
什么是操作系统
可能很多人都会说,我们平时装的windows7 windows10都是操作系统,没错,他们都是操作系统。还有没有其他的?
想想我们使用的手机,Google公司的Android系统,Apple公司笔记本上的的MacOSX、IPhone的IOS,他们都是操作系统。
那么我们想想,操作系统都可以做什么?
我们买来电脑的后第一件事情就是安装操作系统,有的电脑则在我们买来的时候已经安装好了操作系统,比如说品牌机(Dell、HP、lenovo)。
我们可以在操作系统上通过安装程序来看视频,听音乐,玩游戏、浏览网页,还可以弹出移动硬盘和U 盘、管理我们硬盘中的文件等等;我们通过操作系统来和计算机交互,系统协调我们安排给计算机的各种任务。操作系统(Operating System, OS)是指控制和管理整个计算机系统的硬件和软件资源,并合理地组织调度计算机的工作和资源的分配,以提供给用户和其他软件方便的接口和环境的程序集合。计算机操作系统是随着计算机研究和应用的发展逐步形成并发展起来的,它是计算机系统中最基本的系统软件。
我们通过操作系统来使用计算机。 知道了系统是用来做什么的,我们来了解一下系统的发展历史。(操作系统工作方式的演变——20世纪五六十年代)。
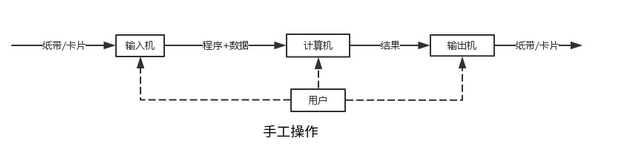
手工操作(无操作系统)
人们先把程序纸带(或卡片)装上计算机,然后启动输入机把程序和送入计算机,接着通过控制台开关启动程序运行。计算完毕,打印机输出计算结果,用户卸下并取走纸带(或卡片)。第二个用户上机,重复同样的步骤。
特点: 用户独占机器,CPU等待手工操作,CPU利用不充分。
由于手工操作的满速度和计算机的高速度之间形成了尖锐矛盾,手工操作的方式是计算机的资源利用率极低,唯一的解决办法只有摆脱手工操作,实现作业的自动过渡。
批处理系统
批处理系统: 加载计算机上的一个监督软件,在监督程序的控制下,计算机能够自动的、成批的处理一个或多个用户的作业(作业包括程序、数据、命令)。
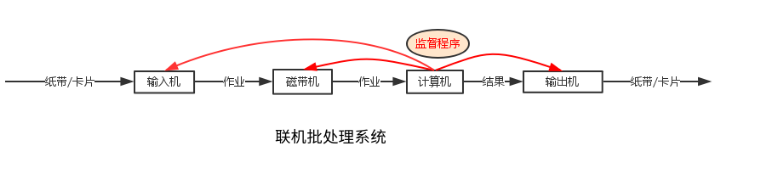
首先出现的是联机批处理系统,即作业的输入输出由CPU来处理。
联机批处理系统
在主机和输入机之间增加两个存储设备——磁带机,在监督程序的自动控制下,计算机自动完成任务。
成批的把输入机上的用户作业读入磁带,依次把磁带上的用户作业读入主机内存并执行,执行完成后把计算结果想输出机输出。 完成一批作业后,监督程度又从输入机读取作业存入磁带机。按照上面的步骤重复处理任务。监督程序不停的处理各个作业,实现了作业的自动转接,减少了作业的建立时间和手工操作时间,有效的克服了人机矛盾,提高了计算机资源的利用率。
问题: 在输入作业和输出结果时,CPU还是会处于线空闲状态,等待慢速的输入/输出设备完成工作——主机处于忙等状态。
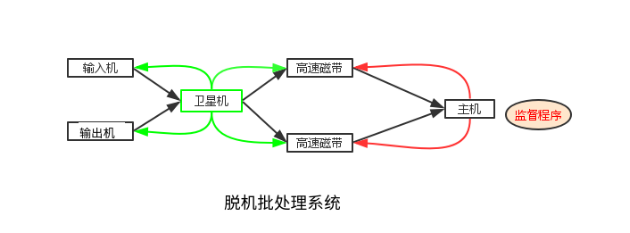
脱机批处理系统
为了克服与缓解告诉主机与慢速外设(输入输出设备),提高CPU利用率,用又引入了脱机批处理系统,即输入输出脱离主机控制。
显著特征就是:增加一台不与主机直接相连卫星机。卫星机用来从输入机上读取用户作业并放到磁带机上;将磁带机上的执行结果传给输出机。这样主机不再与慢速的输入输出设备连接。主机与卫星机两者并行工作,分工明确,可充分发挥主机的告诉计算能力。
问题:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
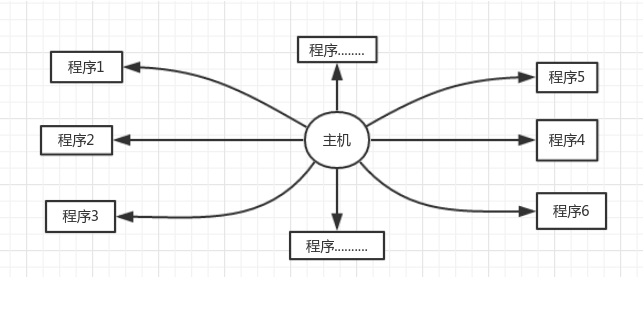
多道程序系统
多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
单道程序运行过程 :在A程序计算时,I/O空闲, A程序I/O操作时,CPU空闲(B程序也是同样);必须A工作完成后,B才能进入内存中开始工作,两者是串行的,全部完成共需时间=T1+T2。
多道程序运行过程 :将A、B两道程序同时存放在内存中,它们在系统的控制下,可相互穿插、交替地在CPU上运行:当A程序因请求I/O操作而放弃CPU时,B程序就可占用CPU运行,这样 CPU不再空闲,而正进行A I/O操作的I/O设备也不空闲,显然,CPU和I/O设备都处于“忙”状态,大大提高了资源的利用率,从而也提高了系统的效率,A、B全部完成所需时间<T1+T2。
多道程序设计技术不仅使CPU得到充分利用,同时改善I/O设备和内存的利用率,从而提高了整个系统的资源利用率和系统吞吐量(单位时间内处理作业(程序)的个数),最终提高了整个系统的效率
多道:系统内可同时容纳多个作业。这些作业放在外存中,组成一个后备队列,系统按一定的调度原则每次从后备作业队列中选取一个或多个作业进入内存运行,运行作业结束、退出运行和后备作业进入运行均由系统自动实现,从而在系统中形成一个自动转接的、连续的作业流。
成批:在系统运行过程中,不允许用户与其作业发生交互作用,即:作业一旦进入系统,用户就不能直接干预其作业的运行。批处理系统的追求目标:提高系统资源利用率和系统吞吐量,以及作业流程的自动化。批处理系统的一个重要缺点:不提供人机交互能力,给用户使用计算机带来不便。
虽然用户独占全机资源,并且直接控制程序的运行,可以随时了解程序运行情况。但这种工作方式因独占全机造成资源效率极低。
20世纪60年代中期,在前述的批处理系统中,引入多道程序设计技术后形成多道批处理系统。
多道批处理系统的一个重要缺点:不提供人机交互能力,给用户使用计算机带来不便。虽然用户独占全机资源,并且直接控制程序的运行,可以随时了解程序运行情况。但这种工作方式因独占全机造成资源效率极低。即使CPU可以1分钟运算100W次,如果作业是按照每分钟100次来做运算,资源被大大浪费。

