
【python】pandas库pd.read_excel操作读取excel文件参数整理与实例
除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库同样支持excel的操作;且pandas操作更加简介方便。
首先是pd.read_excel的参数:函数为:
表格数据:
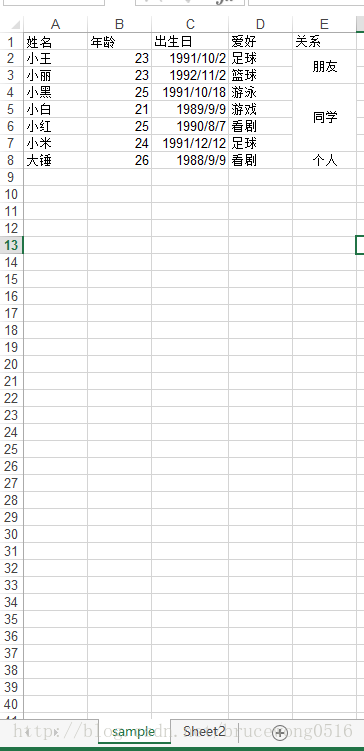

常用参数解析:
- io :excel 路径;
- sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
- header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;商务英语前景若数据不含列名,则设定 header=None;
- skiprows:省略指定行数的数据
- skip_footer:省略从尾部数的行数据
- index_col :指定列为索引列,也可以使用 u’string’
- names:指定列的名字,传入一个list数据
总体而言,pandas库的pd.read_excel和pd.read_csv的参数比较类似,且相较之前的xlrd库的读表操作更加简单,针对一般批量的数据处理最好选择pandas库操作。但是功能有待完善或者本次研究的不够深入,比如合并单元格的问题,欢迎一起讨论交流。
