


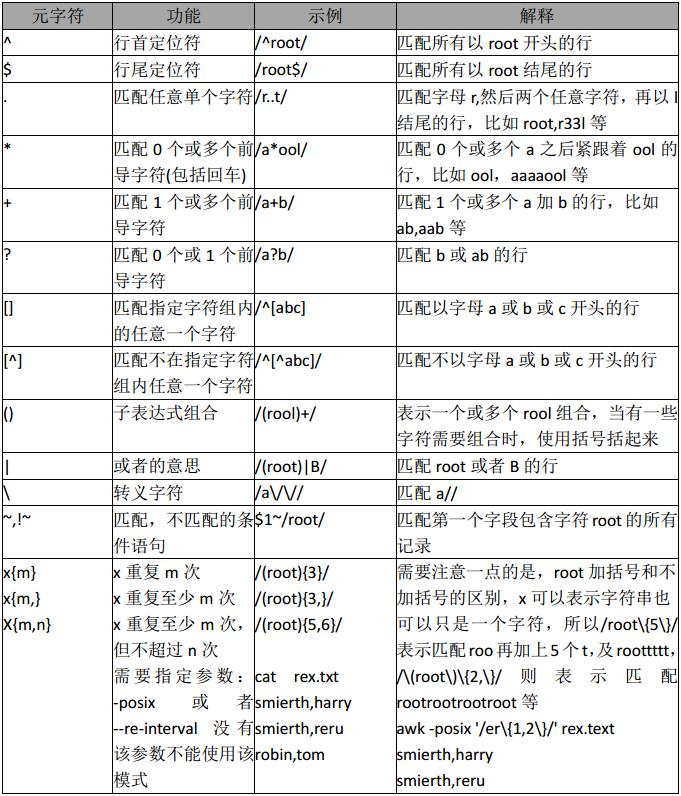
正则文本处理
文本处理常用命令grep cut awk sed:
date时间
[dispatcher@ip-172-31-14-16 log]$ date +%T 16:20:51 [dispatcher@ip-172-31-14-16 log]$ date +%Y:%T 2019:16:20:57 [dispatcher@ip-172-31-14-16 log]$ date -d "-10min" +%T 16:11:11 [dispatcher@ip-172-31-14-16 log]$ date -d "-1day" +%Y:%m:%d 2019:06:12 [dispatcher@ip-172-31-14-16 log]$ date -d "-1day" +%Y:%m:%d:%H:%M:%S 2019:06:12:16:21:31 [dispatcher@ip-172-31-14-16 log]$ date -d "-5 minute" +%H:%M:%S 16:18:47 [dispatcher@ip-172-31-14-16 log]$ date -d "-5min" +%H:%M:%S 16:18:55
cat 查看文件内容:
-b 显示行号,空白行不显示行号
-n 显示行号,包括空白行
more 分页查看文件内容,通过空格键查看下一页,q键则退出查看
less 分页查看文件内容,空格(下一页),方向键(上下回键),q键(退出查看)
head 查看文件头部内容,默认显示前10行:
-c nK 显示文件前nKB的内容
-c n 显示内容前n个字节
-n 显示文件前n行的内容
head -c 2K /root/install.log 查看文件前2KB的内容
head -20 /root/install.log 查看文件前20行的内容
tail 查看文件的尾部内容,默认显示末尾10行:
-c nK 显示文件末尾nKB的内容
-n 显示文件末尾n行的内容
-f 动态显示文件内容,按Ctrl+C组合键退出
tail -c 2K /root/install.log 查看文件末尾2KB的内容
tail -20 /root/install 查看文件末尾20行的内容
tail -f /var/log/messages 实时查看文件内容
wc 显示文件的行、单词与字节的统计信息:
-c 显示文件字节统计信息
-l 显示文件行数统计信息
-w 显示文件单词统计信息
sort 对文件内容进行排序
语法:
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
|
-b:忽略每行前面开始的空格字符,空格数量不固定时,该选项几乎是必须要使用的("-n"选项隐含该选项,测试发现都隐含) |
grep:
-i 是忽略大小写 --color 是加颜色
-n 是输出行号 (同 cat -n)
-w 精准匹配
-ra 深度查找匹配
-E 是grep 的 扩展
^ 是以什么开始
$ 是以什么结尾
o 只打印出匹配到的关键字,而不打印出整行
egrep相当于 grep -E
-v 是反选
grep Aug /var/log/messages 在文件 ‘/var/log/messages’中查找关键词”Aug”
grep ^Aug /var/log/messages 在文件 ‘/var/log/messages’中查找以”Aug”开始的词汇
grep --color "[0-9]" /var/log/messages 选择 ‘/var/log/messages’ 文件中所有包含数字的行
grep --color "[0-9][0-9][0-9]" /var/log/messages 选择 ‘/var/log/messages’ 文件中所有的数字连续匹配3次
grep -E --color "[0-9]{4}" /var/log/messages 选择 ‘/var/log/messages’ 文件中所有数字的行能连续匹配4次
grep -E --color "[0-9]{1,3}" /var/log/messages 选择 ‘/var/log/messages’ 文件中所有数字的行能连续匹配1到3次
netstat -lnutp | egrep -o "[0-9]+\/java"|egrep -o "[0-9]+" 取出所有java的进程id
grep --color "[a-z]" /var/log/messages
grep --color "[A-Z]" /var/log/messages
grep --color "[Aa-Zz]" /var/log/messages
grep Aug -R /var/log/* 在目录 ‘/var/log’ 及随后的目录中搜索字符串”Aug”
grep -i --color "com" test.txt 在test.txt文件里忽略大小写搜索“com”并颜色显示
grep -i -n --color "com" test.txt 在test.txt文件里忽略大小写搜索“com”,显示所在行号并颜色显示
egrep -n --color "[0-9]" /etc/passwd 显示/etc/passwd里所有内容的行号
grep -v "root" /etc/passwd 显示文件中root之外的所有内容(反选)
grep -v "^$" test.txt 去掉文件里的空行
grep -v "^#" test.txt 去掉文件里的注释行
