
关于Cutt.com关于Topic Engine
关于Cutt.com关于Topic Engine
郑昀 20100726
上个月参加谷文栋效力的简网的内部产品调研会,提前了解了Cutt.com的功能。Cutt的Slogan是“关注你的关注”,原本以为它会是一个以个性化推荐为主打的应用,但从Slogan上看,更接近于信息过滤器。当你搜索时,它像一个Topic Engine,当你点击某一篇文章阅读时,它的界面又像Google Reader或鲜果阅读器。
Cutt.com在组织资讯时,我把它划分到Topic Engine一类,暂且不谈它的阅读模式和群体智慧。
Topic Engine的过去、现在和未来
先定义什么是Topic Engine。这是一个应用层面的概念,与算法层面的Topic Model概念不大一样。
我们所说的Topic,指可以用一个或一组关键词描述的一个主题,它对应于一个真实存在的、可被人理解的话题,比如用“小S Or 徐熙娣”关键词描述的主题“徐熙娣”。之所以叫“Engine”,指的是在有限(如新闻、论坛、博客、微博客、图片、视频等)的网络数据中,按照某种聚合逻辑,自动把与本主题有关联的资讯做有机整理和展现。
举一个例子,一个Topic Engine通常要展现的有:
Title——Jessica Alba
- Topic Logo
- Topic 隶属的 Categories(可以用作面包屑导航)
- Topic Wiki Item
- Related Top Stories(Story和Article的区别在于,一个Story可以包含若干内容大致相似、来自于不同新闻源的Articles。也就是Story做了去重和相似性计算工作。)
- Related Status Stream(即关联微博消息)
- Related Images
- Related Videos
- Related Topics/Topics Relations
- Tag Cloud(标签云)
- Entities Cloud(实体云,主要是人名)
有点儿像搜索引擎的搜索结果。
只不过多做了很多细化工作,而且也不是随便一个关键词就是一个Topic,需要事先算好。
Topic下的每一类数据都要事先做好排序,大胆地抛弃,大胆地去重,根据合并重复次数、普通网页反向链接次数或社会化网络引用和转发次数来做优化。
自动发现Topic并归类
Topics不是人工定义的,虽然有人工干预的成分。它包含实体发现与识别(Entity Detection and Recognition)、关系发现与识别(Relation Detection and Characterization)甚至事件发现与识别(Event Detection and Characterization)等技术点。
比较简单的做法是,利用自然语言处理中的实体识别技术,利用书名号,来确定人名、地名、组织名、书名、网络游戏名和电影名,这些显而易见都肯定是Topics。然后利用自然语言处理中的自动分类技术确定这些Topics都隶属于哪些类别。比如“徐熙娣”属于“明星娱乐”类。当然,对于娱乐明星,可以直接找百度明星列表(百度贴吧明星列表、百度新闻明星档案列表),一下子就提取到大量正确的明星名。
这里会有很多dirty work。如,语料中包含“《最终幻想》”,那么根据书名号知道“最终幻想”应该是一个Topic,接下来截取这个词出现位置前后N段/N句话作为一个字符串,送给自动分类引擎,判断属于哪一个分类,是电影还是书籍还是游戏,有时会有歧义的。也可以反过来做,先整理出某一个分类的语料,然后在这个语料集内做Topic Detection and Recognition。这个分类的语料一般由人工整理,保证语料的纯净;也可以是机器整理的。
比如说DIPRE(Dual Iterative Pattern Relation Expansion)算法,就是在输入极少的情况下,先根据已经定义好的一个可靠的数据模式,比如“Google”和“Android手机”,叫做“seed items”。拿这个seed items去搜索到同时出现这两个词的文档,然后依靠机器自动发现一些模式,再把新模式继续在对应网站里深度广度地寻找匹配的文档,反复迭代,最终能够从一两个seeds找到一大批可靠的实体关系和模式。机器自动准备分类所需语料,也有点像这个原理,但得先手工拟定一批分类。
这样,一个分类找几个核心关键字;在大量语料中找出现核心关键字的文章,再算这些文章的一些特征;然后统计一些特征权重;设一定阈值可以找到该分类文章的一些特征,同时也能找到一些出现频次较高的标签等,这些标签就可以作为Topics。
Topics之间的连接点
在Topic Page上,Related Topics列出的Topic,是跟本主题最相关的主题。
一个直截了当的做法是,首先匹配到最近包含“徐熙娣”一词的热文(这个热文集合确定是相对可靠的语料,而不是随随便便的一篇文章)中,统计一同出现过的频率最高的实体(Entity)名称,取前几个;认定这些实体名称跟“徐熙娣”有明显的联系,我们称之为Connections。能够对每一个Topic做Connections计算的应用,就叫做Connections Engine。
