WeCount软件测试
WeCount软件测试
github项目地址:https://github.com/inewRichard/WordCountPro
PSP表格:
| PSP2.1 | PSP |
预估耗时 (分钟) |
实际耗时
(分钟) |
| Planning | 计划 | 20 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 20 | 30 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 10 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 (和同事审核设计文档) | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 50 | 50 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 20 | 20 |
| Test Report | 测试报告 | 50 | 50 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 5 |
| 合计 | 360 | 370 |
接口实现:
我主要负责核心处理:
我的设计思想是先获取经过处理后的单词数据,对出现的各个单词分配一个计数值,然后利用排序算法得出单词的频率排序
代码如下:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.FilenameFilter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
class doc {
static String name;
static String text;
static String word="";
static String[] stoplist;
public static int linecount =1,allwordcount = 0,wordcount =0,symbolcount=0,codeline=0,nullline = 0,balaline =666;
static boolean[] temp ={};
public doc(){}
public doc(String n,String t,boolean[] para){
name = n;
text = t;
temp = para;
cal();
}
public String mes(){
String message= "name:"+name+"\n";
if(temp[2] ==true)
message +="\tsymbolcount:"+symbolcount;
if(temp[1] == true)
message +="\twordcount:"+wordcount;
if(temp[0]==true)
message +="\tlinecount:"+linecount;
if(temp[3] == true)
message +="\tcodeline:"+codeline+"\tnullline:"+nullline+"\tbalaline:"+balaline;
return message;
}
public static boolean isChinese(char c) {
return c >= 0x4E00 && c <= 0x9FA5;// 根据字节码判断
}
public static boolean isword(char c) {
return (c>='A'&&c<='Z')||(c>='a'&&c<='z')||(c>='0'&&c<='9');
}
public static boolean isnum(char c) {
return (c>='0'&&c<='9');
}
public static boolean issymbol(char c){
return !(isChinese(c)||isword(c));
}
private static boolean isStop(String s){
word = "";
boolean isstop = false;
if(doc.stoplist == null)
return false;
for(String sp:doc.stoplist){
if(isequal(sp,s)){
isstop = true;
break;
}
}
return isstop;
}
private static boolean isequal(String sp, String s) {
// TODO Auto-generated method stub
if(sp.length() != s.length())
return false;
for(int i=0;i<sp.length();i++){
if(sp.charAt(i)!=s.charAt(i))
return false;
}
return true;
}
public static void cal(){
ArrayList linewords = new ArrayList();
ArrayList<String> line = new ArrayList<String>();