egrep -v "^#|^$" test.txt 去掉文件里的注释行和空行
sed:
选项与参数:
-n :使用安静(silent)模式,加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来,但不会真正去修改原文件。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
function:
a :新增行, a 的后面可以是字串,而这些字串会在新的一行出现(目前的下一行)
c :取代行, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d :删除行,因为是删除,所以 d 后面通常不接任何参数,直接删除地址表示的行;
i :插入行, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :替换,可以直接进行替换的工作,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 一般是替换符合条件的字符串而不是整行
| ^ | 匹配行开始,如:/^sed/匹配所有以sed开头的行。 |
| $ | 匹配行结束,如:/sed$/匹配所有以sed结尾的行。 |
| $= | 匹配结尾的行数,如 sed -n "$=" /var/log/messsage. |
| . | 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。 |
| * | 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 |
sed -i '/192.168.1.115/d' awk.text 直接删除文件内的192.168.1.115
sed -i 's/192.168.1.115/192.168.1.114/g' awk.text 直接修改文件内的192.168.1.115为114
sed -i 's/serername/servername:/g' awk.text
sed -i '3s/serername/servername:/g' awk.text 修改文件种第3行(修改第几行在s前面加上修改的行数,不加默认全局)
sed -i '/server/s/serername/servername:/g' awk.text 先找到那一行的关键词,然后再修改
sed -i '/^SELINUX/s/enforcing/disabled/g' /etc/sysconfig/selinux 修改selinux文件永久关闭,^号是以什么为开头
sed -i '$s/server name:192.168.1.1/192.168.12/g' awk.text $号 代表结尾,修改最后一行
sed -i ‘s/stringa1/stringa2/g’ example.txt 将example.txt文件中的 “string1” 替换成 “string2”
sed -n ‘/stringa1/p’ 查看只包含词汇 “string1”的行(grep stringa1)
sed -n ‘1,5p;5q’ example.txt 查看从第一行到第5行内容
sed -n ‘5p;5q’ example.txt 查看第5行
sed -i ‘/^$/d’ example.txt 从example.txt 文件中删除所有空白行
sed -n '1p' awk.text 打印第一行
sed -n '2p' awk.text 打印第二行
sed -i '/^#/d' example.txt|sed -i '/^$/d' 从example.txt文件中删除所有注释和空白行
df -h |sed -n '/\/$/p'|sed 's/2%/20/g' 打印磁盘分区信息
cat awk.text |sort|sed 's/ /\n/g'|sort -nr |sed -n '1p;$p' sort -nr 是从小到大的顺序排序 反之-n \n 是换行的意思
sed -n "/`(date -d "-10min" +%Y:%T)`/,/`(date +%Y:%T)`/p" /usr/local/nginx/logs/access.log 分析前十分钟的日志
sed -n ‘/2015:12:00:*/,/2015:12:30:*/’p /data/log/nginx.log|awk ‘{print $1}’|sort|uniq –c|sort –nr|head -20 打印中午12点到12点半的前20行的日志信息访问ip最多的
sed -i '/^zhang/s/$/ 11/' awk.text 匹配以zhang开头的这一行并在结尾追加内容 这里$号代表行结尾
sed -n "$=" /var/log/messages 匹配日志最后一行的行数(写监控日志关键字脚本的时候会用到)
find . -type f -exec sed -i s#/opt/csp/logs#/opt/tsp/logs#g {} + 匹配当前目录下所有的文件进行批量替换
awk:
awk -F '[ !]' '{print substr($3,6)}' test.txt substr($3,6) 表示是从第3个字段里的第6个字符开始,一直到设定的分隔符结束. substr($3,12,6) ---> 表示是从第3个字段里的第12个字符开始,截取6个字符结束.
