
前端优化:淘宝的Combo Handler和新浪微博的link标签includes属性
郑昀 201207
前端优化一:Combo Handler来合并CSS/JS文件
背景
Combo Handler是Yahoo!开发的一个Apache模块,它实现了开发人员简单方便地通过URL来合并JavaScript和CSS文件,从而大大减少文件请求数。
目的
满足Yahoo!前端优化第一条原则:Minimize HTTP Requests,来减少三路握手和HTTP请求的发送次数。
国内实例
淘宝网首页meta里多个js合并的声明:
<script src="http://a.tbcdn.cn/??s/kissy/1.2.0/kissy-min.js,p/global/1.0/global-min.js,p/fp/2012/core.js,p/fp/2012/fp/module.js,p/fp/2012/fp/util.js,p/fp/2012/fp/directpromo.js?t=2012062320120712.js" data-fp-timestamp="20120703"></script>
js之间用英文逗号或&符号分隔。
此src的Response是多个js文件的内容拼装。
国内的Combo Script支持
淘宝李晶-拔赤在 https://github.com/jayli/combo 下发布了combo.php和minfy.php,能够做到合并文件(不压缩),以及合并且压缩。
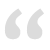 文件列表:
- combo.php 合并文件,不压缩
- minify.php 合并压缩文件
- cssmin.php 压缩css
- jsmin.php 压缩js
- cb.php 淘宝CDN合并文件策略的模拟
文件列表:
- combo.php 合并文件,不压缩
- minify.php 合并压缩文件
- cssmin.php 压缩css
- jsmin.php 压缩js
- cb.php 淘宝CDN合并文件策略的模拟脚本使用:
- 要求php5及以上版本
- 程序在找不到本地文件的情况下,会去指定的cdn上找同名文件
- 程序会自动转义-min文件为源文件,因此要约定-min文件和原文件要成对出现
- 需要定义combo.php和minify.php中的$YOUR_CDN变量
- 如果只是合并压缩local文件,则不必重置$YOUR_CDN变量
- 这里提供cb.php,用来实现tbcdn的开发环境的模拟,apache的配置在cb.php中
CDN上的Combo Handler支持
1.2008年7月YUI Team宣布在YAHOO! CDN上对YUI JavaScript组件提供Combo Handler服务。
2.淘宝CDN支持Combo Handler,用逗号分隔js/css,用两个问号来触发combo特性:
- http://a.tbcdn.cn/??1.js,2.js
- http://a.tbcdn.cn/subdir/??1/js,2.js
用一个问号来添加时间戳,如:
cb.php的代码实现
重点看 cb.php 源码:
A1.得到需要读取的文件列表

A2.304处理:检查请求头的if-modified-since,如客户端有缓存且,返回304
A3.逐一获取文件内容(探测文件是否存在),放入数组$R_files[]中

A4.添加过期头、输出文件类型、用"\n"拼接文件内容并输出
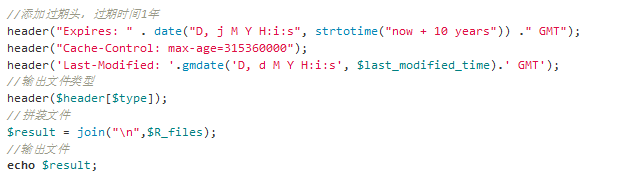
前端优化二:新浪微博的link标签includes属性
微博2012年在head里为link标签引入了includes属性,并用自家js解析。
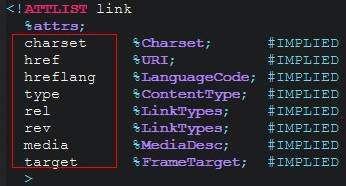
首先,link的includes属性不在xhtml1-transitional 的DTD声明中:
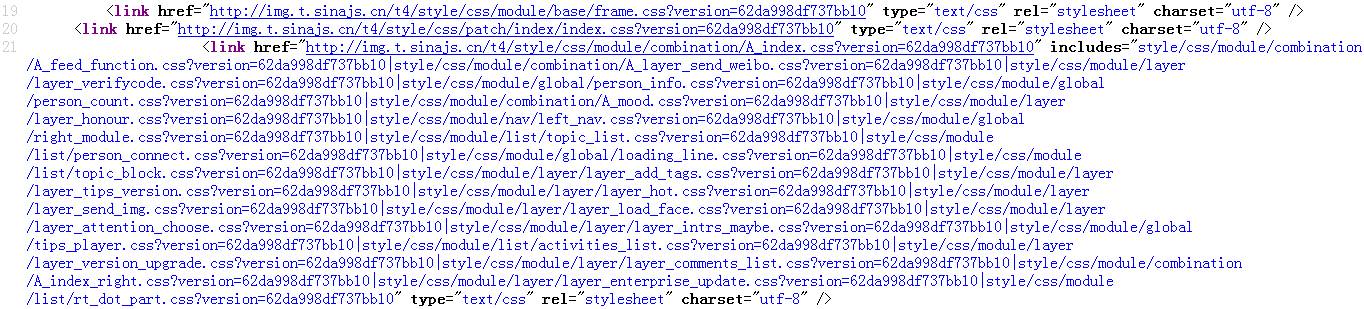
其次,新浪的includes是用“|”把许多不需要第一时间加载的css拼起来:
它在base.js里遍历所有link标签,逐一寻找是否有includes属性;然后把获得的这些个css作为key存储到一个字典f里,然后作为字典统统存储到一个大字典U里:
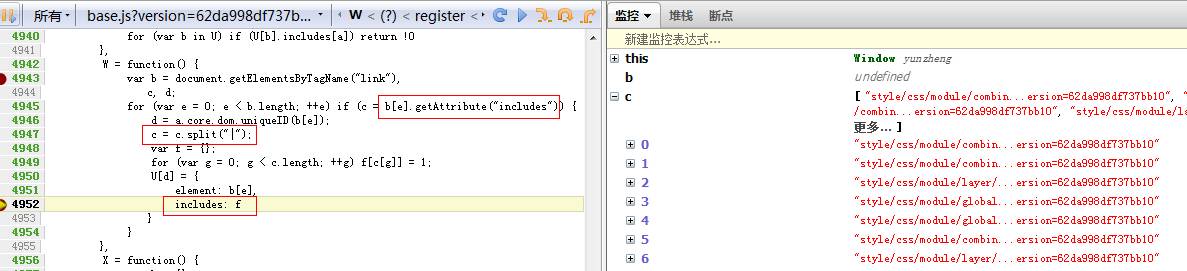
U = {}

这个d是取当前时间,再加一个自增量:
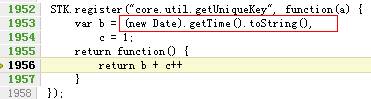
这是一个标准的浏览器里获得唯一ID的办法。(http://www.cnblogs.com/zhengyun_ustc/)
但至于这个U什么时候用,用来做什么,则不知道。遍历U的断点也没进入:

那么在什么情况下延迟加载这些css呢?有人知道吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号