博客作业05--查找
1.学习总结
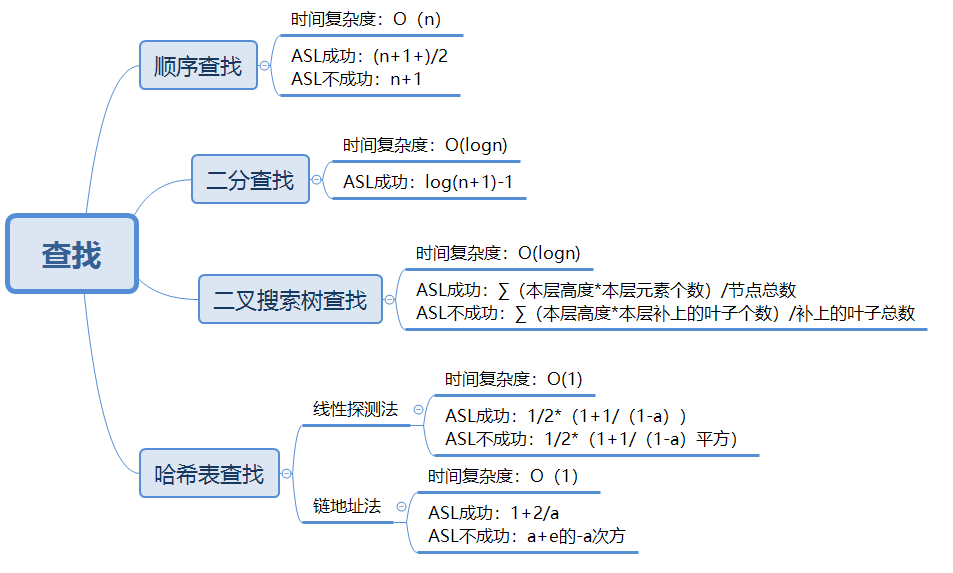
1.1查找的思维导图
1.2 查找学习体会
查找有顺序查找,二分查找,二叉排序树的查找,哈希表查找等等,有着不同的时间复杂度,使用也有要求,二分查找是顺序查找的优化版,但是使用上需要数组中的数据排列有序。在stl容器中,可以通过find函数和count。find的函数需要定义一个指针,如果没有找到的话,指针就会指向容器的尾部,否则如果指针没有指向容器尾部就是找到了。而count是查找容器当中这个元素的个数,不为0则代表存在于容器中。查找是一种很复杂的算法,不同情况下需要对应用不同的查找算法,这样才能拥有最低的时间复杂度,需要我们好好学习。
2.PTA实验作业
2.1 题目:7-1QQ帐户的申请与登陆
2.2 设计思路
定义一个string和stirng类型的map的遍历a
输入数据个数n
for i=0 to n
输入用户账户和密码
在a中查找账户
if 要登录即ch为c
if 找不到
输出 “ERROR: Not Exist”
else if 找到了但密码不对
输出"ERROR: Wrong PW"
else 输出"Login: OK"
else
如果没找到
a[用户账户]=密码
输出"New: OK"
否则
输出"ERROR: Exist"
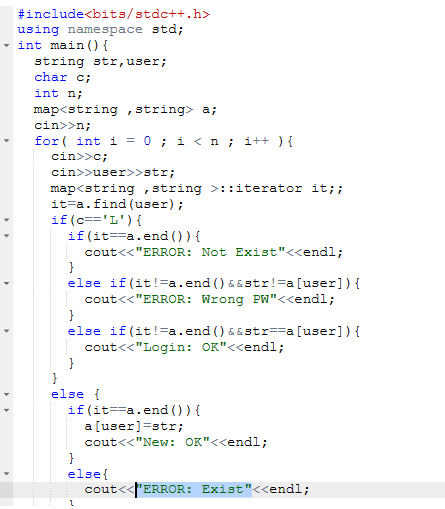
2.3 代码截图
2.4 PTA提交列表说明

错误是因为一个是定义map类型的时候,定义成int和string,由于数值太大导致错误,应该用string和string