df -h |awk '{print $1}' 打印第一竖行的数据
df -h |awk '{pring $1,$2}' 打印第二竖行的数据
df -h |awk '{print $1":"$2}' 打印数据的$1,$2之间加个:号
df -h |awk '{print $1"------>"$2}'
ifconfig eth0|grep "Bcast"|awk '{print $2}'|sed 's/addr://g' 取出eth0网卡ip
ifconfig eth0|grep "Bcast"|awk '{print $2}'|awk -F: '{print $2}' 取出eth0网卡ip
ifconfig eth0|grep "Bcast"|awk '{print $2}'|awk -F: '{print $2}'|awk -F. '{print "addr:"$1"."$2"."$3".""0"}'
df -h|awk '/\/$/ {print $0}' 匹配以/为结尾分区所有内容($ 为结尾,\ 防止窜意)同grep "\/$"
awk -F ":" '{ if($NF-1>40)print $2}' localhost_access_log.2022-01-10.txt|uniq -c
(1) 取出/分区使用大小
df -h|awk '/\/$/ {print $0}'|sed 's/%//g'|awk '{print $5}'
(2) 监控判断磁盘大小
df -h|awk '/\/$/ {print $0}'|sed 's/%//g'|awk '{if($5>80)print "ture";else print "fales"}'
df -h|awk '/\/$/ {print $0}'|sed 's/%//g'|awk '{if($5>80){print "ture"}else{print "fales"}}'
(3) 搜索这条数据加起来有多少,再进行判断
cat tsc-xcall.log|grep "send msd to tmp ok"|awk '{a+=1}END{if(a>10)print "t";else print "f"}'
(4) 统计Nginx服务器总PV量。
awk '{print $7}' access.log |wc -l
(5) 统计Nginx服务器UV统计。
awk '{print $11}' access.log |sort -r|uniq -c |wc -l
(6) 打印这段时间内有多少条200的数据记录
cat /usr/local/nginx/logs/access.log|sed -n "/2016:09:00:00/,/2016:10:00:00/"p|grep "200"|awk '{print $10}'|awk '{sum += $1} END {print sum}'
cat /usr/local/nginx/logs/access.log|sed -n "/2016:09:00:00/,/2016:10:00:00/"p|awk '{print $NF}' |sed 's/"/" /'g|awk '{print $2}'|sed 's/"/ "/'g|awk '{if ($1>3)print $1}'|wc -l
awk '/2017:09:00/,/2017:12:00/' access.log|wc –l
(7) 分析截止目前为止访问量最高的IP排行并且访问量超过100的ip。
awk '{print $1}' /usr/local/nginx/logs/access.log|sort |uniq -c |sort -nr |awk ‘{if($1>=100) print $0}’|head -10
(8) 分析前十分钟的日志
sed -n "/`(date -d "-10min" +%Y:%T)`/,/`(date +%Y:%T)`/p" /usr/local/nginx/logs/access.log
access.log|awk ‘{print $1,$7}’|sort|uniq –c |sort –nr
(9) 查找访问请求超过0.5秒的url
awk ‘{if ($NF>0.5) print $1,$7,$NF}’ access.log|more
(10) 找到当前日志中502或者404错误的页面并统计。
awk‘{if(($9=502)||($9=404)) print $1,$7,$9 }’ /usr/local/nginx/logs/access.log|sort|uniq –c|sort -nr
(11) 分析Nginx访问日志状态码404、502、503、500、499等错误信息页面,打印错误出现次数大于20的IP地址。
awk‘{if($9~/502|499|500|503|404/) print $1,$7,$9 }’/usr/local/nginx/logs/access.log|sort|uniq –c|sort -nr |awk '{if($1>20) print $2}'
