
内存管理概述、内存分配与释放、地址映射机制(mm_struct, vm_area_struct)、malloc/free 的实现
注:本分类下文章大多整理自《深入分析linux内核源代码》一书,另有参考其他一些资料如《linux内核完全剖析》、《linux c 编程一站式学习》等,只是为了更好地理清系统编程和网络编程中的一些概念性问题,并没有深入地阅读分析源码,我也是草草翻过这本书,请有兴趣的朋友自己参考相关资料。此书出版较早,分析的版本为2.4.16,故出现的一些概念可能跟最新版本内核不同。
此书已经开源,阅读地址 http://www.kerneltravel.net
一、内存管理概述
(一)、虚拟内存实现结构

![]()

![]()
![]()
![]()



![]()
![]()
![]()
(1)内存映射模块(mmap):负责把磁盘文件的逻辑地址映射到虚拟地址,以及把虚拟地址映射到物理地址。
(2)交换模块(swap):负责控制内存内容的换入和换出,它通过交换机制,使得在物理内存的页面(RAM 页)中保留有效的页 ,即从主存中淘汰最近没被访问的页,保存近来访问过的页。
(3)核心内存管理模块(core):负责核心内存管理功能,即对页的分配、回收、释放及请页处理等,这些功能将被别的内核子系统(如文件系统)使用。
(4)结构特定的模块:负责给各种硬件平台提供通用接口,这个模块通过执行命令来改变硬件MMU 的虚拟地址映射,并在发生页错误时,提供了公用的方法来通知别的内核子系统。这个模块是实现虚拟内存的物理基础。
(二)、内核空间和用户空间
Linux 简化了分段机制,使得虚拟地址与线性地址总是一致,因此,Linux 的虚拟地址空间也为0~4G 字节。Linux 内核将这4G 字节的空间分为两部分。将最高的1G 字节(从虚拟地址0xC0000000 到0xFFFFFFFF),供内核使用,称为“内核空间”。而将较低的3G 字节(从虚拟地址0x00000000 到0xBFFFFFFF),供各个进程使用,称为“用户空间”。因为每个进程可以通过系统调用进入内核,因此,Linux 内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G 字节的虚拟空间。图 6.3 给出了进程虚拟空间示意图。
Linux 使用两级保护机制:0 级供内核使用,3 级供用户程序使用。从图6.3 中可以看出,每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的。最高的1G 字节虚拟内核空间则为所有进程以及内核所共享。
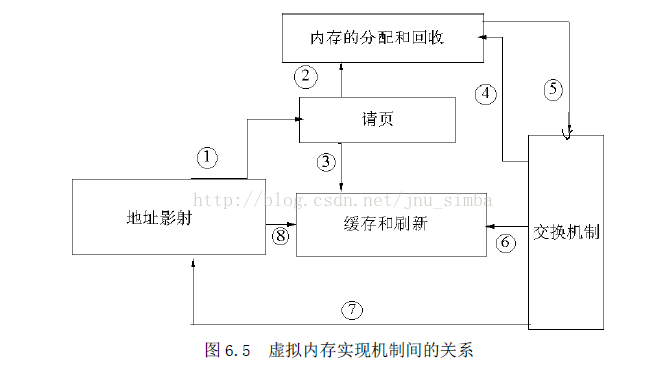
(三)、虚拟内存实现机制间的关系
首先内存管理程序通过映射机制把用户程序的逻辑地址映射到物理地址,在用户程序运行时如果发现程序中要用的虚地址没有对应的物理内存时,就发出了请页要求①;如果有空闲的内存可供分配,就请求分配内存②(于是用到了内存的分配和回收),并把正在使用的物理页记录在页缓存中③(使用了缓存机制)。如果没有足够的内存可供分配,那么就调用交换机制,腾出一部分内存④⑤。另外在地址映射中要通过TLB(翻译后援存储器)来寻找物理页⑧;交换机制中也要用到交换缓存⑥,并且把物理页内容交换到交换文件中后也要修改页表来映射文件地址⑦。
二、内存分配与释放
在Linux 中,CPU 不能按物理地址来访问存储空间,而必须使用虚拟地址;因此,对于内存页面的管理,通常是先在虚存空间中分配一个虚存区间,然后才根据需要为此区间分配相应的物理页面并建立起映射,也就是说,虚存区间的分配在前,而物理页面的分配在后。
(一)、伙伴算法(Buddy)
Linux 的伙伴算法把所有的空闲页面分为10 个块组,每组中块的大小是2 的幂次方个页面,例如,第0 组中块的大小都为2^0(1 个页面),第1 组中块的大小都为2^1(2 个页面),第9 组中块的大小都为2^9(512 个页面)。也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表。
我们通过一个简单的例子来说明该算法的工作原理。
假设要求分配的块的大小为128 个页面(由多个页面组成的块我们就叫做页面块)。该算法先在块大小为128 个页面的链表中查找,看是否有这样一个空闲块。如果有,就直接分配;如果没有,该算法会查找下一个更大的块,具体地说,就是在块大小256 个页面的链表中查找一个空闲块。如果存在这样的空闲块,内核就把这256 个页面分为两等份,一份分配出去,另一份插入到块大小为128 个页面的链表中。如果在块大小为256 个页面的链表中也没有找到空闲页块,就继续找更大的块,即512 个页面的块。如果存在这样的块,内核就从512 个页面的块中分出128 个页面满足请求,然后从384 个页面中取出256 个页面插入到块大小为256 个页面的链表中。然后把剩余的128 个页面插入到块大小为128 个页面的链表中。如果512 个页面的链表中还没有空闲块,该算法就放弃分配,并发出出错信号。
以上过程的逆过程就是块的释放过程,这也是该算法名字的来由。满足以下条件的两个块称为伙伴:
(1)两个块的大小相同;
(2)两个块的物理地址连续。
伙伴算法把满足以上条件的两个块合并为一个块,该算法是迭代算法,如果合并后的块还可以跟相邻的块进行合并,那么该算法就继续合并。