String ts ="";
int lineb=0;
boolean isaword = false;
//多少行是指的多少回车吗
//单词数 ,如果是汉语呢,那应该是一个字是一个词咯?
for(int i =0;i<text.length();++i){
char temp = text.charAt(i);
ts+=temp;
if(temp=='\n'){
linewords.add(allwordcount-lineb);
lineb =allwordcount;
linecount +=1;
line.add(ts);
ts="";
}
else if(isword(temp)&&!isnum(temp)){
isaword = true;
}
else if(isChinese(temp)){
allwordcount+=1;
if(!isStop(""+temp));
wordcount+=1;
if(isaword)
allwordcount +=1;
if(isaword&&!isStop(word))
wordcount +=1;
isaword = false;
}
else if(issymbol(temp))
{
if(isaword)
allwordcount +=1;
if(isaword&&!isStop(word))
wordcount +=1;
isaword = false;
if(issymbol(temp)){
symbolcount +=1;
}
}
if(isaword)
word +=temp;
}
line.add(ts);
linewords.add(allwordcount-lineb);
allwordcount = isaword?allwordcount+1:allwordcount;
if(isaword&&!isStop(word))
wordcount++;
/*for(int i=0;i<line.size();++i){ //solve the line problem
System.out.println(line.get(i));
}*/
for(int i =0;i<linewords.size();i++){ //codeline,line and line you ***
if((int)linewords.get(i)>1){
codeline ++;
}else if(isnullline(line.get(i)))
nullline ++;
else if(iszhushi(line.get(i))){
balaline ++;
}
}
}
private static boolean iszhushi(String string) {
// TODO Auto-generated method stub
return false;
}
private static boolean isnullline(String str) {
// TODO Auto-generated method stub
boolean flag = false;
for(int i=0;i<str.length();i++){
if((!(str.charAt(i)==' '||str.charAt(i) =='\r'||str.charAt(i) =='\t'||str.charAt(i)=='\n'))&&!flag){
flag = true;
}else if((!(str.charAt(i)==' '||str.charAt(i) =='\r'||str.charAt(i) =='\t'||str.charAt(i)=='\n'))&&flag){
return false;
}
}
return true;
}
}
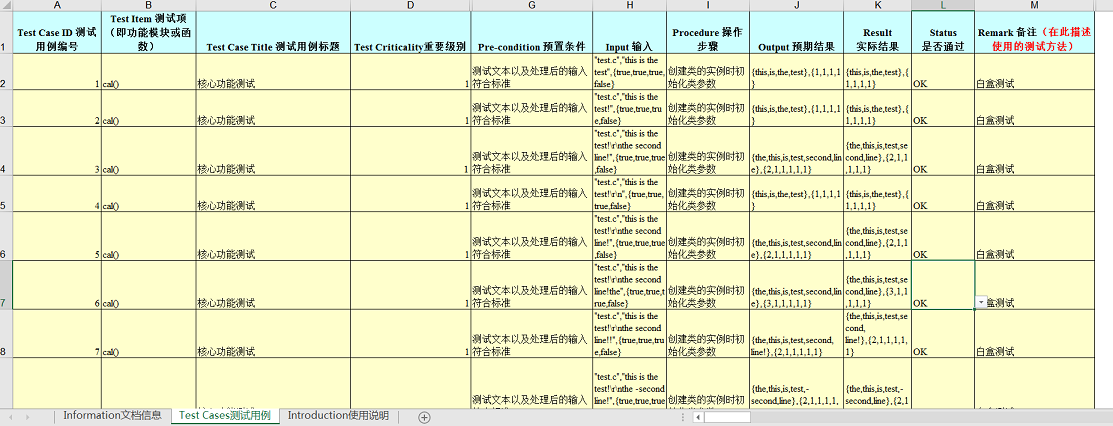
测试用例的设计:
白盒测试,主要是根据输入的字符串数组的情况进行测试,比如字符之间是否有“-”连接,是否有其他非字母数字符号,以及单词的频率变化对输出结果的印象。
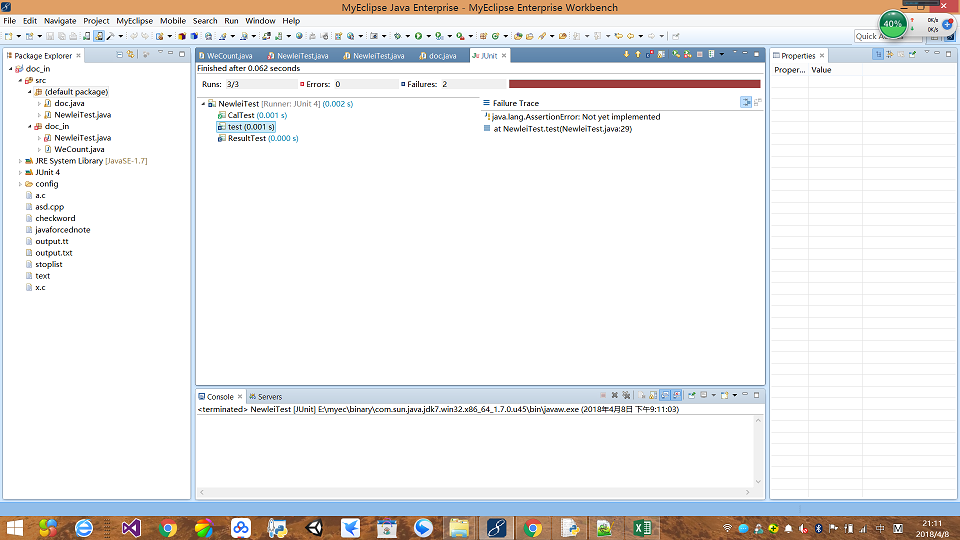
单元测试代码示例如下:
import static org.junit.Assert.*;
import org.junit.Before;
import org.junit.Test;
public class NewleiTest {
static boolean[] para= {true,true,true,false};
private static doc Doc=new doc("test.c","this is the test!\r\nthe second line!",para);
@Before
public void setUp() throws Exception {
}
@Test
public void CalTest(){
Doc.cal();
}
@Test
public void ResultTest(){
assertEquals(7, Doc.wordcount);
}
@Test
public void test() {
fail("Not yet implemented");
}
}
黑盒测试:
黑盒测试是在模块封装的情况下对功能模块进行测试,我这里黑盒测试主要是对于输入参数变化的测试,相关的测试用例在我项目的测试清单里。
测试用例清单:
测试脚本运行截图: