
电商课题VI:分布式Session
@郑昀汇总
与分布式缓存在高并发和高可用下所要解决问题差不多。
一.图示:
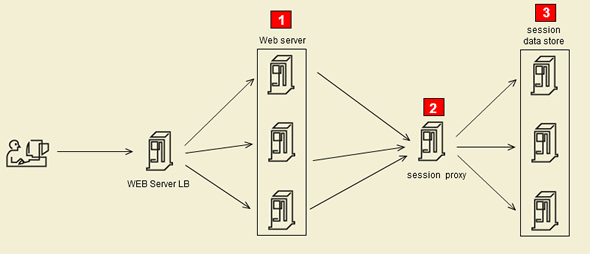
二.高并发下分布式Session需解决的问题:
- 透明处理存储介质的故障转移
- 动态增删节点,减小“缓存颠簸”问题
- 保证数据在各个节点的分布均衡
- Session 序列化和反序列化
三.保证“基本可用 Basically Available”的分布式Session方案:
Eric A. Brewer 在 1988 年提出的 BASE 策略,即 Basically Available、Soft state、和Eventually consistent。
互联网大多数应用更强调可用性,即牺牲高一致性,获得可用性或可靠性。
基本可用 Basically Available 的定义:在分布式系统部分损坏的时候,允许部分内容不可用,但是其他部分仍旧可用。因此称这种系统为“基本可用”。比如,一个数据存储系统由 五个节点构成。其中一个发生了损坏,这时只有20%的数据不能访问,其他80%数据仍然可用。那么就可以称这种系统为基本可用的。
基于 memcache 的 Hash取模算法(hash() mod n,hash() 取用户ID,n为节点数) 实现的分布式 Session 方案,就属于基本可用:
第一,如果节点发生故障,该节点上的所有用户 Session 丢失,系统无法自恢复。第二,如果系统压力突然增大,需要临时增加机器节点。按照 Hash取模的算法,在增加机器节点的这一时刻,大量缓存无法命中(其实还都存在之前的节点上),导致大范围的缓存穿透,压力会直接打到数据库上。第三,根据 LRU 缓存失效算法,memcache 里存储的 key/value 有可能被踢出,用户 Session 容易丢失。
针对 Hash取模 的改进办法是:
四.基于一致性哈希算法的 memcache 解决方案
1)一致性哈希帮我们解决的是,当机器节点减少时,缓存数据能进行最少重建。
2)还能解决 Session 数据的分布均衡问题。
3)当机器节点宕机,这部分数据必然丢失。由于节点数目变化,有可能对部分没有丢失的数据也要重建。
但上面的方案都解决不了“一个节点失败后,它所存储的 Session 如何由其他节点获取以便接替失效节点,实现集群的容错(Failover)”。
郑昀先介绍下面几个概念:
五.Sticky Session、Non-sticky Session和Replicated Sessions
- Sticky Sessions:粘性会话。即同一个会话中的请求必须被转发到同一个节点上,除非该节点宕机才转发到故障转移节点。一个节点宕机,所存储的 Sessions 完全丢失。通俗的话就是,将用户“粘”在某一个服务器节点上。
- Non-Sticky Sessions:非粘性会话。每一次请求都可能转发到不同节点。
- Replicated Sessions:把一个节点上的 Sessions 复制到集群的其他节点上,防止数据丢失,允许失效无缝转移。如node 0复制到node 5,node 1复制到node 6,以此类推。多数应用服务器(如 Tomcat )都支持会话复制机制。
当用户数量和集群数量达到一定规模后,Session 复制就可能成为性能瓶颈。于是人们提出了 从第三方缓存恢复失效节点数据 的方案,开源产品 Memcached-Session-Manager(下面简称MSM)就是基于这个思想。
六.MSM的工作原理
MSM 支持 Tomcat 6 和 7,即它主要解决的是 Tomcat 的高可用性。
它的特性为:
- 支持 sticky sessions 和 non-ticky sessions 模式。
- 没有单点故障。
- 能处理 tomcat 故障转移
- 能处理 memcache 故障转移
- pluggable session serialization
- 允许异步存储 session,提高响应速度
- sessions 只有真正被修改时,才会发给 memcache
6.1.Sticky Session 模式下的工作原理
即,Tomcat 的本地 session 为主 session,memcache 中的 session 为备 session。
第一步,所有 Tomcat 节点都需要安装 MSM;每一个 Tomcat 会有自己的本地 session。第二步,当一个请求执行完毕之后,如果对应的 session 在本地不存在(即这是某一个用户的第一次请求),则将该 session 复制一份至 memcache 。第三步,当该 session 的下一个请求到达时,会使用 Tomcat 的本地 session。请求处理结束之后,session 的变化会同步更新到 memcache,保证数据一致。第四步,如果当前 Tomcat 节点失效,下一个请求会被路由给其他 Tomcat。这个 Tomcat 发现请求所对应的 session 并不存在,于是它将查询 memcache,如果查询到了,则恢复到本地 session。
这样就完成了容错处理。
6.2.Non-sticky Session 模式下的工作原理
即,Tomcat 的本地 session 为中转 session,memcache 1 为主 session,memcache 2为备 session。
第一步,收到请求,加载备 session 到本地容器;备 session 加载失败,则从主 session 加载;第二步,请求处理结束之后,session 的变化会同步更新到 memcache 1和 memcache 2,并清除Tomcat 的本地 session 。
session data 要想存入 memcache,必须能序列化和反序列化。
七.基于 kryo 的序列化方案
所有序列化策略都必须提供下面的特性:
- 序列化:能处理循环引用。
- 序列化/反序列化:支持对一个共享对象(Shared Object)的引用。