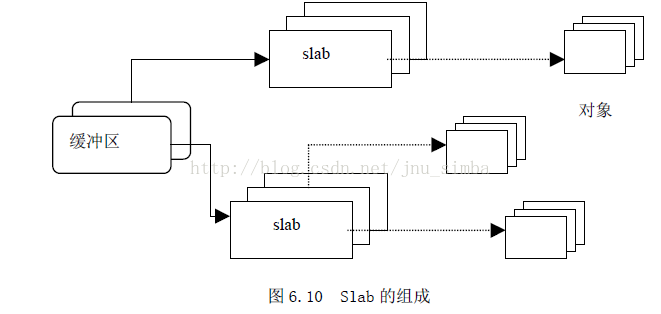
(二)、Slab 分配机制
可以根据对内存区的使用频率来对它分类。对于预期频繁使用的内存区,可以创建一组特定大小的专用缓冲区进行处理,以避免内碎片的产生。对于较少使用的内存区,可以创建一组通用缓冲区(如Linux 2.0 中所使用的2 的幂次方)来处理,即使这种处理模式产生碎
片,也对整个系统的性能影响不大。
硬件高速缓存的使用,又为尽量减少对伙伴算法的调用提供了另一个理由,因为对伙伴算法的每次调用都会“弄脏”硬件高速缓存,因此,这就增加了对内存的平均访问次数。
Slab 分配模式把对象分组放进缓冲区(尽管英文中使用了Cache 这个词,但实际上指的是内存中的区域,而不是指硬件高速缓存)。因为缓冲区的组织和管理与硬件高速缓存的命中率密切相关,因此,Slab 缓冲区并非由各个对象直接构成,而是由一连串的“大块(Slab)”构成,而每个大块中则包含了若干个同种类型的对象,这些对象或已被分配,或空闲,如图6.10 所示。一般而言,对象分两种,一种是大对象,一种是小对象。所谓小对象,是指在一个页面中可以容纳下好几个对象的那种。例如,一个inode 结构大约占300 多个字节,因此,一个页面中可以容纳8 个以上的inode 结构,因此,inode 结构就为小对象。Linux 内核中把小于512 字节的对象叫做小对象。
实际上,缓冲区就是主存中的一片区域,把这片区域划分为多个块,每块就是一个Slab,每个Slab 由一个或多个页面组成,每个Slab 中存放的就是对象。
三、地址映射机制
在进程的task_struct 结构中包含一个指向 mm_struct 结构的指针,mm_strcut 用来描述一个进程的虚拟地址空间。进程的 mm_struct 则包含装入的可执行映像信息以及进程的页目录指针pgd。该结构还包含有指向 vm_area_struct 结构的几个指针,每个 vm_area_struct 代表进程的一个虚拟地址区间。vm_area_struct 结构含有指向vm_operations_struct 结构的一个指针,vm_operations_struct 描述了在这个区间的操作。vm_operations 结构中包含的是函数指针;其中,open、close 分别用于虚拟区间的打开、关闭,而nopage 用于当虚存页面不在物理内存而引起的“缺页异常”时所应该调用的函数,当 Linux 处理这一缺页异常时(请页机制),就可以为新的虚拟内存区分配实际的物理内存。图6.15 给出了虚拟区间的操作集。
C++ Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
struct mm_struct
{ struct vm_area_struct *mmap; /* list of VMAs */ struct rb_root mm_rb; struct vm_area_struct *mmap_cache; /* last find_vma result */ ... unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; ... }; struct vm_area_struct { struct mm_struct *vm_mm; /* The address space we belong to. */ unsigned long vm_start; /* Our start address within vm_mm. */ unsigned long vm_end; /* The first byte after our end address within vm_mm. */ .... /* linked list of VM areas per task, sorted by address */ struct vm_area_struct *vm_next; .... /* describe the permissable operation */ unsigned long vm_flags; /* operations on this area */ struct vm_operations_struct * vm_ops; struct file * vm_file; /* File we map to (can be NULL). */ } ; /* * These are the virtual MM functions - opening of an area, closing and * unmapping it (needed to keep files on disk up-to-date etc), pointer * to the functions called when a no-page or a wp-page exception occurs. */ struct vm_operations_struct { void (*open)(struct vm_area_struct *area); void (*close)(struct vm_area_struct *area); struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused); }; |