(12) 找到当前日志中502或者404错误的页面并统计。
awk '{print $0}' /usr/local/nginx/logs/access.log|egrep "404|502"|awk '{print $1,$7,$9}'|more
(13) 统计netstat -anp 状态为CONNECT的连接数量是多少
netstat -anlp|grep java|awk '/^tcp/ && /ESTABLISHED/{t++}END{print t}')
(14) 按(小时/天)统计接口请求超过50毫秒的计数
awk -F'[:,]' '{if ($(NF-2)>50)print substr($3,1)}' localhost_access_log.2022-01-10.txt|uniq -c|sort -nr|sort -k 2
awk -F'latency":' '{split($2,a,",");if(a[1]>50)print a[1]}' localhost_access_log.2022-01-10.txt|wc -l
(15) 按(天)统计接口请求超过5秒的url
cat localhost_access_log.2022-04-05.txt|awk -F"latency\":" '{split($2,a,"[,]");if(a[1]>5000)print $0}'|awk -F":" '{print $15}'|awk -F"/" '{OFS="/";$NF="";print $0}'|sort|uniq -c
(16) 按(天)统计接口请求超过5秒的时间段
cat localhost_access_log.2022-04-05.txt|awk -F"latency\":" '{split($2,a,"[,]");if(a[1]>5000)print $0}'|awk -F"/" '{print substr ($3,0,10)}'|uniq -c|sort -nr
(1) awk 赋值运算符:a+5;等价于: a=a+5;其他同类
(2) awk正则运算符:
awk 'BEGIN{a="100testaa";if(a~/100/) {print "ok"}}'
echo|awk 'BEGIN{a="100testaaa"}a~/test/{print "ok"}'
(3) 关系运算符:
awk 'BEGIN{a="11";if(a>=9){print "ok"}}' #无输出
awk 'BEGIN{a=11;if(a>=9){print "ok"}}'
awk 'BEGIN{a;if(a>=b){print "ok"}}'
awk 正则:
规则表达式
awk '/REG/{action} ' file,/REG/为正则表达式,可以将$0 中,满足条件的记录送入到:action 进行处理
awk '/root/{print $0}' passwd ##匹配所有包含root的行
awk -F: '$5~/root/{print $0}' passwd ## 以分号作为分隔符,匹配第5个字段是root的行
ifconfig eth0|awk 'BEGIN{FS="[[:space:]:]+"} NR==2{print $4}'
布尔表达式
awk '布尔表达式{action}' file 仅当对前面的布尔表达式求值为真时, awk 才执行代码块。
awk -F: '$1=="root"{print $0}' passwd
awk -F: '($1=="root")&&($5=="root") {print $0}' passwd
数组的典型应用:
用 awk 中查看服务器连接状态并汇总
netstat -an|awk '/^tcp/{++s[$NF]}END{for(a in s)print a,s[a]}'
统计 web 日志访问流量,要求输出访问次数,请求页面或图片,每个请求的总大小,总访问流量的大小汇总
awk '{a[$7]+=$10;++b[$7];total+=$10}END{for(x in a)print b[x],x,a[x]|"sort -rn -k1";print
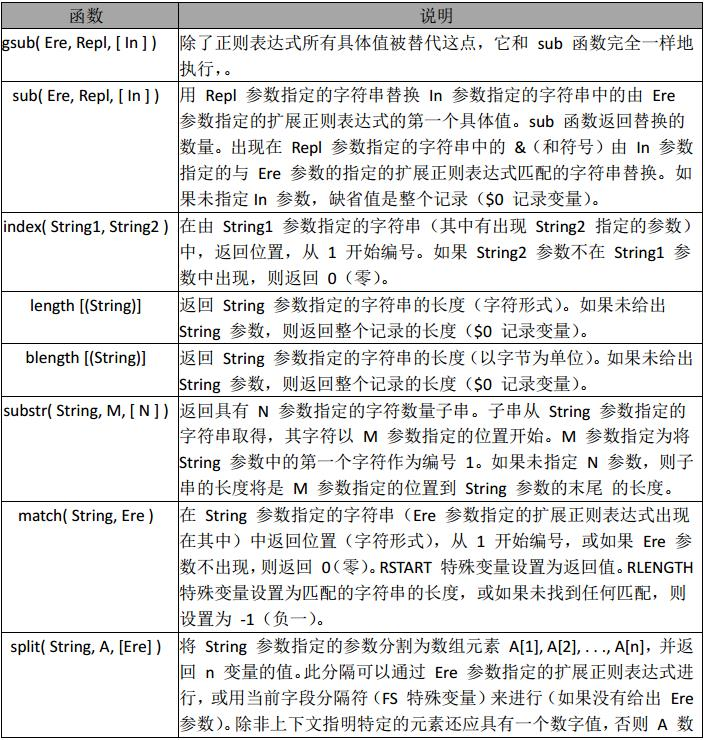
awk 内置函数:
split 初始化和类型强制
awk的内建函数split允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在FS(域分隔符)的值。
格式:
split (string, array) -->如果第三个参数没有提供,awk就默认使用当前FS值。
例子:
例1:替换分隔符
time="12:34:56"
echo $time | awk '{split($0,a,":");print a[1],a[2],a[3]}'
例2:split可以实现对字符串进行数组类型的分割。
echo ‘abcd’ | awk ‘{len=split($0,a,””);for(i=1;i<=len;i++)print “a[“i”]=”a[i];print “length=”len}’