Connections Engine还可以计算Topics之间的关系远近,绘制为图形,用可视化的方式表示。比如,酷我的明星连连看:
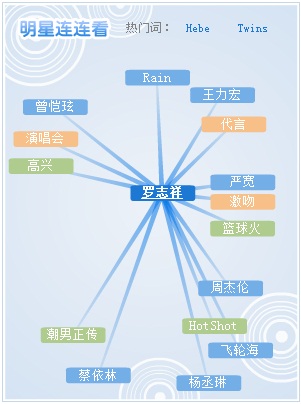
查看Cutt的“吴尊”频道,会发现文章中的“罗志祥”“高晓松”“崔始源”都没有作为标签提取出来,但Cutt里却又有罗志祥和高晓松频道,说明Cutt的标签提取并非我们自然语言处理里的传统“实体识别”,有点怪。
如何确定一个Topic映射的关键词Keywords
举个例子,“徐熙娣”这个Topic,映射的Keywords为:“小S” Or “徐熙娣”。文章中包含“小S”,也会被归类到这个Topic下。
再比如,你在Cutt.com搜索“陈莎莎”,会提示你:
简网为您找到了如下和 陈莎莎 相关的频道:陈紫函频道。
这说明,Cutt知道陈莎莎是陈紫函的别名(但Cutt不知道王静雯是王菲的曾用名(Updated:我拼写错误,应该是“王靖雯”,这样就可以找到王菲))。这两个例子属于“实体别名识别”范畴。解决这个问题,不知道Cutt实作采用什么办法,有人是利用维基百科的数据做。
Topic Engine的过去
国外做Topic Engine的,起起伏伏有很多家,比如:
daylife:参考主题Lindsay Lohan领略什么是新闻门户级的Topic Page;
曾经的boxxet;
曾经的ellerdale,现被flipboard收购;
曾经的奇虎聚客;
Evri,现在它收购了Twine.com:参考主题Orlando Bloom即可领略Topic Page的构建相当与时俱进,Connections图很快就反映出他结婚的关系;

在Twitter的HashTags数据上构建的twubs;
当然还包括曾经的玩聚,2008年前有一个版本是Topic Engine+Connection Engine,于北京奥运前夕因过于敏感而自废武功。
Topic Engine的现在
现在还活着的此类应用,有着强大的开放API,做着结构化互联网数据的基础工作,与强者结盟。
你可以用daylife的API构建出一样精彩的新闻聚合和分析小门户。比如,给定一个Topic,API返回:
Related Story、Images、Videos、Quotes、Timeline、Topics。它还可以给定一篇文章,输出相关文章。Cutt.com目前也在考虑开放像Daylife一样的API,它至少能让你搭出一个自动更新的Topic Page。
Evri的API则在语义方面更进一步,深挖洞广积粮,如下图所示:

著重于实体识别、实体关系的挖掘、关联推荐、情感分析等常规语义任务。这些语义任务要想做好,真是任重道远。
国外很多公司,都是在基础应用数据的构建上下大力气,再比如FreeBase(隶属于Google新近收购的Metaweb),国内很少见到这样做事的。
Topic Engine的未来
从过去Topic Engine的外在形式来说,不容易运营成功。有几个原因:
1、通常是只读的,用户难以围绕Topic Page做互动。
2、排列结果通常是站方算法固化的,与具体用户的行为无关。
3、实时性存在问题,当然在微博客出现之后,这个问题会比较好解决,否则就只能设定信息源是有限的A-List(指经过挑选的优质信息源),便于做快速扫描。
4、同一个Topic下堆积太多同质文章,容易让陌生用户产生焦虑感,当然这取决于下一步如何引导用户消除这种焦虑感,让用户觉得这就像RSS阅读器一样,订阅了就走,老数据无所谓,等有了新数据再回头来看。
5、对数据的分析太少,基本是资讯链接的堆砌。
6、中国大陆优质原创文章太少,同一批文章反复出现在不同频道里。
7、优质信息源太少,更新频率太低,用户关注几个Topic之后,数据更新太慢。
8、用户兴趣变化很快。比如在Google Reader里,人们常会订阅/退订一些Feed,当Feed很多时略显不便。而新一代的flipboard/TwitterTimes则根据用户自己的Twitter/Facebook生成资讯阅读界面,用户同样需要Follow/Unfollow一些id,来体现自己的兴趣变迁;Follow正确的人,也是很麻烦的。同样,在Topic Engine中你也不得不需要做一些维护工作。
未来Topic Engine是否能克服过去的这些问题,把以下几个东西结合好,也许有很好的前景:
Topic Engine+Connections Engine+Recommendation Engine+Collaborative Filtering+Real-Time Streaming
当然,Cutt.com 不仅仅是Topic Engine+Connections Engine,据谷文栋介绍,它还要承载这样的使命:『根本需要,是兴趣。我不感兴趣的,就不要来纠缠我。我们希望有这样一种方式:你只需要表明自己的兴趣,然后通过群体智慧与机器运算,让信息找到你。』它要用简单的界面,隐藏复杂的技术细节。
参考资源:
2、《用Topic组织你的兴趣》——项亮;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号