四、malloc 和 free 的实现
C++ Code
|
1
2 3 4 5 6 7 8 9 10 |
Normally, malloc() allocates memory from the heap, and adjusts the size of the heap as required, using sbrk(2). When
allocating blocks of memory larger than MMAP_THRESHOLD bytes, the glibc malloc() implementation allocates the memory as a private anonymous mapping using mmap(2). MMAP_THRESHOLD is 128 kB by default, but is adjustable using mallopt(3). Allo‐ cations performed using mmap(2) are unaffected by the RLIMIT_DATA resource limit (see getrlimit(2)). MAP_ANONYMOUS The mapping is not backed by any file; its contents are initialized to zero. The fd and offset arguments are ignored; however, some implementations require fd to be - 1 if MAP_ANONYMOUS ( or MAP_ANON) is specified, and portable applications should ensure this. The use of MAP_ANONYMOUS in conjunction with MAP_SHARED is only supported on Linux since kernel 2.4. |
(一)、使用brk()/ sbrk() 实现
图中白色背景的框表示 malloc管理的空闲内存块,深色背景的框不归 malloc管,可能是已经分配给用户的内存块,也可能不属于当前进程, Break之上的地址不属于当前进程,需要通过 brk系统调用向内核申请。每个内存块开头都有一个头节点,里面有一个指针字段和一个长度字段,指针字段把所有空闲块的头节点串在一起,组成一个环形链表,长度字段记录着头节点和后面的内存块加起来一共有多长,以 8字节为单位(也就是以头节点的长度为单位)。
1. 一开始堆空间由一个空闲块组成,长度为 7×8=56字节,除头节点之外的长度为 48字节。
2. 调用 malloc分配 8个字节,要在这个空闲块的末尾截出 16个字节,其中新的头节点占了 8个字节,另外 8个字节返回给用户使用,注意返回的指针 p1指向头节点后面的内存块。
3. 又调用 malloc分配 16个字节,又在空闲块的末尾截出 24个字节,步骤和上一步类似。
4. 调用 free释放 p1所指向的内存块,内存块(包括头节点在内)归还给了 malloc,现在 malloc管理着两块不连续的内存,用环形链表串起来。注意这时 p1成了野指针,指向不属于用户的内存, p1所指向的内存地址在 Break之下,是属于当前进程的,所以访问 p1时不会出现段错误,但在访问 p1时这段内存可能已经被 malloc再次分配出去了,可能会读到意外改写数据。另外注意,此时如果通过 p2向右写越界,有可能覆盖右边的头节点,从而破坏 malloc管理的环形链表, malloc就无法从一个空闲块的指针字段找到下一个空闲块了,找到哪去都不一定,全乱套了。
5. 调用 malloc分配 16个字节,现在虽然有两个空闲块,各有 8个字节可分配,但是这两块不连续, malloc只好通过 brk系统调用抬高 Break,获得新的内存空间。在 [K&R]的实现中,每次调用 sbrk函数时申请 1024×8=8192个字节,在 Linux系统上 sbrk函数也是通过 brk实现的,这里为了画图方便,我们假设每次调用 sbrk申请 32个字节,建立一个新的空闲块。
6. 新申请的空闲块和前一个空闲块连续,因此可以合并成一个。在能合并时要尽量合并,以免空闲块越割越小,无法满足大的分配请求。
7. 在合并后的这个空闲块末尾截出 24个字节,新的头节点占 8个字节,另外 16个字节返回给用户。
8. 调用 free(p3)释放这个内存块,由于它和前一个空闲块连续,又重新合并成一个空闲块。注意, Break只能抬高而不能降低,从内核申请到的内存以后都归 malloc管了,即使调用 free也不会还给内核。
(二)、使用mmap() / munmap() 实现
在Linux下面,kernel 使用4096 byte来划分页面,而malloc的颗粒度更细,使用8 byte对齐,因此,分配出来的内存不一定是页对齐的。而mmap 分配出来的内存地址是页对齐的,所以munmap处理的内存地址必须页对齐(Page Aligned)。此外,我们可以使用memalign或是posix_memalign来获取一块页对齐的内存。
可以参考《linux的内存管理模型(上)》这篇文章。
在weibo上看到梁大的这个贴子:

实际上这是一个内存方面的问题。要想研究这个问题,首先我们要将题目本身搞明白。由于我对Linux内核比较熟而对Windows的内存模型几乎毫不了解,因此在这篇文章中针对Linux环境对这个问题进行探讨。
在Linux的世界中,从大的方面来讲,有两块内存,一块叫做内核空间,Kernel Space,另一块叫做用户空间,即User Space。它们是相互独立的,Kernel对它们的管理方式也完全不同。
首先我们要知道,现代操作系统一个重要的任务之一就是管理内存。所谓内存,就是内存条上一个一个的真正的存储单元,实实在在的电子颗粒,这里面通过电信号保存着数据。
Linux Kernel为了使用和管理这些内存,必须要给它们分成一个一个的小块,然后给这些小块标号。这一个一个的小块就叫做Page,标号就是内存地址,Address。
Linux内核会负责管理这些内存,保证程序可以有效地使用这些内存。它必须要能够管理好内核本身要用的内存,同时也要管理好在Linux操作系统上面跑的各种程序使用的内存。因此,Linux将内存划分为Kernel Space和User Space,对它们分别进行管理。
只有驱动模块和内核本身运行在Kernel Space当中,因此对于这道题目,我们主要进行考虑的是User Space这一块。
在Linux的世界中,Kernel负责给用户层的程序提供虚地址而不是物理地址。举个例子:A手里有20张牌,将它们命名为1-20。这20张牌要分给两个人,每个人手里10张。这样,第一个人拿到10张牌,将牌编号为1-10,对应A手里面的1-10;第二个人拿到10张牌,也给编号为1-10,对应A的11-20。
这里面,第二个人手里的牌,他自己用的时候编号是1-10,但A知道,第二个人手里的牌在他这里的编号是11-20。
在这里面,A的角色就是Linux内核;他手里的编号,1-20,就是物理地址;两个人相当于两个进程,它们对牌的编号就是虚地址;A要负责给两个人发牌,这就是内存管理。
了解了这些概念以后,我们来看看kernel当中具体的东西,首先是mm_struct这个结构体:
mm_struct负责描述进程的内存。相当于发牌人记录给谁发了哪些牌,发了多少张,等等。那么,内存是如何将内存进行划分的呢?也就是说,发牌人手里假设是一大张未裁剪的扑克纸,他是怎样将其剪成一张一张的扑克牌呢?上面的vm_area_struct就是基本的划分单位,即一张一张的扑克牌:
这个结构体的定义如下:
这样,内核就可以记录分配给用户空间的内存了。
Okay,了解了内核管理进程内存的两个最重要的结构体,我们来看看用户空间的内存模型。
Linux操作系统在加载程序时,将程序所使用的内存分为5段:text(程序段)、data(数据段)、bss(bss数据段)、heap(堆)、stack(栈)。
text segment(程序段)
text segment用于存放程序指令本身,Linux在执行程序时,要把这个程序的代码加载进内存,放入text segment。程序段内存位于整个程序所占内存的最上方,并且长度固定(因为代码需要多少内存给放进去,操作系统是清楚的)。
data segment(数据段)
data segment用于存放已经在代码中赋值的全局变量和静态变量。因为这类变量的数据类型(需要的内存大小)和其数值都已在代码中确定,因此,data segment紧挨着text segment,并且长度固定(这块需要多少内存也已经事先知道了)。
bss segment(bss数据段)
bss segment用于存放未赋值的全局变量和静态变量。这块挨着data segment,长度固定。
heap(堆)
这块内存用于存放程序所需的动态内存空间,比如使用malloc函数请求内存空间,就是从heap里面取。这块内存挨着bss,长度不确定。
stack(栈)
stack用于存放局部变量,当程序调用某个函数(包括main函数)时,这个函数内部的一些变量的数值入栈,函数调用完成返回后,局部变量的数值就没有用了,因此出栈,把内存让出来给另一个函数的变量使用(程序在执行时,总是会在某一个函数调用里面)。
我们看一个图例说明:

为了更好的理解内存分段,可以撰写一段代码:
编译这个代码,看看执行结果:

理解了进程的内存空间使用,我们现在可以想想,这几块内存当中,最灵活的是哪一块?没错,是Heap。其它几块都由C编译器编译代码时预处理,相对固定,而heap内存可以由malloc和free进行动态的分配和销毁。
有关malloc和free的使用方法,在本文中我就不再多说,这些属于基本知识。我们在这篇文章中要关心的是,malloc是如何工作的?实际上,它会去调用mmap(),而mmap()则会调用内核,获取VMA,即前文中看到的vm_area。这一块工作由c库向kernel发起请求,而由kernel完成这个请求,在kernel当中,有vm_operations_struct进行实际的内存操作:
可以看到,kernel可以对VMA进行open和close,即收发牌的工作。理解了malloc的工作原理,free也不难了,它向下调用munmap()。
下面是mmap和munmap的函数定义:
这里面,addr是希望能够分配到的虚地址,比如:我希望得到一张牌,做为我手里编号为2的那张。需要注意的是,mmap最后分配出来的内存地址不一定是你想要的,可能你请求一张编号为2的扑克,但发牌人控制这个编号过程,他会给你一张在你手里编号为3的扑克。
prot代表对进程对这块内存的权限:
flags代表用于控制很多的内存属性,我们一会儿会用到,这里不展开。
fd是文件描述符。我们这里必须明白一个基本原理,任何硬盘上面的数据,都要读取到内存当中,才能被程序使用,因此,mmap的目的就是将文件数据映射进内存。因此,要在这里填写文件描述符。如果你在这里写-1,则不映射任何文件数据,只是在内存里面要上这一块空间,这就是malloc对mmap的使用方法。
offset是文件的偏移量,比如:从第二行开始映射。文件映射,不是这篇文章关心的内容,不展开。
okay,了解了mmap的用法,下面看看munmap:
munmap很简单,告诉它要还回去的内存地址(即哪张牌),然后告诉它还回去的数量(多少张),其实更准确的说:尺寸。
现在让我们回到题目上来,如何部分地回收一个数组中的内存?我们知道,使用malloc和free是无法完成的:
因为无论是malloc还是free,都需要我们整体提交待分配和销毁的全部内存。于是自然而然想到,是否可以malloc分配内存后,然后使用munmap来部分地释放呢?下面是一个尝试:
运行这段代码输出如下:

注意到munmap调用返回-1,说明内存释放未成功,这是由于munmap处理的内存地址必须页对齐(Page Aligned)。在Linux下面,kernel使用4096 byte来划分页面,而malloc的颗粒度更细,使用8 byte对齐,因此,分配出来的内存不一定是页对齐的。为了解决这个问题,我们可以使用memalign或是posix_memalign来获取一块页对齐的内存:
运行上述代码得结果如下:

可以看到,页对齐的内存资源可以被munmap正确处理(munmap返回值为0,说明执行成功)。仔细看一下被分配出来的地址:
转换到10进制是:140602658275328
试试看是否能被4096整除:140602658275328 / 4096 = 34326820868
可以被整除,验证了分配出来的地址是页对齐的。
接下来,我们试用一下mmap,来分配一块内存空间:
注意上面mmap的使用方法。其中,我们不指定虚地址,让内核决定内存地址,也就是说,我们要是要一张牌,但不关心给牌编什么号。然后PROT_READ|PROT_WRITE表示这块内存可读写,接下来注意flags里面有MAP_ANONYMOUS,表示这块内存不用于映射文件。下面是完整代码:
运行结果如下:

注意munmap返回值为0,说明内存释放成功了。因此,验证了mmap分配出来的内存是页对齐的。
okay,了解了所有这些背景知识,我们现在应该对给内存打洞这个问题有一个思路了。我们可以创建以Page为基本单元的内存空间,然后用munmap在上面打洞。下面是实验代码:
我们申请了3*4096 byte的空间,也就是3页的内存,然后通过munmap,在中间这页上开个洞 。运行上面的代码,结果如下:

看到munmap的返回为0,说明内存释放成功,我们在arr数组上成功地开了一个洞。
这种方法,最大的局限在于,你操作的内存必须是page对齐的。如果想要更细颗粒度的打洞,纯靠User Space的API调用是不行的,需要在Kernel Space直接操作进程的VMA结构体来实现。实现思路如下:
1. 通过kernel提供的page map映射,找到要释放的内存虚地址所对应的物理地址。
2. 撰写一个内核模块,帮助你user space的程序来将实际的物理内存放回free list。
我在本文的下篇中,将详细介绍Kernel Space和User Space的结合编码,实现更细颗粒度的内存操作。
参考资料
Experiments with the Linux Kernel: Process Segments
How to find the physical address of a variable from user-space in Linux?
Simplest way to get physical address from the logical one in linux kernel module
Page Map
anon_mmap.c
Mmap
mmap()--Memory Map a File
C_dynamic_memory_allocation
What are the differences between "brk()" and "mmap()"?
How to guarantee alignment with malloc and or new?
Understanding Memory Pages and Page Alignment
实际上这是一个内存方面的问题。要想研究这个问题,首先我们要将题目本身搞明白。由于我对Linux内核比较熟而对Windows的内存模型几乎毫不了解,因此在这篇文章中针对Linux环境对这个问题进行探讨。
在Linux的世界中,从大的方面来讲,有两块内存,一块叫做内核空间,Kernel Space,另一块叫做用户空间,即User Space。它们是相互独立的,Kernel对它们的管理方式也完全不同。
首先我们要知道,现代操作系统一个重要的任务之一就是管理内存。所谓内存,就是内存条上一个一个的真正的存储单元,实实在在的电子颗粒,这里面通过电信号保存着数据。
Linux Kernel为了使用和管理这些内存,必须要给它们分成一个一个的小块,然后给这些小块标号。这一个一个的小块就叫做Page,标号就是内存地址,Address。
Linux内核会负责管理这些内存,保证程序可以有效地使用这些内存。它必须要能够管理好内核本身要用的内存,同时也要管理好在Linux操作系统上面跑的各种程序使用的内存。因此,Linux将内存划分为Kernel Space和User Space,对它们分别进行管理。
只有驱动模块和内核本身运行在Kernel Space当中,因此对于这道题目,我们主要进行考虑的是User Space这一块。
在Linux的世界中,Kernel负责给用户层的程序提供虚地址而不是物理地址。举个例子:A手里有20张牌,将它们命名为1-20。这20张牌要分给两个人,每个人手里10张。这样,第一个人拿到10张牌,将牌编号为1-10,对应A手里面的1-10;第二个人拿到10张牌,也给编号为1-10,对应A的11-20。
这里面,第二个人手里的牌,他自己用的时候编号是1-10,但A知道,第二个人手里的牌在他这里的编号是11-20。
在这里面,A的角色就是Linux内核;他手里的编号,1-20,就是物理地址;两个人相当于两个进程,它们对牌的编号就是虚地址;A要负责给两个人发牌,这就是内存管理。
了解了这些概念以后,我们来看看kernel当中具体的东西,首先是mm_struct这个结构体:
C代码 
- struct mm_struct {
- struct vm_area_struct * mmap; /* list of VMAs */
- struct rb_root mm_rb;
- struct vm_area_struct * mmap_cache; /* last find_vma result */
- ...
- unsigned long start_code, end_code, start_data, end_data;
- unsigned long start_brk, brk, start_stack;
- ...
- };
mm_struct负责描述进程的内存。相当于发牌人记录给谁发了哪些牌,发了多少张,等等。那么,内存是如何将内存进行划分的呢?也就是说,发牌人手里假设是一大张未裁剪的扑克纸,他是怎样将其剪成一张一张的扑克牌呢?上面的vm_area_struct就是基本的划分单位,即一张一张的扑克牌:
C代码
- struct vm_area_struct * mmap;
这个结构体的定义如下:
C代码
- struct vm_area_struct {
- struct mm_struct * vm_mm; /* The address space we belong to. */
- unsigned long vm_start; /* Our start address within vm_mm. */
- unsigned long vm_end; /* The first byte after our end address
- within vm_mm. */
- ....
- /* linked list of VM areas per task, sorted by address */
- struct vm_area_struct *vm_next;
- ....
- }
这样,内核就可以记录分配给用户空间的内存了。
Okay,了解了内核管理进程内存的两个最重要的结构体,我们来看看用户空间的内存模型。
Linux操作系统在加载程序时,将程序所使用的内存分为5段:text(程序段)、data(数据段)、bss(bss数据段)、heap(堆)、stack(栈)。
text segment(程序段)
text segment用于存放程序指令本身,Linux在执行程序时,要把这个程序的代码加载进内存,放入text segment。程序段内存位于整个程序所占内存的最上方,并且长度固定(因为代码需要多少内存给放进去,操作系统是清楚的)。
data segment(数据段)
data segment用于存放已经在代码中赋值的全局变量和静态变量。因为这类变量的数据类型(需要的内存大小)和其数值都已在代码中确定,因此,data segment紧挨着text segment,并且长度固定(这块需要多少内存也已经事先知道了)。
bss segment(bss数据段)
bss segment用于存放未赋值的全局变量和静态变量。这块挨着data segment,长度固定。
heap(堆)