分时系统
分时技术:把处理机的运行时间分成很短的时间片,按时间片轮流把处理机分配给各联机作业使用。若某个作业在分配给它的时间片内不能完成其计算,则该作业暂时中断,把处理机让给另一作业使用,等待下一轮时再继续其运行。由于计算机速度很快,作业运行轮转得很快,给每个用户的印象是,好象他独占了一台计算机。而每个用户可以通过自己的终端向系统发出各种操作控制命令,在充分的人机交互情况下,完成作业的运行。具有上述特征的计算机系统称为分时系统,它允许多个用户同时联机使用计算机。
问题: 无法对特殊任务做出及时响应
实时系统
虽然多道批处理系统和分时系统能获得较令人满意的资源利用率和系统响应时间,但却不能满足实时控制与实时信息处理两个应用领域的需求。于是就产生了实时系统,即系统能够及时响应随机发生的外部事件,并在严格的时间范围内完成对该事件的处理。
实时系统可分成两类:
实时控制系统。当用于飞机飞行、导弹发射等的自动控制时,要求计算机能尽快处理测量系统测得的数据,及时地对飞机或导弹进行控制,或将有关信息通过显示终端提供给决策人员。当用于轧钢、石化等工业生产过程控制时,也要求计算机能及时处理由各类传感器送来的数据,然后控制相应的执行机构。
实时信息处理系统。当用于预定飞机票、查询有关航班、航线、票价等事宜时,或当用于银行系统、情报检索系统时,都要求计算机能对终端设备发来的服务请求及时予以正确的回答。此类对响应及时性的要求稍弱于第一类。
实时操作系统的主要特点:
及时响应,每一个信息接收、分析处理和发送的过程必须在严格的时间限制内完成。
高可靠性,需采取冗余措施,双机系统前后台工作,也包括必要的保密措施等。
通用操作系统
操作系统的三种基本类型:多道批处理系统、分时系统、实时系统。
具有多种类型操作特征的操作系统。可以同时兼有多道批处理、分时、实时处理的功能,或其中两种以上的功能。
例如:实时处理+批处理=实时批处理系统。首先保证优先处理实时任务,插空进行批处理作业。常把实时任务称为前台作业,批作业称为后台作业。
再如:批处理+分时处理=分时批处理系统。即:时间要求不强的作业放入“后台”(批处理)处理,需频繁交互的作业在“前台”(以去银行办理业务,这个银行只有一个窗口可以办理业务。离业务窗口不远的地方是等候区,两者之间走路需要1分钟。分时)处理,处理机优先运行“前台”作业。
从上世纪60年代中期,国际上开始研制一些大型的通用操作系统。这些系统试图达到功能齐全、可适应各种应用范围和操作方式变化多端的环境的目标。但是,这些系统过于复杂和庞大,不仅付出了巨大的代价,且在解决其可靠性、可维护性和可理解性方面都遇到很大的困难。
我们举例来说明一下系统的发展过程:

最开始的时候,每次只能一个人去业务窗口办理业务,等第一个人业务办理完成,回到等候区后,下一个人才可以去窗口办理业务。但是,每次在用户走向/离开业务窗口的时候,都需要等到一分钟,办理一个人的业务就需要等待2分钟。如果业务处理一个人的业务需要一个小时的时候,这个问题并不明显,但是随着业务窗口办理业务的速度加快,变成10分钟处理一个业务的时候,这个问题就凸显出来了。不那里业务的速度越快,问题就明显。 ( 此时相当于操作系统的发展史中的——手工操作)。
为了改进上面的问题,安排了一个调度员T,每次调度员T从等候区叫10个人,来窗口排队办理业务,这样就相对上面来说,节省了很多时间,但是还有一个问题。在每次队伍走向业务窗口和离开窗口的时候,还是会浪费时间。(此时相当于联机批处理系统)在此基础上改进,调度员T 每次安排多个队伍,在处理第一个队伍的时候,队伍2已经被调度员T安排好, 这样就避免了在 每次队伍走向业务窗口和离开窗口的时候浪费的时间。(此时相当于联机批处理系统)如果业务窗口在为某人办理业务的时候,办理业务的人来了个电话,这个时候业务窗口就需要等待他打完电话后才能继续办理业务。
为了解决上述问题,业务窗口又进行了改进,这次是业务窗口一个让5个人同时等待窗口(而不是窗口前只等待一个人),如果在办理业务的时候,第一个人来电话,业务窗口就先暂停办理第一个人的业务,此时去办理第二个人的业务,如果第二个人此时也来了电话,业务窗口就去办理第三个人的业务。这样业务窗口就提高了工作效率。 在相同的时间内办理了更过的业务。 (此当相当于多道程序系统)办理业务的时候,一个人独占业务窗口,资源效率低。
业务窗口再次进行了改进。 业务窗口同时接待10个人,没10秒处理一个人的业务,时间到了以后,不管有没有处理完成当前业务,都会在下一个10秒钟去处理下一个人的业务,这样去轮流给10个人处理业务。随着业务窗口办理业务速度的提高,变成每一秒处理一个人的业务。这样对在也窗口前的10个人来说,他们的业务就好像被同时处理一样。(相当于分时操作系统)。如果这个时候,行长的亲戚来办理业务,但是行长亲戚不想等,希望自己的业务马上被处理。这个时候,就无法满足需求了。现在无法满足实时问题的处理。
业务窗口再次改进,对待特殊的业务需求马上处理。这样就可以对实时发生的问题进行处理,实时问题优先处理。(此时相当于实时系统)更形象的例子是,比如我们在开飞机,突然发现前面有一座大山,这个时候就需要我们马上进行规避动作,躲开大山,对于非实时系统在此时需要有一个响应时间,如果响应时间过长,飞机就会撞山。
由于办理业务的时候需要处理多种情况,将上面的各种情况进行综合,吸取各自的优点,这样业务窗口就能根据情况来处理业务。(相当于通用操作系统)早期的操作系统非常多样化,生产商生产出针对各自硬件的系统。每一个操作系统都有很不同的命令模式、操作过程和调试工具,即使它们来自同一个生产商。最能反映这一状况的是,厂家每生产一台新的机器都会配备一套新的操作系统。
同一厂家相同的操作系统
这种情况一直持续到二十世纪六十年代IBM公司开发了System/360系列机器。尽管这些机器在性能上有明显的差异,但是他们有统一的操作系统——OS/360
1965年时,AT&T公司 下贝尔实验室(Bell Labs)加入一项由奇异电子(General
Electric)和麻省理工学院(MIT)合作的计划;该计划要建立一套多使用者、多任务、多层次(multi-user、multi-
processor、multi-level)的MULTICS操作系统。
Multics
的目标是整合分时技术以及当时其他先进技术,允许用户在远程终端通过电话(拨号)登录到主机,然后可以编辑文档,阅读电子邮件,运行计算器等等。但是项目目标太过激进,进度严重滞后。最后,直到1969年AT&T
高层决定放弃这个项目。
其中有一个 叫Ken Thompson 的人 ,因为工作需要,他希望开发一个小小的作业系统,,他花了一个月的时间 在这台PDP-7上写了一个作业系统,和一些常用的工具程序,——这就是鼎鼎大名的Unics——后被改名为Unix。
到了1970年,PDP-7却只能支持两个用户 ,因为PDP-7的性能不佳,肯·汤普逊 与丹尼斯·里奇决定把第一版UNIX移植到PDP-11/20的机器上,开发第二版UNIcs。在性能提升后,真正可以提供多人同时使用, 布莱恩·柯林汉提议将它的名称改为UNIX。
Unix被称为计算机/互联网行业的基石。
肯·汤普逊的同事看到他写的程序很好用,都开始使用这个系统,中间经过了多次改版。
由于当时的机器结构不同,所以每次安装系统时,都需要重新编写一遍。第一版的Unix是使用汇编语言和B语言来开发的,B语言不够强大,所以Thompson和Ritchie对其进行了改造,并于1971年共同发明了C语言。
1973年Thompson和丹尼斯·里奇用C语言重写了UNIX。这个时候,Unix的正式版本发行了。