- 反序列化:支持 private classes 。
- 反序列化:支持没有默认构造函数的类。
下面是 MSM Wiki 所列出的表格:
| Serialization Strategy Value for transcoderFactoryClass attribute |
Requires java.io.Serializable |
Cyclic Dependencies |
Shared objects |
Private classes | Classes without default constructor |
Different class versions | Copy Collections before serialization |
Custom Converter |
Comment |
| java serialization(default, bundled with msm) de.javakaffee.web.msm.JavaSerializationTranscoderFactory |
Yes | Yes | Yes | Yes | Yes | No (Though, if the serialVersionUID is set to 1L, classes can be deserialized even if the new class version has new fields) |
No | No | |
| msm-kryo-serializer de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory |
No | Yes | Yes | Yes (for Sun JVMs) | Yes (for Sun JVMs) | No (not yet) | Yes | Yes (Converter must extend KryoCustomization, SerializerFactory or UnregisteredClassHandler) | Reflection based, Kryo is used for binary serialization/deserialization |
| msm-javolution-serializer de.javakaffee.web.msm.serializer.javolution.JavolutionTranscoderFactory |
No | Yes | Yes | Yes (for Sun JVMs) | Yes (for Sun JVMs) | Yes (During deserialization, fields that are not existing in a class are ignored) | Yes | Yes (Converter must extend [apidocs/javolution/xml/CustomXMLFormat.html CustomXMLFormat]) | Reflection based, Javolutionis used for actual xml encoding/decoding, it also does the object reference handling |
MSM 作者的观点是:
- Java serialization 是一个鲁棒性非常好、也被广泛证明了的技术,但 IMHO(恕我直言),它最大问题就是无法处理类的版本:向下兼容时新版本如何反序列化老版本序列化的数据流,如还要向上兼容的话老版本如何反序列化新版本序列化的数据流。为了确认兼容性,测试量将是版本数的平方。
- Kryo 是一个非常快的二进制序列化库。在 thrift 与 protobuf 的性能 benchmark 中,kryo 也是最快的序列化工具库之一。他推荐使用 Kryo ,就是因为超凡的性能。
八.基于 ZooKeeper 集群的分布式 Session 方案
要解决基于 memcache 方案的数据丢失问题,可以引入持久化存储介质 ZooKeeper(下面简称 ZK)。
依托于 ZK 的一致性复制(在多个副本间保证数据的强一致性)和容错能力,结合上面的 MSM 思想,
由 ZK 负责 session 数据的存储,而我们自己实现的 session manager 将负责 session 生命周期的管理。

九.微软系的解决方法
ASP.NET 有自己的分布式 Session 解决方案,Session State Server ,即 web.config 里指定 sessionState 的 mode 为“StateServer”即可。
郑昀既可以在 web.config 里指定一个 State Server :
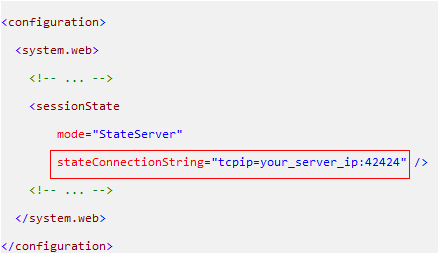
也可以实现 System.Web.IPartitionResolver 的接口,自行决定如何构造 Session State Server 连接字符串,从而支持一组 State Servers。
郑昀也可以用 sessionState 的 partitionResolverType 属性设定即可:
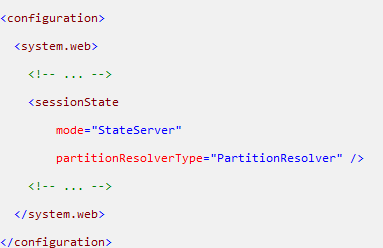
微软的这个解决方案缺点是,Session State 中的序列化和反序列化对象将成为主要性能消耗之一,最好使用基本类型来存储所有的 Session State 数据。
参考资源:
2) jacktan,2011,基于ZooKeeper的分布式Session实现
3) Maarten Balliauw,2008,ASP.NET Session State Partitioning
4)timyang,2009,某分布式应用实践一致性哈希的一些问题
7)developerWorks,2010,关于 Java 对象序列化您不知道的 5 件事

 浙公网安备 33010602011771号
浙公网安备 33010602011771号