
JSON模块扩展:支持时间序列化 及 解决中文转换的问题!
扩展JSON模块
众所周知,json模块在多种开发语言中都通用,用于数据的序列化与反序列化。在Python中同理,也是常用它做数据的转换操作。
在Python中,JSON仅对基本的数据类型(字符串,列表,元组,字典,集合,数字,布尔值)可以进行序列化,如果我们编写代码过程中,只是处理这些操作的话,那什么问题都没有,也牵扯不到扩展的问题。如果你操作的文件或是数据库中,有结构化的时间格式呢?JSON默认可操作的数据类型可是不支持这种格式的!!!
所以我们就需要对JSON做一次扩展,让他不仅支持原先的基本数据类型的转换,也支持时间类型的序列化!
在查看JSON源码的过程中,我发现JSON的dumps()方法(序列化操作)的参数中,传入的第一个值是必须是要操作的数据,而其他的是一些自定义的方法;在这些方法中,我看到cls,这个的意思是可以传入一个类名,以对要序列化的数据按照类内定义的方法序列化操作!(当然,如果操作的数据与类内定义的方法不匹配的话,会执行其内部的方法)



def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw): """Serialize ``obj`` to a JSON formatted ``str``. If ``skipkeys`` is true then ``dict`` keys that are not basic types (``str``, ``int``, ``float``, ``bool``, ``None``) will be skipped instead of raising a ``TypeError``. If ``ensure_ascii`` is false, then the return value can contain non-ASCII characters if they appear in strings contained in ``obj``. Otherwise, all such characters are escaped in JSON strings. If ``check_circular`` is false, then the circular reference check for container types will be skipped and a circular reference will result in an ``OverflowError`` (or worse). If ``allow_nan`` is false, then it will be a ``ValueError`` to serialize out of range ``float`` values (``nan``, ``inf``, ``-inf``) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (``NaN``, ``Infinity``, ``-Infinity``). If ``indent`` is a non-negative integer, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0 will only insert newlines. ``None`` is the most compact representation. If specified, ``separators`` should be an ``(item_separator, key_separator)`` tuple. The default is ``(', ', ': ')`` if *indent* is ``None`` and ``(',', ': ')`` otherwise. To get the most compact JSON representation, you should specify ``(',', ':')`` to eliminate whitespace. ``default(obj)`` is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError. If *sort_keys* is true (default: ``False``), then the output of dictionaries will be sorted by key. To use a custom ``JSONEncoder`` subclass (e.g. one that overrides the ``.default()`` method to serialize additional types), specify it with the ``cls`` kwarg; otherwise ``JSONEncoder`` is used. """ # cached encoder if (not skipkeys and ensure_ascii and check_circular and allow_nan and cls is None and indent is None and separators is None and default is None and not sort_keys and not kw): return _default_encoder.encode(obj) if cls is None: cls = JSONEncoder return cls( skipkeys=skipkeys, ensure_ascii=ensure_ascii, check_circular=check_circular, allow_nan=allow_nan, indent=indent, separators=separators, default=default, sort_keys=sort_keys, **kw).encode(obj)
顺着这个思路,我往下接着看源码,发现了这里!也就是我们的突破口 -------> 看图片!!!