同年,学术界参与到UNIX的开发工作中,重要的就是加州伯克利(Berkeley)大学。伯克利大学的Bill Joy在获取了UNIX的核心源码后,着手修改成适合自己机器的版本,并且同时增加了很多工具软件与编译程序,最终将其命名为Berkeley Software Distribution(BSD)。
由于UNIX的高度可移植性与强大的性能,加上当时并没有版权纠纷,所以很多商业公司开始了UNIX操作系统的开发,例如AT&T自己的System V、IBM的AIX以及HP与DEC等公司,都采用自己的主机与自己的UNIX操作系统。但当时 并没有统一的硬件标准,不同公司生产的硬件 不一样,不同公司开发的的程序 无法兼容使用,只能运行在自己公司生产的硬件里。这个时候也没有人针对个人电脑来开发unix系统。
Windows系统、苹果系统? 先看一下下图:

一直到1979年,AT&T推出 System V 第七版 Unix ,这个时候开始支持个人电脑。出于商业上的考虑,AT&T决定收回unix的版权,最重要的就是不可对学生提供源代码。学校受到很大的冲击,教学受到影响。

这个时候有一位 Andrew Tanenbaum(谭邦宁)教授,在1984-1986年间写了一个叫Minix的Unix Like 核心程序;意思为:mini unix,并且与 unix兼容、支持X86 个人电脑。为避免版权纠纷,在编写的时候不看unix的源代码。由于谭邦宁教授 认为Minix主要用在教育事业上,所以对MInix的开发只是点到为止,不能满足用户的需求。在1988年间,Linus Torvalds进入了赫尔辛基大学,选读了计算机科学系。在就学期间,托瓦兹接触到了Unix 这个操作系统,但是使用unix需要等待,其他人使用的时候他就无法使用。他就想“我为什么不自己搞一部Unix玩?” , 不久之后,他就听说有一个类似 Unix 的系统,和 Unix 完全兼容,还可以在 Intel 386 机器上面跑的操作系统,于是他在购买了最新的 Intel 386 的个人计算机后,就立即安装了 Minix 这个操作系统。
托瓦兹跟在研究Minix的过程中,发现 Minix 虽然真的很棒,但是谭宁邦教授就是不愿意进行功能的加强,导致一堆工程师在操作系统功能上面的欲求不满! 这个时候年轻的托瓦兹就想:『既然如此,那我何不自己来改写一个我想要的操作系统?』 二是他就开始了核心程序的撰写了。到了1991年,Linus Torvalds在BBS上面贴了一则消息,宣称他以bash、gcc等工具写了一个小小的核心程序,不过还不够,他希望这个程序可以获得大家的一些修改建议,这个核心程序可以在Intel的386机器上运行。同时提供了下载地址。这让很多人感兴趣,从此便开始了Linux不平凡的路程。
Linux 应用领域
企业服务器 - 企业
嵌入式 - 手机、个人数字助理(PDA)、消费性电子产品及航空航天等领域中
桌面- 个人电脑
其他
Android
2003 安迪·鲁宾创办了Android公司 。Android--基于Linux内核的开放移动操作系统
2005年,Android公司被Google收购。
2007年11月5日,谷歌公司正式公布Android操作系统。
苹果公司
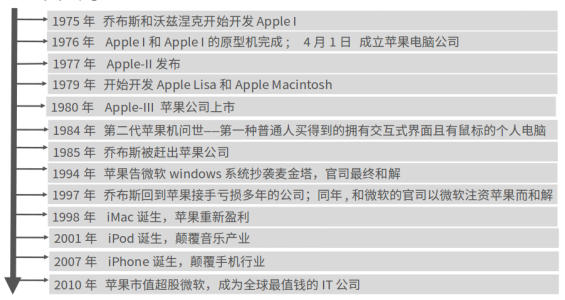
Apple-I

Macintosh,简称Mac

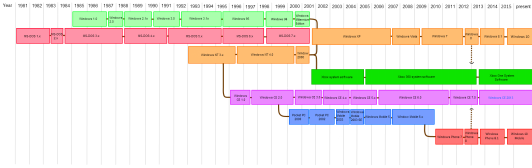
微软

Windows timeline history
苹果与微软
1973年施乐公司开发除了Alto——真正意义上的个人PC,有键盘、显示器、图形界面、以太网等。 但是并没有重视。
1979年,乔布斯听说了Alto,决定去看看,看到以后震惊了,回去就让技术人员去实现图形界面,为此还从施乐挖了好多技术人员,开发Lisa项目;然后最后失败了。但是为后来的Macintosh,积攒了好多经验。
1980年微软和IBM合作PC系统,微软以捆绑的方式在IBM-PC上预装DOS,廉价销售(5$)许可证。
1981年,乔布斯邀请盖茨看Macintosh样机,想让微软帮助Macintosh开发应用软件,盖茨看到Macintosh的图形后,也震惊了,心想,这东西要是上市,我的DOS立马完蛋,未来的天下是图形的。不过乔布斯看出了盖茨的信息,就要求微软在给苹果开发软件过程中学到的东西用于任何非苹果的设备上。但是乔布斯忽略了,不让为微软编写类似Macintosh的系统。
盖茨了解到Macintosh效法于施乐,于是也从施乐挖人,开发自己的图形系统——windows。微软把win的研发放在第一位,耽误了Macintosh的发布。
1984年Macintosh 发布,风靡世界。
1985年 windows1.0发布,乔布斯发现win很想Macintosh,就说盖茨偷了苹果的东西。
进程与线程的一个简单解释
进程(process)和线程(thread)是操作系统的基本概念,但是它们比较抽象,不容易掌握。
最近,我读到一篇材料,发现有一个很好的类比,可以把它们解释地清晰易懂。
1.

计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。
2.

假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
3.

进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
4.

一个车间里,可以有很多工人。他们协同完成一个任务。
5.

线程就好比车间里的工人。一个进程可以包括多个线程。
6.

车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
7.

可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
8.

一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。
9.

还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。
10.

这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做"信号量"(Semaphore),用来保证多个线程不会互相冲突。
不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。
11.

操作系统的设计,因此可以归结为三点:
(1)以多进程形式,允许多个任务同时运行;
(2)以多线程形式,允许单个任务分成不同的部分运行;
(3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
(完)
摘要地址:http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
学习电脑和编程语言就会遇到进程和线程,初学者往往会在此陷入迷茫和纠结中。其实弄清这两个概念不是很难。从一定意义上讲,进程就是一个应用程序在处理机上的一次执行过程,它是一个动态的概念,而线程是进程中的一部分,进程包含多个线程在运行。

通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。由于线程比进程更小,基本上不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序间并发执行的程度。

进程与线程的区别:
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
1) 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
2) 线程的划分尺度小于进程,使得多线程程序的并发性高。
3) 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
4) 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
5) 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
说说优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP(多核处理机)机器上运行,而进程则可以跨机器迁移。
进程的基本状态:
1、就绪(Ready)状态
当进程已分配到除CPU以外的所有必要资源后,只要在获得CPU,便可立即执行,进程这时的状态就称为就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将他们排成一个队列,称为就绪队列。
2、执行状态
进程已获得CPU,其程序正在执行。在单处理机系统中,只有一个进程处于执行状态;再多处理机系统中,则有多个进程处于执行状态。
3、阻塞状态
正在执行的进程由于发生某事件而暂时无法继续执行时,便放弃处理机而处于暂停状态,亦即程序的执行受到阻塞,把这种暂停状态称为阻塞状态,有时也称为等待状态或封锁状态。
三种进程之间的转换图:

几种进程间的通信方式
# 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
# 有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
# 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
# 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
# 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
#
共享内存( shared memory )
:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC
方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
# 套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
例如,我们在使用qq聊天, qq做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听其它人给你发的消息、同时还能把别人发的消息显示在屏幕上呢?你会说,操作系统不是有分时么?但我的亲,分时是指在不同进程间的分时呀, 即操作系统处理一会你的qq任务,又切换到word文档任务上了,每个cpu时间片分给你的qq程序时,你的qq还是只能同时干一件事呀。
再直白一点, 一个操作系统就像是一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间都能同时生产,你的工厂的电工只能给不同的车间分时供电,但是轮到你的qq车间时,发现只有一个干活的工人,结果生产效率极低,为了解决这个问题,应该怎么办呢?。。。。没错,你肯定想到了,就是多加几个工人,让几个人工人并行工作,这每个工人,就是线程!
什么是线程
Python线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。
threading模块对象
| 描述 | |
| Thread | 表示一个线程的执行的对象 |
| Lock | 锁原语对象 |
| RLock | 可重入锁对象。使单线程可以再次获得已经获得了的锁(递归锁定) |
| Event | 通用的条件变量。多个线程可以等待某个事件的发生,在事件发生后,所有的线程都会被激活 |
| BoundedSemaphore | 每次允许几个线程通过 |
| Timer | 等待多久在开始运行 |
例子:
import threading
import time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__ == '__main__':
t1 = threading.Thread(target=sayhi,args=(1,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(2,)) #生成另一个线程实例
t1.start() #启动线程
t2.start() #启动另一个线程
print(t1.getName()) #获取线程名
print(t2.getName())
上述代码创建了10个“前台”线程,然后控制器就交给了CPU,CPU根据指定算法进行调度,分片执行指令。
更多方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止 - join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后自动执行线程对象的run方法
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
线程锁(Lock、RLock)
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,当多个线程同时修改同一条数据时可能会出现脏数据,所以,出现了线程锁 - 同一时刻允许一个线程执行操作。
请求锁定 — 进入锁定池等待 — 获取锁 — 已锁定 — 释放锁
Lock(指令锁)是可用的最低级的同步指令。Lock处于锁定状态时,不被特定的线程拥有。Lock包含两种状态——锁定和非锁定,以及两个基本的方法。
可以认为Lock有一个锁定池,当线程请求锁定时,将线程至于池中,直到获得锁定后出池。池中的线程处于状态图中的同步阻塞状态。
构造方法:
Lock()
实例方法:
acquire([timeout]): 使线程进入同步阻塞状态,尝试获得锁定。
release(): 释放锁。使用前线程必须已获得锁定,否则将抛出异常。
没有锁
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print('--get num:',num )
time.sleep(1)
num -=1 #对此公共变量进行-1操作
num = 100 #设定一个共享变量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('final num:', num )
正常来讲,这个num结果应该是0, 但在python 2.7上多运行几次,会发现,最后打印出来的num结果不总是0,为什么每次运行的结果不一样呢? 哈,很简单,假设你有A,B两个线程,此时都 要对num 进行减1操作, 由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程去处完的结果是99,但此时B线程运算完的结果也是99,两个线程同时CPU运算的结果再赋值给num变量后,结果就都是99。那怎么办呢? 很简单,每个线程在要修改公共数据时,为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁, 这样其它线程想修改此数据时就必须等待你修改完毕并把锁释放掉后才能再访问此数据。
*注:不要在3.x上运行,不知为什么,3.x上的结果总是正确的,可能是自动加了锁
加锁版本
import time
import threading
def addNum():
global num #在每个线程中都获取这个全局变量
print('--get num:',num )
time.sleep(1)
lock.acquire() #修改数据前加锁
num -=1 #对此公共变量进行-1操作
lock.release() #修改后释放
num = 100 #设定一个共享变量
thread_list = []
lock = threading.Lock() #生成全局锁
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有线程执行完毕
t.join()
print('final num:', num )
RLock(递归锁)
RLock(可重入锁)是一个可以被同一个线程请求多次的同步指令。RLock使用了“拥有的线程”和“递归等级”的概念,处于锁定状态时,RLock被某个线程拥有。拥有RLock的线程可以再次调用acquire(),释放锁时需要调用release()相同次数。
可以认为RLock包含一个锁定池和一个初始值为0的计数器,每次成功调用 acquire()/release(),计数器将+1/-1,为0时锁处于未锁定状态。
构造方法:
RLock()
说白了就是在一个大锁中还要再包含子锁
import threading,time
def run1():
print("grab the first part data")
lock.acquire()
global num
num +=1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2+=1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res,res2)
if __name__ == '__main__':
num,num2 = 0,0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print('----all threads done---')
print(num,num2)
信号量(Semaphore)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading,time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s\n" %n)
semaphore.release()
if __name__ == '__main__':
num= 0
semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
while threading.active_count() != 1:
pass #print threading.active_count()
else:
print('----all threads done---')
print(num)
事件(event)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
Event内部包含了一个标志位,初始的时候为false。
可以使用使用set()来将其设置为true;
或者使用clear()将其从新设置为false;
可以使用is_set()来检查标志位的状态;
另一个最重要的函数就是wait(timeout=None),用来阻塞当前线程,直到event的内部标志位被设置为true或者timeout超时。如果内部标志位为true则wait()函数理解返回。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。
import threading,time
import random
def light():
if not event.isSet():
event.set() #wait就不阻塞 #绿灯状态
count = 0
while True:
if count < 10:
print('\033[42;1m--green light on---\033[0m')
elif count <13:
print('\033[43;1m--yellow light on---\033[0m')
elif count <20:
if event.isSet():
event.clear()
print('\033[41;1m--red light on---\033[0m')
else:
count = 0
event.set() #打开绿灯
time.sleep(1)
count +=1
def car(n):
while 1:
time.sleep(random.randrange(10))
if event.isSet(): #绿灯
print("car [%s] is running.." % n)
else:
print("car [%s] is waiting for the red light.." %n)
if __name__ == '__main__':
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in range(3):
t = threading.Thread(target=car,args=(i,))
t.start()
这里还有一个event使用的例子,员工进公司门要刷卡, 我们这里设置一个线程是“门”, 再设置几个线程为“员工”,员工看到门没打开,就刷卡,刷完卡,门开了,员工就可以通过。
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import threading
import time
import random
def door():
door_open_time_counter = 0
while True:
if door_swiping_event.is_set():
print("\033[32;1mdoor opening....\033[0m")
door_open_time_counter +=1
else:
print("\033[31;1mdoor closed...., swipe to open.\033[0m")
door_open_time_counter = 0 #清空计时器
door_swiping_event.wait()
if door_open_time_counter > 3:#门开了已经3s了,该关了
door_swiping_event.clear()
time.sleep(0.5)
def staff(n):
print("staff [%s] is comming..." % n )
while True:
if door_swiping_event.is_set():
print("\033[34;1mdoor is opened, passing.....\033[0m")
break
else:
print("staff [%s] sees door got closed, swipping the card....." % n)
print(door_swiping_event.set())
door_swiping_event.set()
print("after set ",door_swiping_event.set())
time.sleep(0.5)
door_swiping_event = threading.Event() #设置事件
door_thread = threading.Thread(target=door)
door_thread.start()
for i in range(5):
p = threading.Thread(target=staff,args=(i,))
time.sleep(random.randrange(3))
p.start()
条件(Condition)
可以把Condition理解为一把高级的琐,它提供了比Lock, RLock更高级的功能,允许我们能够控制复杂的线程同步问题。threadiong.Condition在内部维护一个琐对象(默认是RLock),可以在创建Condigtion对象的时候把琐对象作为参数传入。Condition也提供了acquire, release方法,其含义与琐的acquire, release方法一致,其实它只是简单的调用内部琐对象的对应的方法而已。Condition还提供了如下方法(特别要注意:这些方法只有在占用琐(acquire)之后才能调用,否则将会报RuntimeError异常。):
Condition.wait([timeout]):
