

分布式爬虫—原理
原理
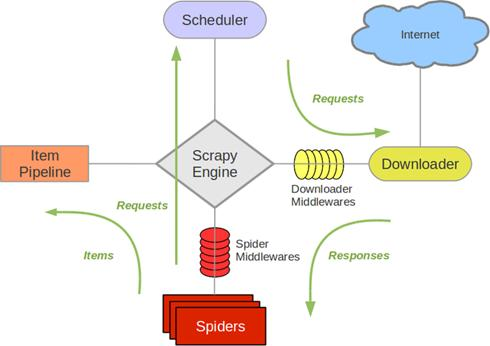
这就是scrapy爬虫框架的流程
从下往上看,Spiders生成的请求经由Scheduler调度器发送给Downloader下载器,Downloader下载器从internet下载所需要的网络数据,返回response给Spiders,Spiders接着把数据放进item容器
而scrapy-redis就是建立一个redis队列,调度器把Spiders生成的请求发送给redis队列,再用Scheduler从队列里取出请求,其他爬虫也可以从队列中取出请求。
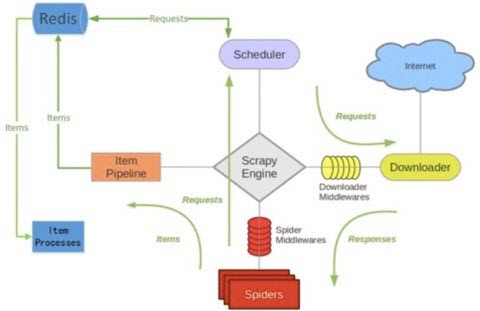
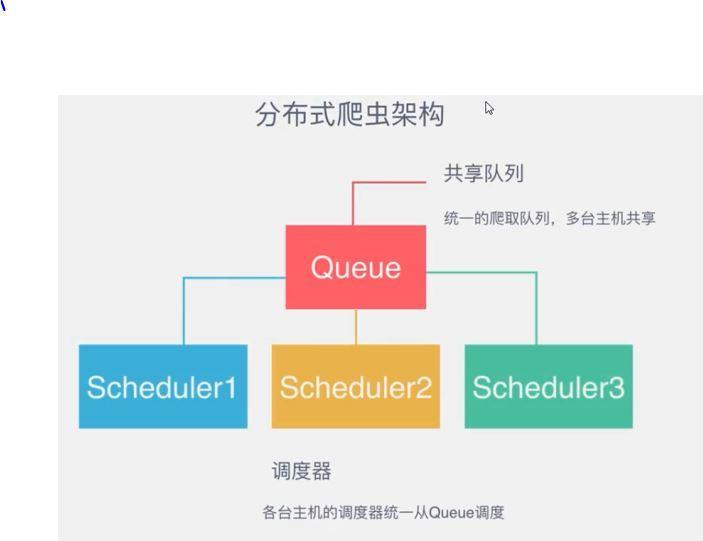
每一个爬虫的调度器Scheduler都从队列中取出请求和存入请求,这样就实现多个爬虫,多台机器同时爬取的目标;
scrapy-redis分布式框架还有两个常用的功能,去重和启动判断(可以接着暂停的地方继续爬)。
scrapy-redis分布式框架还有两个常用的功能,去重和启动判断(可以接着暂停的地方继续爬)。
