
当我们谈重构的时候我们想谈什么?
郑昀 20180411
如果你在繁忙的业务迭代中开始系统重构,恭喜你,说明你的业务已经完成了从0到1,正在从1走向10,或者从10走向100。
至于重构后的技术栈是 Spring MVC+Dubbo,还是 Spring Boot+Spring Cloud?
是 Vue+ElementUI,是 React,还是 Ant.design,抑或就是上古时代的 JQuery+Bootstrap?
是 k8s,还是 mesos+marathon?是 Thrift,还是 Hessian,抑或 Protobuf?我并不在意。
我并不 care 这些东西,每个技术团队都可以有自己的技术选型思路。
我在意的是两个“是否有利于”:
一,是否有利于发布部署。
二,是否有利于排除故障(是否有利于快速定位线上问题和解决问题)。
为什么要强调它俩?
因为我们在过去六七年间,经历了太多的生死折磨。如履薄冰如临深渊。
我们曾是做本地生活服务电商的,餐饮/电影/酒店/景点门票/美容美发……
节假日往往也是本地生活服务的峰值日,饭点儿就相当于秒杀。
太多次在假期被召回。
太多次打电话给各个 TeamLeader,有时电脑不在身边,有时深山老林无法上网,有时无人接听,有时 VPN 连不进去~
多少次翘首期盼 DBA、SA、QA、DevManager 们给我回报到底出啥事儿了。
请先阅读一下我写的《经历不可抗力是一种什么体验》,了解一下什么是 too young too naive。
以至于我有两个怨念:
怨念一,Centreon 烂到渣,Zabbix 也不咋的,基础运维的那些神兵利器,都不考虑做业务的人,尤其是业务集群规模庞大的人,到底是怎么排查问题排除故障的。
SA 是怎么工作的?
一旦出现连接数暴涨,Web/App 服务长时间无响应,应用内存飙升,SA 拍马赶到,一定是先重启相关应用(不管是容器还是虚拟机),如果还不管用,就立即将相关应用悉数回滚到上一个稳定版本上,争取以最短时间恢复。
等研发介入时,现场已经不复存在。
六七年前,事发后,我们登入 Centreon 和 ELK,按机器组、按机器、按指标,用肉眼,用大脑,结合各个业务集群里的日志,结合 Nagios 报警短信,理出来一个因果证据链。
你可能需要打开几百个监控页面,你还需要精通业务集群的分组、调用关系和IP(那时候还没有 Docker 容器,都是虚拟机)。
这也就是为什么我定下我司研发哲学第一条:Don't make me think……
怨念二,开源软件的开发者是好人也往往是性情中人,不太考虑排除故障成本低、可视化、高可用、可伸缩、监控报警等商业系统必备的运维属性,拿来主义必死无葬身之地。
举个例子吧,ActiveMQ 和 RabbitMQ 有生产者流量控制,如果你没有听说过,没有遇到过,恭喜你,但也表明你的业务量还是太小。
你可能会说,遇到了生产者流量控制,说明下游消费者消费得太慢,加快速度不就完了?
在电商服务中,异步消息队列的消费者往往是与第三方系统网络通讯,第三方系统可就不在你控制范围之内了,一个第三方系统挂了,或者突然拥塞,就会憋住你的消费者集群的所有线程,造成消息积压。因此就将上游生产者挂起?开玩笑呢吧?!咋想的这都是?让灾难从下游蔓延到上游?!
那么我们应该怎么思考系统重构呢?