wait方法释放内部所占用的琐,同时线程被挂起,直至接收到通知被唤醒或超时(如果提供了timeout参数的话)。当线程被唤醒并重新占有琐的时候,程序才会继续执行下去。
Condition.notify():
唤醒一个挂起的线程(如果存在挂起的线程)。注意:notify()方法不会释放所占用的琐。
Condition.notify_all()
Condition.notifyAll()
唤醒所有挂起的线程(如果存在挂起的线程)。注意:这些方法不会释放所占用的琐。
使得线程等待,只有满足某条件时,才释放n个线程
import threading
def run(n):
con.acquire()
con.wait()
print("run the thread: %s" %n)
con.release()
if __name__ == '__main__':
con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
while True:
inp = input('>>>')
if inp == 'q':
break
con.acquire()
con.notify(int(inp))
con.release()
def condition_func():
ret = False
inp = input('>>>')
if inp == '1':
ret = True
return ret
def run(n):
con.acquire()
con.wait_for(condition_func)
print("run the thread: %s" %n)
con.release()
if __name__ == '__main__':
con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
Timer
定时器,指定n秒后执行某操作
def hello():
print("hello, world")
t = Timer(30.0, hello)
t.start() # after 30 seconds, "hello, world" will be printed
queue队列
初识Queue模块
Queue 模块实现了多生产者、多消费者队列。它特别适用于信息必须在多个线程间安全地交换的多线程程序中。这个模块中的 Queue 类实现了所有必须的锁语义。它依赖于 Python 中的线程支持的可用性;参见threading 模块。
模块实现了三类队列,主要差别在于取得数据的顺序上。在FIFO(First In First Out,先进先出)队列中,最早加入的任务会被最先得到。在LIFO(Last In First Out,后进先出)队列中,最后加入的任务会被最先得到(就像栈一样)。在优先队列中,任务被保持有序(使用heapq模块),拥有最小值的任务(优先级最高)被最先得到。
模块实现了三类队列:FIFO(First In First Out,先进先出,默认为该队列)、LIFO(Last In First Out,后进先出)、基于优先级的队列。以下为其常用方法:
先进先出 q = Queue.Queue(maxsize)
后进先出 a = Queue.LifoQueue(maxsize)
优先级 Queue.PriorityQueue(maxsize)
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.put(item) 写入队列,timeout等待时间 非阻塞
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
Queue.put_nowait(item) 相当Queue.put(item, False)
Queue.task_done() 在完成一项工作之后,函数向任务已经完成的队列发送一个信号
Queue.join(): 实际上意味着等到队列为空,再执行别的操作
Queue 模块定义了下列的类和异常:
- class Queue.Queue(maxsize=0)
-
构造一个FIFO队列。maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。定义队列时有一个默认的参数maxsize, 如果不指定队列的长度,即manxsize=0,那么队列的长度为无限长,如果定义了大于0的值,那么队列的长度就是maxsize。
- class Queue.LifoQueue(maxsize=0)
-
构造一个LIFO队列。maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。
出现于版本2.6.
- class Queue.PriorityQueue(maxsize=0)
-
构造一个优先队列。maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。
拥有最小值的任务会被最先得到(sorted(list(entries))[0]的返回值即为拥有最小值的任务)。任务的典型模式就是如(priority_number, data)这样的元组。
出现于版本2.6.
- exception Queue.Empty
-
在空的Queue对象上调用非阻塞的get()(或者get_nowait())会抛出此异常。
- exception Queue.Full
-
在满的Queue对象上调用非阻塞的put()(或者put_nowait())会抛出此异常。
Queue 对象
Queue对象(Queue、LifoQueue和PriorityQueue)提供了下述的公共方法。
- Queue.qsize()
-
返回队列的近似大小。注意,队列大小大于0并不保证接下来的get()调用不会被阻塞,队列大小小于maxsize也不保证接下来的put()调用不会被阻塞。
- Queue.empty()
-
如果队列为空返回True,否则返回False。如果empty()返回True并不保证接下来的put()调用不会被阻塞。类似的,如果empty()返回False也不能保证接下来的get()调用不会被阻塞。
- Queue.full()
-
如果队列是满的返回True,否则返回False。如果full()返回True并不能保证接下来的get()调用不会被阻塞。类似的,如果full()返回False并不能保证接下来的put()调用不会被阻塞。
- Queue.put(item[, block[, timeout]])
-
将item放入队列中。如果可选的参数block为真且timeout为空对象(默认的情况,阻塞调用,无超时),如有必要(比如队列满),阻塞调用线程,直到有空闲槽可用。如果timeout是个正整数,阻塞调用进程最多timeout秒,如果一直无空闲槽可用,抛出Full异常(带超时的阻塞调用)。如果block为假,如果有空闲槽可用将数据放入队列,否则立即抛出Full异常(非阻塞调用,timeout被忽略)。
出现于版本2.3: timeout参数。
- Queue.put_nowait(item)
-
等同于put(item, False)(非阻塞调用)。
- Queue.get([block[, timeout]])
-
从队列中移除并返回一个数据。如果可选的参数block为真且timeout为空对象(默认的情况,阻塞调用,无超时),阻塞调用进程直到有数据可用。如果timeout是个正整数,阻塞调用进程最多timeout秒,如果一直无数据可用,抛出Empty异常(带超时的阻塞调用)。如果block为假,如果有数据可用返回数据,否则立即抛出Empty异常(非阻塞调用,timeout被忽略)。
出现于版本2.3: timeout参数。
- Queue.get_nowait()
-
等同于get(False)(非阻塞调用)。
为了跟踪入队任务被消费者线程完全的处理掉,Queue对象提供了两个额外的方法。
- Queue.task_done()
-
意味着之前入队的一个任务已经完成。由队列的消费者线程调用。每一个get()调用得到一个任务,接下来的task_done()调用告诉队列该任务已经处理完毕。
如果当前一个join()正在阻塞,它将在队列中的所有任务都处理完时恢复执行(即每一个由put()调用入队的任务都有一个对应的task_done()调用)。
如果该方法被调用的次数多于被放入队列中的任务的个数,ValueError异常会被抛出。
出现于版本2.5。
- Queue.join()
-
阻塞调用线程,直到队列中的所有任务被处理掉。
只要有数据被加入队列,未完成的任务数就会增加。当消费者线程调用task_done()(意味着有消费者取得任务并完成任务),未完成的任务数就会减少。当未完成的任务数降到0,join()解除阻塞。
出现于版本2.5。
import queue # q = queue.Queue(2) # # q.put(1) # q.put(2) # #q.put(3) # #q.put_nowait(3) # # print(q.empty()) # print(q.full()) # # print(q.get()) # print(q.get()) 权重: q = queue.PriorityQueue() # q.put((3,'aaaaa')) # q.put((3,'bbbbb')) # q.put((1,'ccccc')) # q.put((3,'ddddd')) q.put([6,'alex']) q.put([3,'jack']) q.put([5,'rain']) print(q.get()) print(q.get())
GIL,全局解释器锁
总结:
多进程,多线程,提供并发
IO密集型:多线程
计算密集型:多进程
GIL是什么
首先需要明确的一点是 GIL 并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把 GIL 归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
那么CPython实现中的GIL又是什么呢?GIL全称 Global Interpreter Lock 为了避免误导,我们还是来看一下官方给出的解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
好吧,是不是看上去很糟糕?一个防止多线程并发执行机器码的一个Mutex,乍一看就是个BUG般存在的全局锁嘛!别急,我们下面慢慢的分析。
为什么会有GIL
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。 即使在CPU内部的Cache也不例外 ,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。 而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,本且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
GIL的影响
从上文的介绍和官方的定义来看,GIL无疑就是一把全局排他锁。毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序。那么读者就会说了,全局锁只要释放的勤快效率也不会差啊。只要在进行耗时的IO操作的时候,能释放GIL,这样也还是可以提升运行效率的嘛。或者说再差也不会比单线程的效率差吧。理论上是这样,而实际上呢?Python比你想的更糟。
总结
Python GIL其实是功能和性能之间权衡后的产物,它尤其存在的合理性,也有较难改变的客观因素。从本分的分析中,我们可以做以下一些简单的总结:
- 因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能
- 如果对并行计算性能较高的程序可以考虑把核心部分也成C模块,或者索性用其他语言实现
- GIL在较长一段时间内将会继续存在,但是会不断对其进行改进
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
下面来学习一个最基本的生产者消费者模型的例子
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import threading
import queue
import time
def consumer(name):
while True:
print('%s 取到骨头[%s]并吃了' % (name,q.get()))
time.sleep(0.5)
q.task_done()
def producer(name):
count = 0
#while q.qsize() <5:
for i in range(10):
print('%s生成了骨头' %name,count)
q.put(count)
count += 1
time.sleep(0.3)
q.join()
print("------吃完了-------")
#生成一个队列
q = queue.Queue(maxsize=4)
#生成两个线程
p = threading.Thread(target=producer,args=('Tom',))
#p2 = threading.Thread(target=producer,args=('Tom',))
c = threading.Thread(target=consumer,args=('Jack',))
p.start()
#p2.start()
c.start()
第二个:
import time,random
import queue,threading
q = queue.Queue()
def Producer(name):
count = 0
while count <20:
time.sleep(random.randrange(3))
q.put(count)
print('Producer %s has produced %s baozi..' %(name, count))
count +=1
def Consumer(name):
count = 0
while count <20:
time.sleep(random.randrange(4))
if not q.empty():
data = q.get()
print(data)
print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data))
else:
print("-----no baozi anymore----")
count +=1
p1 = threading.Thread(target=Producer, args=('A',))
c1 = threading.Thread(target=Consumer, args=('B',))
p1.start()
c1.start()