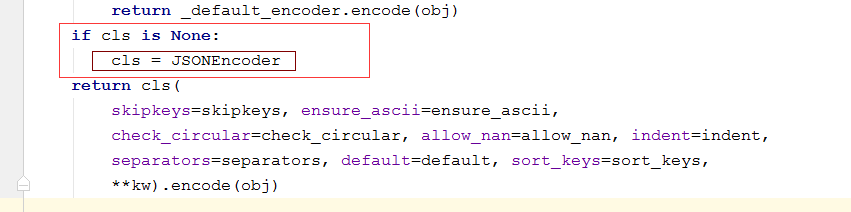
我们一般序列化数据的时候,仅仅是传入数据,cls这里我们是默认系统的也就是None,通过这里我们看到,如果cls = None,那他就会默认以他定义的类JSONEncoder的方式来操作!我再通过这个类名看这个类里都定义了什么方法。在这个类的__init__初始化的方法中,我看到了这个参数:default=None,官方的解释如下:
1 2 3 | If specified, default is a function that gets called for objects that can't otherwise be serialized. It should return a JSON encodable version of the object or raise a ``TypeError``. |
简而言之:这个default是我们用来定义方法的函数,如果有会按照我们定义的执行,没有的话,他会按照自己内部定义的函数去执行。
看到这儿就明了了!我们可以定义一个类,继承JSONEncoder这个基类,里边定义一个default函数,在这个函数中我们定义要扩展的方法。我们要做的是对时间的扩展,所以就写关于序列化时间的方法,如果数据不是时间的话,就直接执行JSONEncoder的内部方法。执行json.dumps()的时候,传参定义cls=我们自定义的类。
具体代码
import json from datetime import datetime from datetime import date class JsonCustomEncoder(json.JSONEncoder): """ json内部不支持时间格式的序列化 json扩展:以支持时间序列化 """ def default(self, value): if isinstance(value, datetime): #如果是datetime格式 return value.strftime('%Y-%m-%d %H:%M:%S') #格式化为年月日,时分秒类型的时间字符串 elif isinstance(value, date): #如果是date格式 return value.strftime('%Y-%m-%d') #格式化年月日类型的时间字符串 else: #如果都不是时间类型,就直接使用内部的方法 return json.JSONEncoder.default(self, value)
关于中文转换
在我们传递消息的过程中,避免不了的要发送中文。当我们信心满满的进行JSON序列化的时候,悲剧发生了!就像下面这样!
1 2 3 4 5 6 7 | #!/usr/bin/env python# _*_ coding:utf-8 _*_import jsontest_dic = {"id":1,"name":"逗逼","age":18}#序列化res = json.dumps(test_dic)print(res,type(res)) #打印序列化的结果<br># --------------执行结果-----------------------<br>#{"id": 1, "name": "\u9017\u903c", "age": 18} <class 'str'> |
OMG,我的中文去哪里了?怎么转成了unicode类型的数据?!
多次测试发现JSON dumps的时候是先把数据解码成unicode,然后再编码成其他【例如:默认指定是utf-8的话,会把unicode的数据按照utf-8编码!】!字符串在Python内部的表示是unicode编码。因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。并且在做编码转换的时候,默认是以ASCII码的方式去处理。所以说,如果我们想显示中文的话,就需要在dumps函数中添加参数ensure_ascii=False,即可解决中文编码的问题。实验测试如下:
1 2 3 4 5 6 7 8 9 10 | #!/usr/bin/env python# _*_ coding:utf-8 _*_import jsontest_dic = {"id":1,"name":"逗逼","age":18}#序列化res = json.dumps(test_dic,ensure_ascii=False)print(res,type(res)) #打印序列化的结果# --------------执行结果-----------------------#{"id": 1, "name": "逗逼", "age": 18} <class 'str'> |
另外,dumps方法还有一个参数indent,用来调整显示格式,能够更加直观在看到结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #!/usr/bin/env python# _*_ coding:utf-8 _*_import jsonxxx = [{'name':'张某某','age':20,'sex':'男'},{'name':'王某某','age':18,'sex':'女'}]rep = json.dumps(xxx,ensure_ascii=False,indent=2)print(rep,type(rep))# --------------执行结果-----------------------""" [ { "name": "张某某", "age": 20, "sex": "男" }, { "name": "王某某", "age": 18, "sex": "女" } ] <class 'str'>""" |
注意:以上所有测试,均是在Python3环境下完成的。如果你是Python2之类的版本,请参考:python2.7 json.dumps 中文编码


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 现代计算机视觉入门之:什么是图片特征编码
· .NET 9 new features-C#13新的锁类型和语义
· Linux系统下SQL Server数据库镜像配置全流程详解
· 现代计算机视觉入门之:什么是视频
· Sdcb Chats 技术博客:数据库 ID 选型的曲折之路 - 从 Guid 到自增 ID,再到
· .NET Core GC压缩(compact_phase)底层原理浅谈
· Winform-耗时操作导致界面渲染滞后
· Phi小模型开发教程:C#使用本地模型Phi视觉模型分析图像,实现图片分类、搜索等功能
· 语音处理 开源项目 EchoSharp