随着业务规模越来越大,随着应用越来越多,随着 Docker 容器集群的引入,随着前后端分离导致内部接口越来越多,随着 API 网关的引入,我们越来越难以在5分钟之内断定系统出了什么事儿。
因此,我要求:
戒律一:凡是中间件,不管是自主研发的,还是以开源软件为内核构建出来的,都必须自带监控报警,否则不允许上线。
戒律二:本着 Don't make me think 的哲学思路,所有对排除故障有帮助的信息,都必须一站式展示在交互界面上,也就是在中间件的控制台上,或运维自动化平台上,或研发协作平台上。
下面举一些具体的例子,帮助大家理解。
我司的技术支撑体系如下图所示(或点击查看原图):
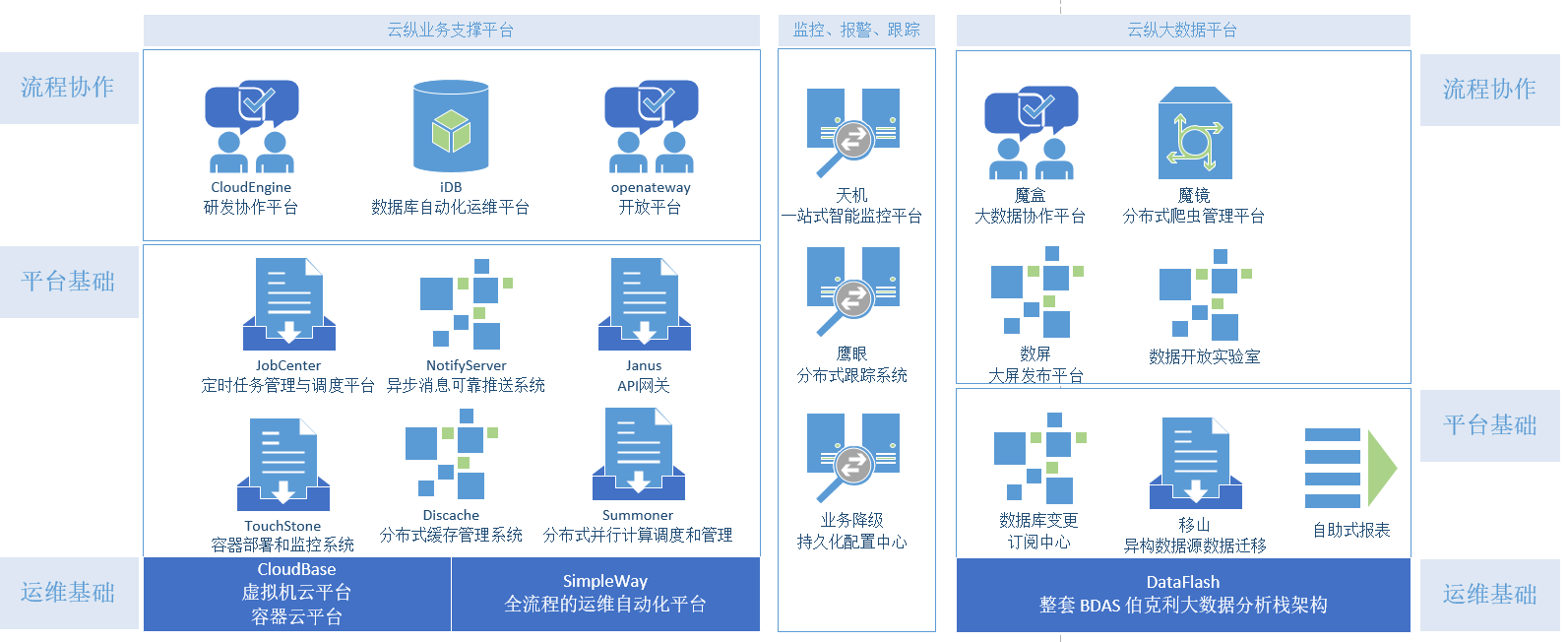
其中:
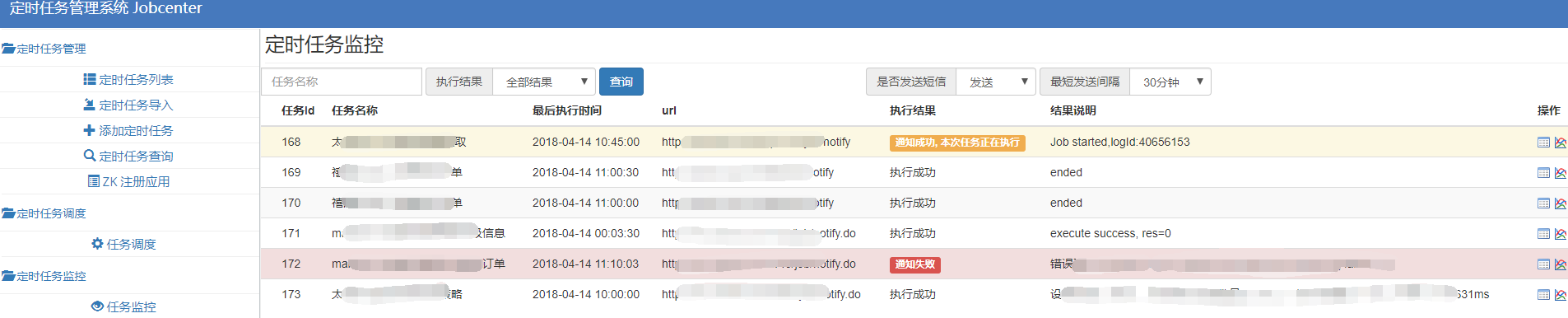
1,定时任务管理与调度平台有运行情况展示,自带监控报警:
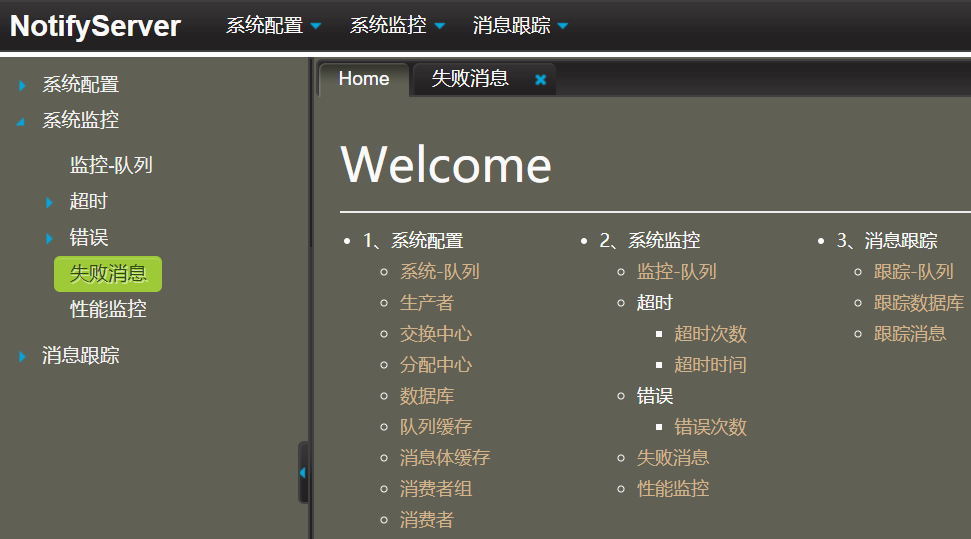
2,异步消息可靠推送系统有可视化的内部详情展示,自带监控报警:
3,分布式并行计算调度与管理平台一站式展示工作流下每一个任务在所有节点上的运行日志,并自带监控报警:

4,大数据协作平台自带监控报警:

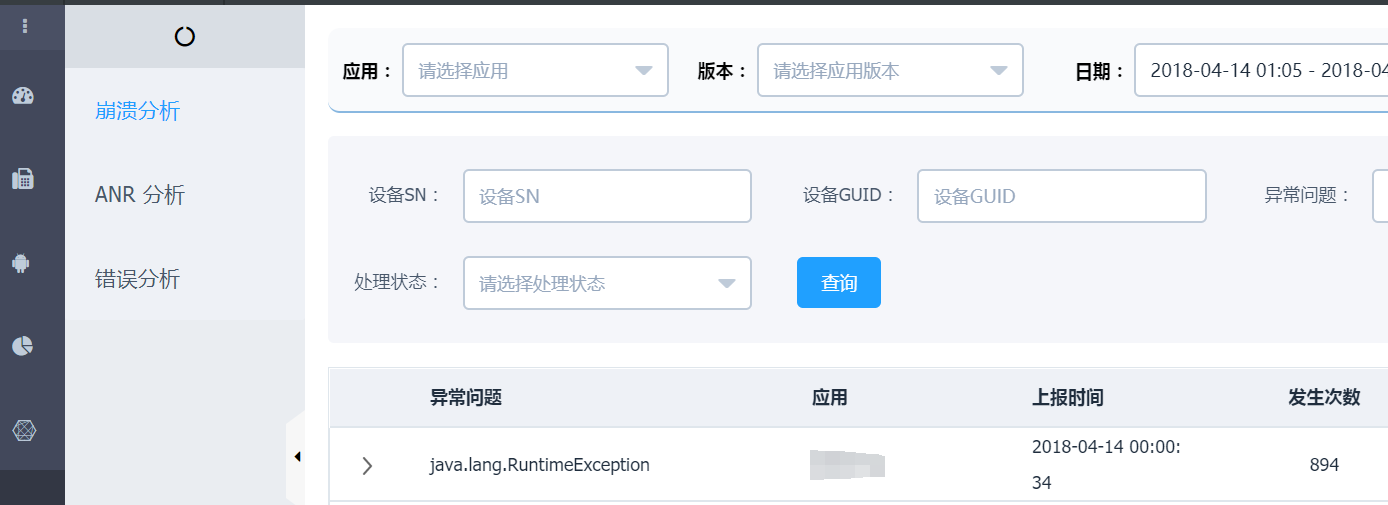