这块内存用于存放程序所需的动态内存空间,比如使用malloc函数请求内存空间,就是从heap里面取。这块内存挨着bss,长度不确定。
stack(栈)
stack用于存放局部变量,当程序调用某个函数(包括main函数)时,这个函数内部的一些变量的数值入栈,函数调用完成返回后,局部变量的数值就没有用了,因此出栈,把内存让出来给另一个函数的变量使用(程序在执行时,总是会在某一个函数调用里面)。
我们看一个图例说明:
为了更好的理解内存分段,可以撰写一段代码:
C代码
- #include <stdio.h>
- // 未赋值的全局变量放在dss段
- int global_var;
- // 已赋值的全局变量放在data段
- int global_initialized_var = 5;
- void function() {
- int stack_var; // 函数中的变量放在stack中
- // 放在stack中的变量
- // 显示其所在内存地值
- printf("the function's stack_var is at address 0x%08x\n", &stack_var);
- }
- int main() {
- int stack_var; // 函数中的变量放在stack中
- // 已赋值的静态变量放在data段
- static int static_initialized_var = 5;
- // 未赋值的静态变量放在dss段
- static int static_var;
- int *heap_var_ptr;
- // 由malloc在heap中分配所需内存,
- // heap_var_ptr这个指针指向这块
- // 分配的内存
- heap_var_ptr = (int *) malloc(4);
- // 放在data段的变量
- // 显示其所在内存地值
- printf("====IN DATA SEGMENT====\n");
- printf("global_initialized_var is at address 0x%08x\n", &global_initialized_var);
- printf("static_initialized_var is at address 0x%08x\n\n", &static_initialized_var);
- // 放在bss段的变量
- // 显示其所在内存地值
- printf("====IN BSS SEGMENT====\n");
- printf("static_var is at address 0x%08x\n", &static_var);
- printf("global_var is at address 0x%08x\n\n", &global_var);
- // 放在heap中的变量
- // 显示其所在内存地值
- printf("====IN HEAP====\n");
- printf("heap_var is at address 0x%08x\n\n", heap_var_ptr);
- // 放在stack中的变量
- // 显示其所在内存地值
- printf("====IN STACK====\n");
- printf("the main's stack_var is at address 0x%08x\n", &stack_var);
- function();
- }
编译这个代码,看看执行结果:
理解了进程的内存空间使用,我们现在可以想想,这几块内存当中,最灵活的是哪一块?没错,是Heap。其它几块都由C编译器编译代码时预处理,相对固定,而heap内存可以由malloc和free进行动态的分配和销毁。
有关malloc和free的使用方法,在本文中我就不再多说,这些属于基本知识。我们在这篇文章中要关心的是,malloc是如何工作的?实际上,它会去调用mmap(),而mmap()则会调用内核,获取VMA,即前文中看到的vm_area。这一块工作由c库向kernel发起请求,而由kernel完成这个请求,在kernel当中,有vm_operations_struct进行实际的内存操作:
C代码
- struct vm_operations_struct {
- void (*open)(struct vm_area_struct * area);
- void (*close)(struct vm_area_struct * area);
- ...
- };
可以看到,kernel可以对VMA进行open和close,即收发牌的工作。理解了malloc的工作原理,free也不难了,它向下调用munmap()。
下面是mmap和munmap的函数定义:
C代码
- void *
- mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
这里面,addr是希望能够分配到的虚地址,比如:我希望得到一张牌,做为我手里编号为2的那张。需要注意的是,mmap最后分配出来的内存地址不一定是你想要的,可能你请求一张编号为2的扑克,但发牌人控制这个编号过程,他会给你一张在你手里编号为3的扑克。
prot代表对进程对这块内存的权限:
C代码
- PROT_READ 是否可读
- PROT_WRITE 是否可写
- PROT_EXEC IP指针是否可以指向这里进行代码的执行
- PROT_NONE 不能访问
flags代表用于控制很多的内存属性,我们一会儿会用到,这里不展开。
fd是文件描述符。我们这里必须明白一个基本原理,任何硬盘上面的数据,都要读取到内存当中,才能被程序使用,因此,mmap的目的就是将文件数据映射进内存。因此,要在这里填写文件描述符。如果你在这里写-1,则不映射任何文件数据,只是在内存里面要上这一块空间,这就是malloc对mmap的使用方法。
offset是文件的偏移量,比如:从第二行开始映射。文件映射,不是这篇文章关心的内容,不展开。
okay,了解了mmap的用法,下面看看munmap:
C代码
- int
- munmap(void *addr, size_t len);
munmap很简单,告诉它要还回去的内存地址(即哪张牌),然后告诉它还回去的数量(多少张),其实更准确的说:尺寸。
现在让我们回到题目上来,如何部分地回收一个数组中的内存?我们知道,使用malloc和free是无法完成的:
C代码
- #include <stdlib.h>
- int main() {
- int *p = malloc(12);
- free(p);
- return 0;
- }
因为无论是malloc还是free,都需要我们整体提交待分配和销毁的全部内存。于是自然而然想到,是否可以malloc分配内存后,然后使用munmap来部分地释放呢?下面是一个尝试:
C代码
- #include <sys/mman.h>
