

C4.5决策树在ID3决策树的基础之上稍作改进,请先阅读ID3决策树。
C4.5克服了ID3的2个缺点:
1.用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性
2.不能处理连贯属性
| Outlook | Temperature | Humidity | Windy | PlayGolf? |
| sunny | 85 | 85 | FALSE | no |
| sunny | 80 | 90 | TRUE | no |
| overcast | 83 | 86 | FALSE | yes |
| rainy | 70 | 96 | FALSE | yes |
| rainy | 68 | 80 | FALSE | yes |
| rainy | 65 | 70 | TRUE | no |
| overcast | 64 | 65 | TRUE | yes |
| sunny | 72 | 95 | FALSE | no |
| sunny | 69 | 70 | FALSE | yes |
| rainy | 75 | 80 | FALSE | yes |
| sunny | 75 | 70 | TRUE | yes |
| overcast | 72 | 90 | TRUE | yes |
| overcast | 81 | 75 | FALSE | yes |
| rainy | 71 | 91 | TRUE | no |
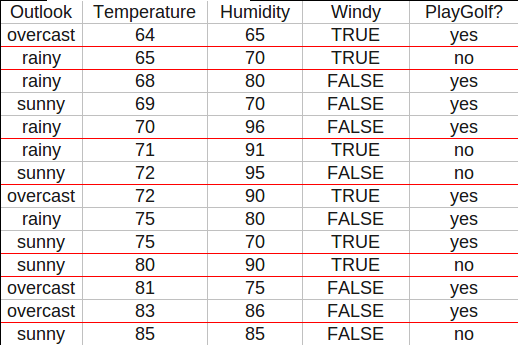
Outlook和Windy取离散值,Temperature和Humidity则取连续值。
对于离散属性V,ID3中计算的是“信息增益”,C4.5中则计算“信息增益率”:
$IG\_ratio=\frac{IG(V)}{H(V)}$
$H(V)=-\sum_j{p(v_j)logp(v_j)}$
vj表示属性V的各种取值,在ID3中用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性,在C4.5中由于除以了H(V),可以削弱这种作用。
C4.5是如何处理连续属性的呢?实际上它先把连续属性转换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化的方法:<=vj的分到左子树,>vj的分到右子树。计算这N-1种情况下最大的信息增益率。
在离散属性上只需要计算1次信息增益率,而在连续属性上却需要计算N-1次,计算量是相当大的。有办法可以减少计算量。对于连续属性先进行排序,只有在决策属性发生改变的地方才需要切开。比如对Temperature进行排序
本来有13种离散化的情况,现在只需计算7种。如果利用增益率来选择连续值属性的分界点,会导致一些副作用。分界点将样本分成两个部分,这两个部分的样本个数之比也会影响增益率。根据增益率公式,我们可以发现,当分界点能够把样本分成数量相等的两个子集时(我们称此时的分界点为等分分界点),增益率的抑制会被最大化,因此等分分界点被过分抑制了。子集样本个数能够影响分界点,显然不合理。因此在决定分界点是还是采用增益这个指标,而选择属性的时候才使用增益率这个指标。这个改进能够很好得抑制连续值属性的倾向。当然还有其它方法也可以抑制这种倾向,比如MDL。
Tree-Growth终止的条件以及剪枝策略很多,在CART树中已讲了一些。每个叶子上都是“纯的”不见得就是好事,那样会过拟合。还有一个方法是叶子节点上覆盖的样本个数小于一个阈值时停止Tree-Growth。
在《CART树》中介绍了基于代价复杂性的剪枝法,剪枝的目的也是为了避免过拟合。
第一种方法,也是最简单的方法,称之为基于误判的剪枝。这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,并且该子树里面没有包含另外一个具有类似特性的子树(所谓类似的特性,指的就是把子树替换成叶子节点后,其测试数据集误判率降低的特性),那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
第一种方法很直接,但是需要一个额外的测试数据集,能不能不要这个额外的数据集呢?为了解决这个问题,于是就提出了悲观剪枝。悲观剪枝就是递归得估算每个内部节点所覆盖样本节点的误判率。剪枝后该内部节点会变成一个叶子节点,该叶子节点的类别为原内部节点的最优叶子节点所决定。然后比较剪枝前后该节点的错误率来决定是否进行剪枝。该方法和前面提到的第一种方法思路是一致的,不同之处在于如何估计剪枝前分类树内部节点的错误率。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N。这个0.5就是惩罚因子,那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为$\frac{\sum{E_i+0.5*L}}{\sum{N_i}}$。这样的话,我们可以看到一颗子树虽然具有多个子节点,但由于加上了惩罚因子,所以子树的误判率计算未必占到便宜。剪枝后内部节点变成了叶子节点,其误判个数J也需要加上一个惩罚因子,变成J+0.5。那么子树是否可以被剪枝就取决于剪枝后的错误J+0.5在$\sum{E_i+0.5*L}$的标准误差内。对于样本的误差率e,我们可以根据经验把它估计成各种各样的分布模型,比如是二项式分布,比如是正态分布。
那么一棵树错误分类一个样本值为1,正确分类一个样本值为0,该树错误分类的概率(误判率)为e(e为分布的固有属性,可以通过$\frac{\sum{E_i+0.5*L}}{\sum{N_i}}$统计出来),那么树的误判次数就是伯努利分布,我们可以估计出该树的误判次数均值和标准差:
$E(subtree\_err\_count)=N*e$
$var(subtree\_err\_count)=\sqrt{N*e*(1-e)}$
把子树替换成叶子节点后,该叶子的误判次数也是一个伯努利分布,其概率误判率e为(E+0.5)/N,因此叶子节点的误判次数均值为
$E(leaf\_err\_count)=N*e$
这里我们采用一种保守的分裂方案,即有足够大的置信度保证分裂后准确率比不分裂时的准确率高时才分裂,否则就不分裂--也就是应该剪枝。如果要分裂(即不剪枝)至少要保证分裂后的误判数$E(subtree\_err\_count)$要小于不分裂的误判数$E(leaf\_err\_count)$,而且为了保证足够高的置信度,这里甚至要示
$$E(subtree\_err\_count)+var(subtree\_err\_count)<E(leaf\_err\_count)$$
这里加了一个标准差可以有95%的置信度。
反之就是不分裂--即剪枝的条件:
$$E(subtree\_err\_count)+var(subtree\_err\_count)>E(leaf\_err\_count)$$

比如T4这棵子树的误差率:
$\frac{(3+2)+0.5*3}{16}=\frac{6.5}{16}=0.40625$
子树误差率的标准误差:
$\sqrt{16*0.40625*(1-0.40625)}=1.96$
子树替换为一个叶节点后,其误差率为:
$\frac{7+0.5}{16}=0.46875$
因为$16*0.40625+1.96=6.5+1.96=8.46>16*0.46875=7.5$,所以应该把T4的所有子节点全部剪掉,T4变成一个叶子节点。
本文来自博客园,作者:高性能golang,转载请注明原文链接:https://www.cnblogs.com/zhangchaoyang/articles/2842490.html