2.1 题目2:7-2航空公司VIP客户查询
2.2 设计思路
定义一个string和int的map的变量a
输入飞行记录总数N,最低历程k
for i=0 to n
输入身份证号和里程
如果 里程低于最低里程
里程等于最低里程
如果 a中没有身份证号
a[身份证]=里程
否则
身份证对应里程加上输入的里程
输入查询总数m
for i=0 to m
输入要查询的身份证号
如果a中有该身份证号
输出身份证号对应的里程
否则 输出“No Info”
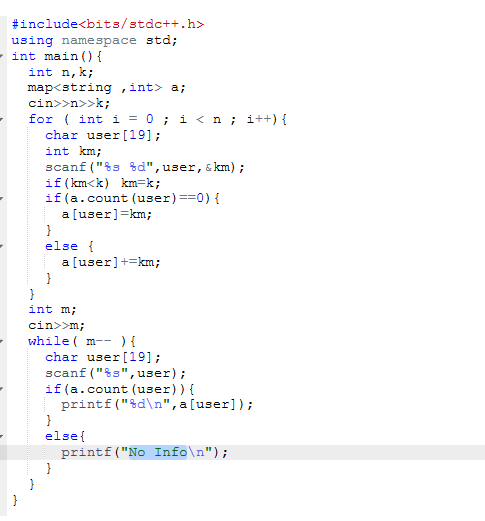
2.3 代码截图
2.4 PTA提交列表说明

这道题我提交了几十遍都是因为运行超时错误,一开始用map做运行超时,于是我用哈希表做还是超时,是因为哈希冲突导致时间复杂度大大增加所以超时,最后用map,然后将cin全改成scanf,cout全改成printf就过了,原来c的输入输出的时间复杂度比c++的低。
2.1 题目3:7-3基于词频的文件相似度
2.2 设计思路
定义一个string的set s[105]
定义flag=0表示输入是否已经有十个字符,f表示是否有输入即字符数组中有字母,字符数组b[100]以及字符ch
输入文件个数n
for i=1 to n
while(输入的字符ch不为'#')
flag=0
f=1
如果 flag=0并且ch为字母
将ch放入b中
如果b的长度为10
flag=1
f=0表示有输入
如果f等于0并且ch不是字母
如果b的字符长度大于2
将刚刚输入在b中的字符转换成字符串
将字符串插入到s中
f=1表示当前数组中没有字母,flag=0表示不满十个字母
输入查询总数m