#!/usr/bin/env python
#-*- coding:utf-8 -*-
# !/usr/bin/env python
import threading, time
import queue # 导入消息队列模块
import random # 导入随机数模块,是为了模拟生产者与消费者速度不一致的情形
q = queue.Queue() # 实例化一个对象
def Producer(name): # 生产者函数
for i in range(20):
q.put(i) # 将结果放入消息队列中
print('\033[32;1mProducer %s has made %s baozi....\033[0m' % (name, i))
time.sleep(random.randrange(3)) # 生产者的生产速度,3s内
def Consumer(name): # 消费者函数
count = 0
while count < 20:
data = q.get() # 取用消息队列中存放的结果
print('\033[31;1mConsumer %s has eatem %s baozi...chihuo...\033[0m' % (name, data))
count += 1
time.sleep(random.randrange(4)) # 消费者的消费速度,4s内
p = threading.Thread(target=Producer, args=('Tom',))
c = threading.Thread(target=Consumer, args=('Jack',))
p.start()
c.start()
利用这个程序,很好地模拟了前面“厨师做包子顾客吃包子”的例子,而从程序的执行结果中也可以看出,线程的执行是异步的,尽管如此,数据还是进行了交互,作用是:在多线程和多线程之间进行数据交互的时候,不会出现数据的阻塞。
Process
创建进程的类:Process([group [, target [, name [, args [, kwargs]]]]]),target表示调用对象,args表示调用对象的位置参数元组。kwargs表示调用对象的字典。name为别名。group实质上不使用。
方法:is_alive()、join([timeout])、run()、start()、terminate()。其中,Process以start()启动某个进程。
属性:authkey、daemon(要通过start()设置)、exitcode(进程在运行时为None、如果为–N,表示被信号N结束)、name、pid。其中daemon是父进程终止后自动终止,且自己不能产生新进程,必须在start()之前设置。
例1.1:创建函数并将其作为单个进程
import multiprocessing
import time
def worker(interval):
n = 5
while n > 0:
print("The time is {0}".format(time.ctime()))
time.sleep(interval)
n -= 1
if __name__ == "__main__":
p = multiprocessing.Process(target=worker, args=(3,))
p.start()
print("p.pid:", p.pid)
print("p.name:", p.name)
print("p.is_alive:", p.is_alive())
结果:
p.pid: 15084
p.name: Process-1
p.is_alive: True
The time is Mon Dec 12 11:31:52 2016
The time is Mon Dec 12 11:31:55 2016
The time is Mon Dec 12 11:31:58 2016
The time is Mon Dec 12 11:32:01 2016
The time is Mon Dec 12 11:32:04 2016
多进程multiprocessing
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
结果:
Process (876) start... I (876) just created a child process (877). I am child process (877) and my parent is 876.
由于Windows没有fork调用,上面的代码在Windows上无法运行。由于Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的,推荐大家用Mac学Python!
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?
由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
执行结果如下:
Parent process 928. Process will start. Run child process test (929)... Process end.
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pipe
Pipe方法返回(conn1, conn2)代表一个管道的两个端。Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说conn1和conn2均可收发。duplex为False,conn1只负责接受消息,conn2只负责发送消息。
import multiprocessing
import time
def proc1(pipe):
while True:
for i in xrange(10000):
print "send: %s" %(i)
pipe.send(i)
time.sleep(1)
def proc2(pipe):
while True:
print "proc2 rev:", pipe.recv()
time.sleep(1)
def proc3(pipe):
while True:
print "PROC3 rev:", pipe.recv()
time.sleep(1)
if __name__ == "__main__":
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc1, args=(pipe[0],))
p2 = multiprocessing.Process(target=proc2, args=(pipe[1],))
#p3 = multiprocessing.Process(target=proc3, args=(pipe[1],))
p1.start()
p2.start()
#p3.start()
p1.join()
p2.join()
#p3.join()
Pool
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。进程池设置最好等于CPU核心数量
构造方法:
Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
processes :使用的工作进程的数量,如果processes是None那么使用 os.cpu_count()返回的数量。
initializer: 如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。
maxtasksperchild:工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。
context: 用在制定工作进程启动时的上下文,一般使用 multiprocessing.Pool() 或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context
方法:
-
apply(func[, args[, kwds]]) :使用arg和kwds参数调用func函数,结果返回前会一直阻塞,由于这个原因,apply_async()更适合并发执行,另外,func函数仅被pool中的一个进程运行。
-
apply_async(func[, args[, kwds[, callback[, error_callback]]]]) : apply()方法的一个变体,会返回一个结果对象。如果callback被指定,那么callback可以接收一个参数然后被调用,当结果准备好回调时会调用callback,调用失败时,则用error_callback替换callback。 Callbacks应被立即完成,否则处理结果的线程会被阻塞。
-
close() : 阻止更多的任务提交到pool,待任务完成后,工作进程会退出。
-
terminate() : 不管任务是否完成,立即停止工作进程。在对pool对象进程垃圾回收的时候,会立即调用terminate()。
-
join() : wait工作线程的退出,在调用join()前,必须调用close() or terminate()。这样是因为被终止的进程需要被父进程调用wait(join等价与wait),否则进程会成为僵尸进程
进程池中有两个方法:
- apply
- apply_async
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
执行结果如下:
Parent process 669. Waiting for all subprocesses done... Run task 0 (671)... Run task 1 (672)... Run task 2 (673)... Run task 3 (674)... Task 2 runs 0.14 seconds. Run task 4 (673)... Task 1 runs 0.27 seconds. Task 3 runs 0.86 seconds. Task 0 runs 1.41 seconds. Task 4 runs 1.91 seconds. All subprocesses done.
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
import subprocess
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)
运行结果:
$ nslookup www.python.org Server: 192.168.19.4 Address: 192.168.19.4#53 Non-authoritative answer: www.python.org canonical name = python.map.fastly.net. Name: python.map.fastly.net Address: 199.27.79.223 Exit code: 0
