

Python数据分析Pandas的编程经验总结
Pandas的api 参考手册DataFrame部分:https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
数据处理部分:
待处理的数据:
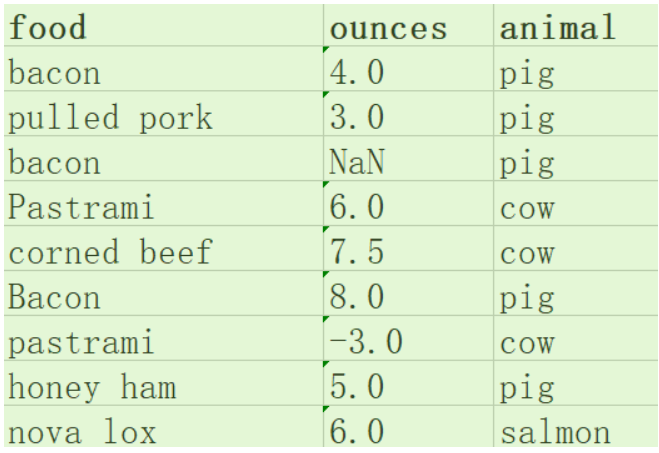
处理要求:1.food栏,大小写统一,2.删除NaN行,3.把ounces中的负值取绝对值,4.把food名称相同的字段合并,合并后ounces的值为合并前他们的平均值
代码如下:
# -*- coding: utf-8 -*- import pandas as pd df = pd.read_csv('E:/python3Project/11.csv') #print(df) df['food'] = df['food'].str.lower() #统一大小写字母 df.dropna(inplace=True) #删除数据缺失的记录 print(df) df['ounces']=df['ounces'].apply(lambda a:abs(a)) #负值不合法,取绝对值 #print(df) #查找food重复的记录,分组求其平均值 #print(df['food'].duplicated(keep=False)) #d_rows = df[df['food'].duplicated(keep=False)] # keep=False的意思是把所有的food列下重复的字段都找出来 #print(d_rows) #g_items = d_rows.groupby('food').mean() # 学学groupBy #print(g_items) #g_items['food']=g_items.index #效果就是新增一列food #print(g_items) #把第一个出现的bacon替换成平均值 df.loc[0,'ounces']=df[df['food'].isin(['bacon'])].mean()['ounces'] # 删除第二个ounce df.drop(df.index[4],inplace=True) print(df) df.index =range(len(df)) # 重新把row的index排列一下,按照连贯顺序,从小到大 print(df) #把第一个出现的pastrami替换成平均值 df.loc[0,'ounces']=df[df['food'].isin(['pastrami'])].mean()['ounces'] # 删除第二个ounce df.drop(df.index[4],inplace=True) print(df) df.index =range(len(df)) # 重新把row的index排列一下,按照连贯顺序,从小到大 print(df)