- #include <stdio.h>
- #include <stdlib.h>
- int main() {
- int *arr;
- int *p;
- p = arr = (int*) malloc(3 * sizeof(int));
- int i = 0;
- for (i=0;i<3;i++) {
- *p = i;
- printf("address of arr[%d]: %p\n", i, p);
- p++;
- }
- printf("munmap: %d\n", munmap(arr, 3 * sizeof(int)));
- }
运行这段代码输出如下:
注意到munmap调用返回-1,说明内存释放未成功,这是由于munmap处理的内存地址必须页对齐(Page Aligned)。在Linux下面,kernel使用4096 byte来划分页面,而malloc的颗粒度更细,使用8 byte对齐,因此,分配出来的内存不一定是页对齐的。为了解决这个问题,我们可以使用memalign或是posix_memalign来获取一块页对齐的内存:
C代码
- #include <sys/mman.h>
- #include <stdio.h>
- #include <stdlib.h>
- int main() {
- void *arr;
- printf("posix_memalign: %d\n", posix_memalign(&arr, 4096, 4096));
- printf("address of arr: %p\n", arr);
- printf("munmap: %d\n", munmap(arr, 4096));
- }
运行上述代码得结果如下:
可以看到,页对齐的内存资源可以被munmap正确处理(munmap返回值为0,说明执行成功)。仔细看一下被分配出来的地址:
Bash代码
- 0x7fe09b804000
转换到10进制是:140602658275328
试试看是否能被4096整除:140602658275328 / 4096 = 34326820868
可以被整除,验证了分配出来的地址是页对齐的。
接下来,我们试用一下mmap,来分配一块内存空间:
C代码
- mmap(NULL, 3 * sizeof(int), PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0)
注意上面mmap的使用方法。其中,我们不指定虚地址,让内核决定内存地址,也就是说,我们要是要一张牌,但不关心给牌编什么号。然后PROT_READ|PROT_WRITE表示这块内存可读写,接下来注意flags里面有MAP_ANONYMOUS,表示这块内存不用于映射文件。下面是完整代码:
C代码
- #include <sys/mman.h>
- #include <stdio.h>
- #include <stdlib.h>
- int main() {
- int *arr;
- int *p;
- p = arr = (int*) mmap(NULL, 3 * sizeof(int), PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
- int i = 0;
- for (i=0;i<3;i++) {
- *p = i;
- printf("address of arr[%d]: %p\n", i, p);
- p++;
- }
- printf("munmap: %d\n", munmap(arr, 3 * sizeof(int)));
- }
运行结果如下:
注意munmap返回值为0,说明内存释放成功了。因此,验证了mmap分配出来的内存是页对齐的。
okay,了解了所有这些背景知识,我们现在应该对给内存打洞这个问题有一个思路了。我们可以创建以Page为基本单元的内存空间,然后用munmap在上面打洞。下面是实验代码:
C代码
- #include <sys/mman.h>
- #include <stdio.h>
- #include <stdlib.h>
- int main() {
- void *arr;
- printf("posix_memalign: %d\n", posix_memalign(&arr, 4096, 3 * 4096));
- printf("address of arr: %p\n", arr);
- printf("address of arr[4096]: %p\n", &arr[4096]);
- printf("munmap: %d\n", munmap(&arr[4096], 4096));
- }
我们申请了3*4096 byte的空间,也就是3页的内存,然后通过munmap,在中间这页上开个洞 。运行上面的代码,结果如下:
看到munmap的返回为0,说明内存释放成功,我们在arr数组上成功地开了一个洞。
这种方法,最大的局限在于,你操作的内存必须是page对齐的。如果想要更细颗粒度的打洞,纯靠User Space的API调用是不行的,需要在Kernel Space直接操作进程的VMA结构体来实现。实现思路如下:
1. 通过kernel提供的page map映射,找到要释放的内存虚地址所对应的物理地址。
2. 撰写一个内核模块,帮助你user space的程序来将实际的物理内存放回free list。
我在本文的下篇中,将详细介绍Kernel Space和User Space的结合编码,实现更细颗粒度的内存操作。
参考资料
Experiments with the Linux Kernel: Process Segments
How to find the physical address of a variable from user-space in Linux?
Simplest way to get physical address from the logical one in linux kernel module
Page Map
anon_mmap.c
Mmap
mmap()--Memory Map a File
C_dynamic_memory_allocation
What are the differences between "brk()" and "mmap()"?
How to guarantee alignment with malloc and or new?
Understanding Memory Pages and Page Alignment

- 大小: 23.2 KB


- 大小: 76.1 KB


- 大小: 240.1 KB


- 大小: 28.2 KB


- 大小: 22.6 KB


- 大小: 43 KB


- 大小: 20.7 KB


- 大小: 20.7 KB


- 大小: 26.1 KB


