicArray类完成的功能基本上与上面这个链表差不多,只是排序规则不是index,而是row和col两个数据,如下图:

(图二)
大家可以看到,这个有序链表的排序规则是先按row排序,row相同的按照col排序。当然排序规则是可以改变的,如果先按col排,再按row排,则上面的链表必须表述成:

(图三)
在了解了这些内容的基础上,不妨让我们看看ICTCLAS中DynamicArray.cpp中的代码实现(这里我们只看GetElement方法的实现,其基本功能为给出row与col,然后将对应的元素取出来)。

PARRAY_CHAIN *pRet)
{
PARRAY_CHAIN pCur = pStart;
if (pStart == 0)
pCur = m_pHead;
if (pRet != 0)
*pRet = NULL;
if (nRow > (int)m_nRow || nCol > (int)m_nCol)
//Judge if the row and col is overflow
return INFINITE_VALUE;
if (m_bRowFirst)
{
while (pCur != NULL && (nRow != - 1 && (int)pCur->row < nRow || (nCol !=
- 1 && (int)pCur->row == nRow && (int)pCur->col < nCol)))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
}
else
{
while (pCur != NULL && (nCol != - 1 && (int)pCur->col < nCol || ((int)pCur
->col == nCol && nRow != - 1 && (int)pCur->row < nRow)))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
}
if (pCur != NULL && ((int)pCur->row == nRow || nRow == - 1) && ((int)pCur
->col == nCol || nCol == - 1))
//Find the same position
{
//Find it and return the value
if (pRet != 0)
*pRet = pCur;
return pCur->value;
}
return INFINITE_VALUE;
}
这里我先要说明的是程序中的m_bRowFirst变量,它表示是先按row大小排列还是先按col大小排列。如果m_bRowFirst为逻辑真值,那么链表就如上面图二所示,如果为假,则如图三所示。
除了这个外,看到上面长长的条件表达式,你一定会吓坏了吧!更让人吓坏的是调用这段程序的代码:
//来自NShortPath.cpp中ShortPath方法
eWeight = m_apCost->GetElement( -1, nCurNode, 0, &pEdgeList);
//来自Segment.cpp中BiGraphGenerate方法
aWord.GetElement(pCur->col, -1, pCur, &pNextWords);//Get next words which begin with pCur->col
- 先分析第一个调用
第一个调用给GetElement方法的nRow传递了-1,他想干什么呢?
假设这时候变量m_bRowFirst为true,并且传递过去的nCol!=-1,那么while (pCur != NULL && (nRow != - 1 && (int)pCur->row < nRow || (nCol != -1 && (int)pCur->row == nRow && (int)pCur->col < nCol))) 等价于while (pCur != NULL && ( (int)pCur->row == -1 && (int)pCur->col < nCol))) ,注意红色部分在程序运行时永远为false(因为根本就不存在row为-1的结点),因此,上面的表达式等价于while(false)!这对于该段程序没有任何意义!
因此我们可以得到这样一个结论:如果GetElement方法的nRow参数取-1,当且仅当m_bRowFirst为false时才有意义。这时候,代码中第二个while得到执行,让我们分析一下:
while (pCur != NULL && (nCol != - 1 && (int)pCur->col < nCol || ((int)pCur->col == nCol && nRow != - 1 && (int)pCur->row < nRow))) 在nRow为-1时等价于while (pCur != NULL && ((int)pCur->col < nCol ) ,这就容易解释的多了:在如图三所示的链表中查找col=nCol 的第一个结点。
My God!
- 再分析第二个调用
上面的第二个调用就更让人摸不着头脑了:将pCur->col传递给GetElement的nRow参数,并将-1传递给nCol参数,这想干什么呢?要想分析清楚这个问题,没有个把钟头恐怕不行(再次佩服这些中科院的牛人们)。
按照“分析第一个调用”中的结论可知,如果GetElement方法的nCol参数取-1,当且仅当m_bRowFirst为true时才有意义。因此链表排序一定是先按照行排(如图二),此时对DynamicArray的GetElement方法的调用可以简化成:
aWord.GetElement(pCur->col, -1, pCur, &pNextWords);
//======================================================================
ELEMENT_TYPE CDynamicArray::GetElement(int nRow, int nCol, PARRAY_CHAIN pStart, PARRAY_CHAIN *pRet)
// 经过调用后,上面的形参对应的值分别是:nRow:pStart->col, nCol:-1, pStart, &pNextWords
// 注意,为了和下面代码中的pCur以示区分,这里用了pStart这个变量名。
{
......
while (pCur != NULL && ((int)pCur->row < pStart->col))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
if (pCur != NULL && ((int)pCur->row == pStart->col)
//Find the same position
{
//Find it and return the value
if (pRet != 0)
*pRet = pCur;
return pCur->value;
}
return INFINITE_VALUE;
}
此时的意义就比较明显了,其实就是找pCur->row == pStart->col的那个结点。
可有人会问,干吗把row和col扯到一起呢?这又是一个非常复杂的问题。具体内容可以参考sinboy的《ICTCLAS分词系统研究(四)--初次切分》一文。这里简单解释如下:
如图四,这是row优先排列的一个链表:

图四 进行初步分词后的链表结构(TagArrayChain)实例
用二维表来表示图四中的链表结构如下图五所示:

图五 TagArrayChain实例的二维表表示形式
然后找出相邻两个词的平滑值。例如“他@说”、“的@确”、“的@确实”、“的确@实”、“的确@实在”等。如果仔细观察的话,可以注意到以下特点:例如“的确”这个词,它的col = 5,需要和它计算平滑值的有两个,分别是“实”和“实在”,你会发现这两个词的row = 5。同样道理,“确”的col = 5,它也需要和“实”与“实在”(row = 5)分别计算平滑值。
其实,这就是为什么上面分析的找pCur->row == pStart->col的那个结点的原因了。最终得到的平滑值图可以表述成图六:
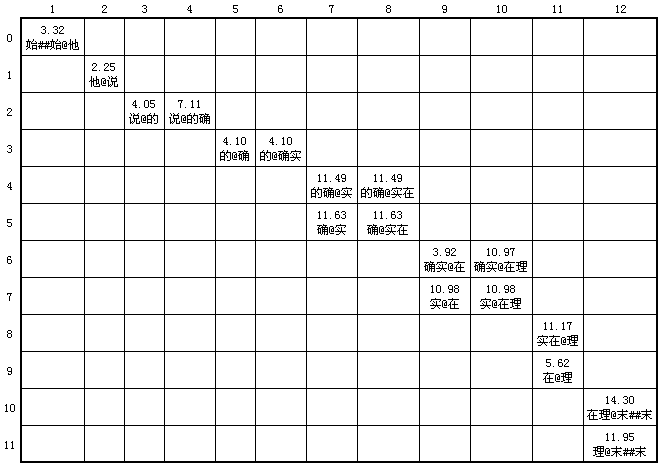
图六 进行初次分词后生成的二叉图表的二维图表表示形式
到此为止才明白代码作者的真正用意:
......
//取得和当前结点列值(col)相同的下个结点
aWord.GetElement(pCur->col, -1, pCur, &pNextWords);
while(pNextWords&&pNextWords->row==pCur->col)//Next words
{
//前后两个词用@分隔符连接起来
strcpy(sTwoWords,pCur->sWord);
strcat(sTwoWords,WORD_SEGMENTER);
strcat(sTwoWords,pNextWords->sWord);
......
}
- 小结
想不到短短一个GetElement方法中竟然综合考虑了1)row优先排序的链表;2)col优先排序的链表;3)当nRow为-1时的行为(只有m_bRowFirst为false时才能这么做,代码中没有指,所以非常容易出错!);4)当nCol为-1时的行为;5)当nRow与nCol都不为-1时的行为。
这也难怪我们会看到诸如while (pCur != NULL && (nRow != - 1 && (int)pCur->row < nRow || (nCol != -1 && (int)pCur->row == nRow && (int)pCur->col < nCol))) 这样的逻辑表达式了!我们也不得不佩服代码书写者复杂的逻辑思维能力(离散数学的谓词逻辑一定学得超级好)和给代码阅读者制造障碍的能力!类似代码在ICTCLAS中比比皆是,看来我只能恨自己脑筋太简单了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号