如果子进程还需要输入,则可以通过communicate()方法输入:
import subprocess
print('$ nslookup')
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))
print('Exit code:', p.returncode)
上面的代码相当于在命令行执行命令nslookup,然后手动输入:
set q=mx python.org exit
运行结果如下:
$ nslookup Server: 192.168.19.4 Address: 192.168.19.4#53 Non-authoritative answer: python.org mail exchanger = 50 mail.python.org. Authoritative answers can be found from: mail.python.org internet address = 82.94.164.166 mail.python.org has AAAA address 2001:888:2000:d::a6 Exit code: 0
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
运行结果如下:
Process to write: 50563 Put A to queue... Process to read: 50564 Get A from queue. Put B to queue... Get B from queue. Put C to queue... Get C from queue.
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所有,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
小结
在Unix/Linux下,可以使用fork()调用实现多进程。
要实现跨平台的多进程,可以使用multiprocessing模块。
进程间通信是通过Queue、Pipes等实现的。
Python3 多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 "_thread"。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
Python中使用线程有两种方式:函数或者用类来包装线程对象。
函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程。语法如下:
_thread.start_new_thread ( function, args[, kwargs] )
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
实例:
#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass
执行以上程序输出结果如下:
Thread-1: Wed Apr 6 11:36:31 2016 Thread-1: Wed Apr 6 11:36:33 2016 Thread-2: Wed Apr 6 11:36:33 2016 Thread-1: Wed Apr 6 11:36:35 2016 Thread-1: Wed Apr 6 11:36:37 2016 Thread-2: Wed Apr 6 11:36:37 2016 Thread-1: Wed Apr 6 11:36:39 2016 Thread-2: Wed Apr 6 11:36:41 2016 Thread-2: Wed Apr 6 11:36:45 2016 Thread-2: Wed Apr 6 11:36:49 2016
执行以上程后可以按下 ctrl-c to 退出。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
执行结果如下:
thread MainThread is running... thread LoopThread is running... thread LoopThread >>> 1 thread LoopThread >>> 2 thread LoopThread >>> 3 thread LoopThread >>> 4 thread LoopThread >>> 5 thread LoopThread ended. thread MainThread ended.
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
线程模块
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
来看看多个线程同时操作一个变量怎么把内容给改乱了:
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
balance = balance + n
也分两步:
- 计算
balance + n,存入临时变量中; - 将临时变量的值赋给
balance。
也就是可以看成:
x = balance + n balance = x
由于x是局部变量,两个线程各自都有自己的x,当代码正常执行时:
初始值 balance = 0 t1: x1 = balance + 5 # x1 = 0 + 5 = 5 t1: balance = x1 # balance = 5 t1: x1 = balance - 5 # x1 = 5 - 5 = 0 t1: balance = x1 # balance = 0 t2: x2 = balance + 8 # x2 = 0 + 8 = 8 t2: balance = x2 # balance = 8 t2: x2 = balance - 8 # x2 = 8 - 8 = 0 t2: balance = x2 # balance = 0 结果 balance = 0
但是t1和t2是交替运行的,如果操作系统以下面的顺序执行t1、t2:
初始值 balance = 0 t1: x1 = balance + 5 # x1 = 0 + 5 = 5 t2: x2 = balance + 8 # x2 = 0 + 8 = 8 t2: balance = x2 # balance = 8 t1: balance = x1 # balance = 5 t1: x1 = balance - 5 # x1 = 5 - 5 = 0 t1: balance = x1 # balance = 0 t2: x2 = balance - 8 # x2 = 0 - 8 = -8 t2: balance = x2 # balance = -8 结果 balance = -8
究其原因,是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:
balance = 0
lock = threading.Lock()
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为:
开启线程: Thread-1 开启线程: Thread-2 Thread-1: Wed Apr 6 11:52:57 2016 Thread-1: Wed Apr 6 11:52:58 2016 Thread-1: Wed Apr 6 11:52:59 2016 Thread-2: Wed Apr 6 11:53:01 2016 Thread-2: Wed Apr 6 11:53:03 2016 Thread-2: Wed Apr 6 11:53:05 2016 退出主线程
多核CPU
如果你不幸拥有一个多核CPU,你肯定在想,多核应该可以同时执行多个线程。
如果写一个死循环的话,会出现什么情况呢?
打开Mac OS X的Activity Monitor,或者Windows的Task Manager,都可以监控某个进程的CPU使用率。
我们可以监控到一个死循环线程会100%占用一个CPU。
如果有两个死循环线程,在多核CPU中,可以监控到会占用200%的CPU,也就是占用两个CPU核心。
要想把N核CPU的核心全部跑满,就必须启动N个死循环线程。
试试用Python写个死循环:
import threading, multiprocessing
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()):
t = threading.Thread(target=loop)
t.start()
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
小结
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。
进程池
Python进程池 前面我们讲过CPU在某一时刻只能执行一个进程,那为什么上面10个进程还能够并发执行呢?实际在CPU在处理上面10个进程时是在不停的切换执行这10个进程,但由于上面10个进程的程序代码都是十分简单的,并没有涉及什么复杂的功能,并且,CPU的处理速度实在是非常快,所以这样一个过程在我们人为感知里确实是在并发执行的,实际只不过是CPU在不停地切换而已,这是通过增加切换的时间来达到目的的。 10个简单的进程可以产生这样的效果,那试想一下,如果我有100个进程需要CPU执行,但因为CPU还要进行其它工作,只能一次再处理10个进程(切换处理),否则有可能会影响其它进程工作,这下可怎么办?这时候就可以用到Python中的进程池来进行调控了,在Python中,可以定义一个进程池和这个池的大小,假如定义进程池的大小为10,那么100个进程可以分10次放进进程池中,然后CPU就可以10次并发完成这100个进程了。
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply
- apply_async
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(2)
return i+100
def Bar(arg):
print('-->exec done:',arg)
pool = Pool(5)
for i in range(10):
pool.apply_async(func=Foo, args=(i,),callback=Bar)
#pool.apply(func=Foo, args=(i,))
print('end')
pool.close()
pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