for i=0 to m
定义一个num表示次数
输入查询的文件编号num1,num2
定义一个string的set指针 it
for it=s[num1].begin to s[num1].edn
如果it所指的值在s[num2]中有出现
num++
输出(num*100)/(s[num1]的长度加上s[num2]的长度-num)并保留一位小数
2.3 代码截图


2.4 PTA提交列表说明
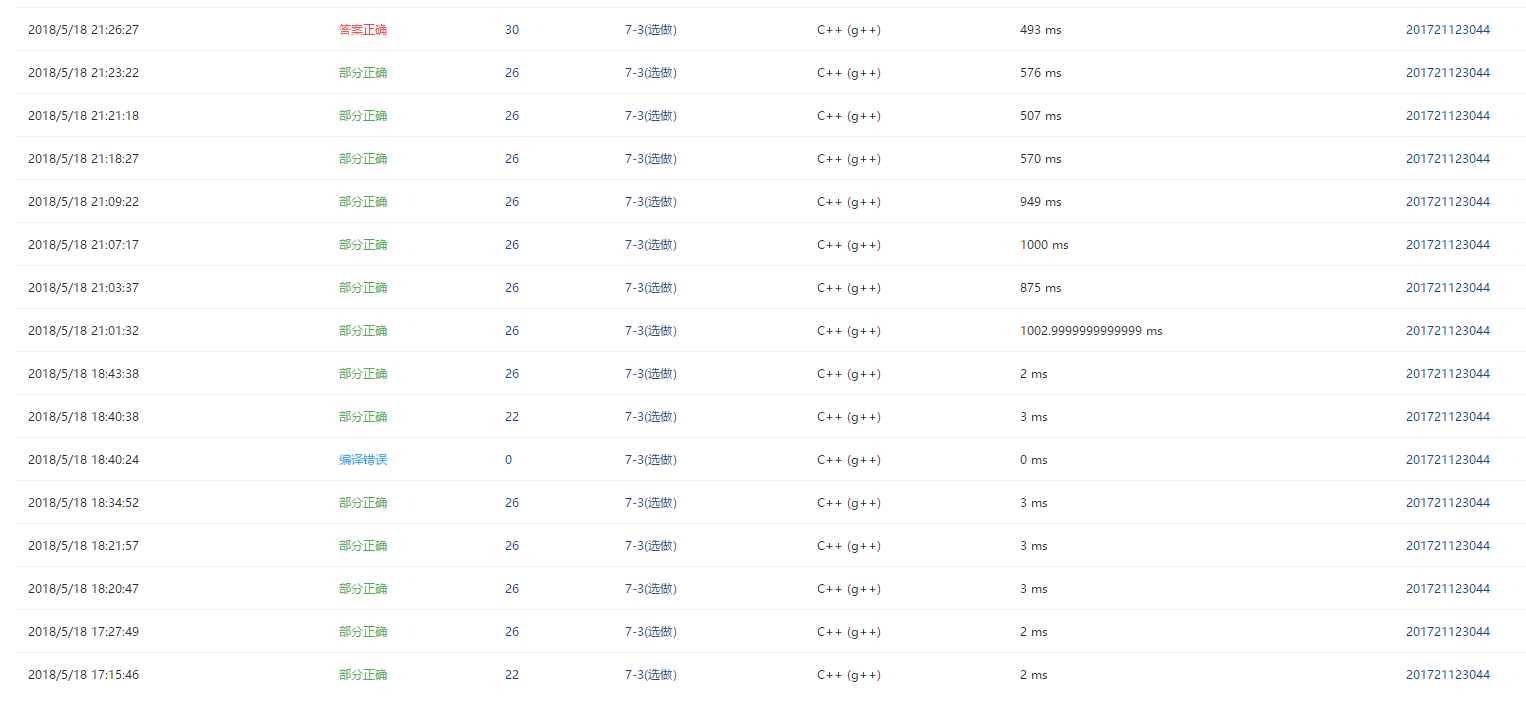
前面错误是有运行超时和答案错误,运行超时是因为一开始思路错了竟然先用map再转set,想的麻烦了,答案错误是因为在存入的时候没有考虑同一个文件有重复的单词导致错误。
- 用set是因为set是一个集合,里面的元素符合集合的规则,即不能重复,就可以判断本题的文件中有多少个单词,因为题目说单词不能重复,而且用自带size()函数能很快得出文件的单词个数。另外set可以实现自动排序,是按升序进行的。
3.截图本周题目集的PTA最后排名
3.1 PTA排名
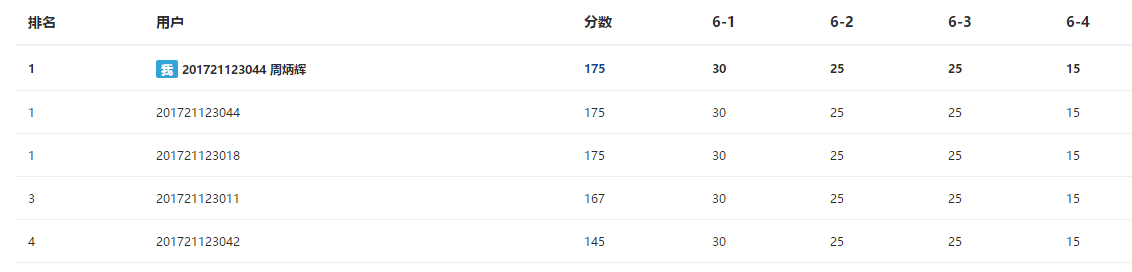
3.2我的总分
- 175
4. 阅读代码
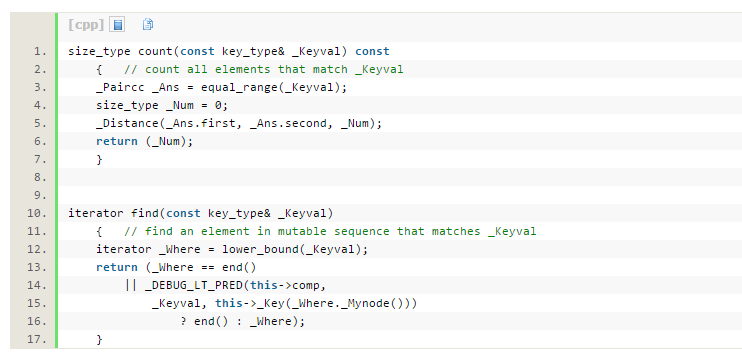
这是map中count和find函数的源代码,刚看一眼我就觉得这么简单,代码的简洁性非常高。 count函数通过equal_range函数在树中二分查找元素实现,find通过lower_bound函数,在树中寻找第一个比要在查找元素大的元素的位置来实现,短短几行就能完成,让人惊叹。
5.代码Git提交记录截图