a[1]=a
a[2]=b
a[3]=c
a[4]=d
length=4
解析说明:首先把abcd换为一个数组,并且数组的分隔符为没有符号,len=split($0,a,””)为获取了整个数组的长度,之后进行输出。在awk中如果是当做字符串输出的字符,全部用双引号来引起来。
substr 截取字符串
返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。
格式:
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
例子:
echo "123" | awk '{print substr($0,1,1)}'
1
解释:
awk -F ',' '{print substr($3,6)}' ---> 表示是从第3个字段里的第6个字符开始,一直到设定的分隔符","结束.
substr($3,10,8) ---> 表示是从第3个字段里的第10个字符开始,截取8个字符结束.
substr($3,6) ---> 表示是从第3个字段里的第6个字符开始,一直到结尾
length 字符串长度
length函数返回没有参数的字符串的长度。length函数返回整个记录中的字符数。
echo "123" | awk '{print length}'
3
gsub函数
gsub函数则使得在所有正则表达式被匹配的时候都发生替换。gsub(regular expression, subsitution string, target string);简称 gsub(r,s,t)。
举例:把一个文件里面所有包含 abc 的行里面的 abc 替换成 def,然后输出第一列和第三列
awk '$0 ~ /abc/ {gsub("abc", "def", $0); print $1, $3}' abc.txt
替换:
awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}' this is a test!test! 在 info 中查找满足正则表达式, /[0-9]+/ 用”!”替换,并且替换后的值,赋值给 info 未 给 info 值,默认是$0
查找
awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}' ok #未找到,返回 0
匹配查找
awk 'BEGIN{info="this is a test2010test!";print match(info,/[0-9]+/)?"ok":"no found";}' ok #如果查找到数字则匹配成功返回 ok,否则失败,返回未找到
截取
awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}' s is a tes #从第 4 个 字符开始,截取 10 个长度字符串
分割
awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}' 4 4 test 1 this 2 is 3 a #分割 info,动态创建数组 tA,awk for …in 循环,是一个无序的循环。 并不是从数组下标 1…n 开始
cut:
-d 以什么为分隔符
-f 打印
cat /etc/passwd | cut -d : -f 1 #以:分割,取第一段
a=daemon:x:2:2:daemon:/sbin:/sbin/nologin echo $a | cut -d: -f 1 daemon
在linux中字符串的截取我们可以用一个命令叫做cut,cut主要截取方法有三种
1)字节(bytes),用选项-b ,使用方法cut -b/c/f
2)字符(characters),用选项-c
3)域(fields),用选项-f
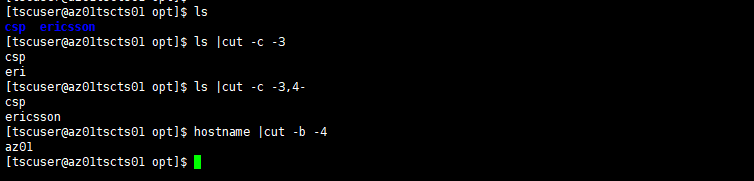
Shell中的${}、##和%%使用范例:
假设定义了一个变量为:
代码如下:
file=/dir1/dir2/dir3/my.file.txt
可以用${ }分别替换得到不同的值:
${file#*/}:删掉第一个 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}:删掉最后一个 / 及其左边的字符串:my.file.txt
${file#*.}:删掉第一个 . 及其左边的字符串:file.txt
${file##*.}:删掉最后一个 . 及其左边的字符串:txt
${file%/*}:删掉最后一个 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}:删掉第一个 / 及其右边的字符串:(空值)
${file%.*}:删掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}:删掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