5,我们甚至要把所有 PC 客户端,所有智能设备都监管起来:
6,研发协作平台一站式展示应用部署的方方面面:

可以说我们打造的每一个中间件、协作平台都体现了戒律一和戒律二。
不需要东奔西走,四处收集蛛丝马迹。
不需要一次性点开几百个指标页面,脑补推演。
不需要精通集群部署结构。
不需要熟知应用日志的路径。
对,这就是为我这样的“旁观者”、“小白”准备的。
有了这些系统,即使大家都出去玩了,我一个人也能看出问题所在,同时也能有效应对铁打营盘流水兵的情况。
当你完成了从0到1的跨越,正在从1走向10,走向100,请记住下面的忠言:
两个“是否有利于”:
一,是否有利于发布部署。
二,是否有利于排除故障(是否有利于快速定位问题和解决问题)。
两个戒律:
戒律一:凡是中间件,不管是自主开发的,还是以开源软件为内核构建出来的,都必须自带监控报警,否则不允许上线。
戒律二:本着 Don't make me think 的哲学思路,所有对排除故障有帮助的信息,都必须一站式展示在交互界面上,也就是中间件的控制台上,或运维自动化平台上,或研发协作平台上。
-EOF-
欢迎订阅我的微信订阅号『老兵笔记』

赠图一枚:
生活和你~


语录两条:
1,
王志安:“这叫调查?这叫武汉理工大学好吗!”于是评论纷纷打蛇随棍上:“对,武理取闹!”#新词发现#
2,
有一种离职叫『弃船逃生』:
『2011年在百度浏览器团队时,遇到几件让人印象深刻的事情。有一次开会,产品拿出Google某个产品的DEMO,里面有一段很酷炫的 3D 效果,要求开发加上,只给2天时间。大家目瞪口呆。后续,开发为了赶节奏,导致非常多的bug,又为了修改bug,leader将所有的bug按照人员平均分配,导致不同模块间的同学相互修改……实在难以想象,好比让做花卷的厨子,去修改西湖醋鱼的味道。
最初的现象是:bug下降得慢,进而bug反而增加,每个人都累得半死,代码风格极其杂乱,为了赶工引入的临时方案层出不穷。
到了中期:人员离职越来也多,代码难以维护,新加的需求与之前的临时方案冲突。
到了后期:想做一些修复,想调整架构,又要保证正常运行,其难度好比在一架飞行中的飞机上拆换零件。
然后我也急忙离职了……实在是看不到成功的可能性。
后来到了腾讯的团队,感觉流程就规范多了。需求和bug有Tapd跟踪,产品发布按照节奏,需求提出前会和开发反复讨论可行性,有专门的质量跟踪,有专门的用户反馈,每天知道要做什么,也知道明天要做什么。有产品需求,也有开发需求!这个非常重要。很多团队,都是只有产品需求,开发好像牛一样,耕完地就不管了?
流程其实没那么复杂,就是各司其责+节奏。』——https://zhuanlan.zhihu.com/p/35076829

