
用js来实现那些数据结构13(树01-二叉搜索树的实现)
前一篇文章我们学会了第一个非顺序数据结构hashMap,那么这一篇我们来学学树,包括树的概念和一些相关的术语以及二叉搜索树的实现。唉?为什么不是树的实现,不是二叉树的实现。偏偏是二叉搜索树的实现?嗯,别急。我们一点一点循序渐进。
我们先来了解一下什么是树。树是一种非线性数据结构,直观的看,它是数据元素(在树中称为节点)按分支关系组织起来的结构,很像自然界中的树那样。在现实生活中,最常见的例子就是家谱或者公司的组织架构图。就像是这样:
那么我们还要知道树的一些相关术语,比较多,大家要仔细阅读,不然后面就完全懵逼了。我们先来看一下树这种数据结构的图示。
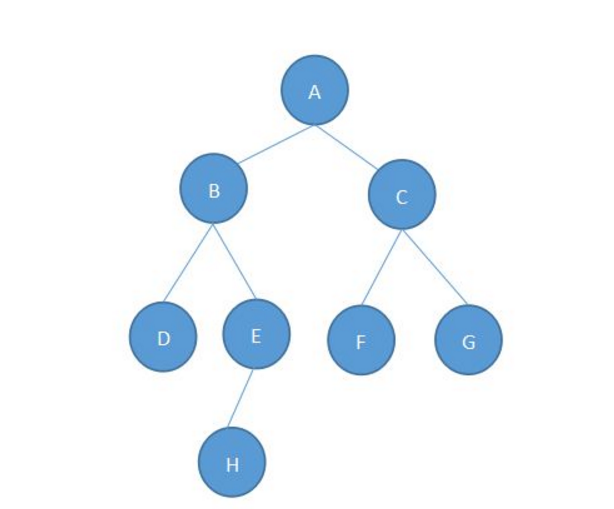
这是我在百度上找到的一张图,还算清晰明了。这就是树数据结构了。
首先,一个树结构,存在一系列的父子关系,除了顶部的第一个节点以外,每一个结点都有一个父节点以及零个或多个子节点。位于树顶部的节点叫做根节点。看上图,根节点就是A。树中的每一个元素(A,B,C,D,E,F这些)都叫做节点。节点又分为内部节点和外部节点。至少有一个子节点的节点称为内部节点(如上图的A,B,C,E)。没有子节点的节点称为外部节点或叶节点(如上图的D,F,G)。
另一个概念是子树,定义是这样的:子树由节点和它的后代构成。也就是说,把树中的一部分剖离出来,它仍旧可以看作是是一颗单独的树,那么就可以称之为子树。
节点还有一个属性,叫做度,也可以叫做深度,节点的深度取决于它有多少个祖先节点。如上图的H,深度就是3,因为它有E,B,A三个祖先节点。E的深度就是2。
除了节点的深度,一棵树还可以被分解层级。根节点是第0层,根节点的子节点是第1层。以此类推。
那么我们对树的概念有了简单的了解,那么什么是二叉树呢?其实不论是二叉树,还是二叉搜索树,又或者是其它什么树,只不过是在树的基础上加上一个限制条件以便更高效率的操作。
在二叉树中,一个节点的子节点最多只能有两个节点,一个左节点,一个右节点,二叉树只能是左右分叉的,所以叫做二叉树。
那二叉搜索树(BST)呢?不过是在二叉树的基础上,又加了一个插入元素的条件,就是,只允许你在左侧节点存储比父节点小的值,在右侧节点存储大于或等于父节点的值。这里要注意的一点是,二叉树的子节点最多只能有两个节点,也就说不一定非要有两个节点,只有一个左节点,或者只有一个右节点都是可以的可能的允许的。
那么似乎我们不去实现树,也不去实现二叉树,而是直接实现二叉搜索树的原因就出来了。只要我们学会了二叉搜索树,自然树和二叉树的实现也就会了。
来,我们来看图说话,在开始实现二叉搜索树之前,先给大家放张图(图片百度的),以便大家更好的理解。
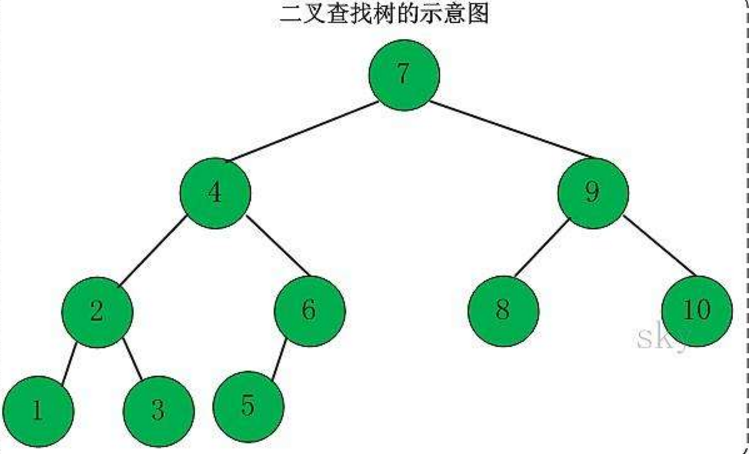
既然图有了,我们就来看看如何实现一个BinarySearchTree。首先,要告诉大家的是,在链表中,我们称每一个节点本身称作节点,但是在树中,我们叫它键。唉?我好像看到了链表?树跟链表有毛关系?嗯。。。确实没关系,但是我们要实现树的方式却跟链表有关系。我们之前学习过双向链表,双向链表中有prev和next,分别指向当前节点的上一个和下一个节点。树的实现我们也要借用类似的方式,只不过是一个指向左侧子节点,另一个指向右侧子节点。
那么我们都要实现哪些方法呢?
1、insert(key):像树中插入一个新的键。
2、search(key):在树中查找一个键。
3、inOrderTraverse:中序遍历。
4、preOrderTraverse:先序遍历。
5、postOrderTraverse:后序遍历。
6、min:返回树中最小的值/键。
7、max:返回树中最大的值/键。
8、remove(key):从树中移除某个键。
我们知道了基本的实现方式和BinarySearchTree需要的方法。我们开始吧。

// 这个二叉搜索树的实现根本其实并没有多复杂,复杂的其实是概念。 // 但是,我会尽量给大家解释清楚。不至于让大家一脸懵逼。 function BinarySearchTree() { // 首先这里,声明一个node节点,也就是我们树结构中所代表的每一个节点,包括根节点在内。 var Node = function(key) { // 节点的key,也就是键,大家要记住一个事情,我们所有的数据结构,都是为了应对合理适当的场景。 // 而无论何种数据结构,都需要检索,我记得前面说过,也就是增删改查这种万年不变的操作。 // 而这里的键(也就是key),是为了依照一定的规则来设置键,以便我们更快速的检索到,提取其值。 // 当然,我们实现的这个二叉搜索树貌似并没有value,但是我们可以自己去设置一个键值对的映射关系。 // 既然能检索到key,也就可以找到其对应的值。当然,这里就不都说了。 // 比如说这里,我们就可以给Node私有构造函数加一个this.value = value。来形成一个映射关系。 this.key = key; // left和right,也就是指向当前节点的左右子节点的指针。 this.left = null; this.right = null; }; //初始化一个二叉搜索树,声明一个私有变量root代表根节点。 var root = null; // 这是插入节点的私有属性,我们会在insert方法中直接调用。那么我们先去看insert方法。 // 其实这里也不复杂,但是用到了递归,如果大家对递归不太了解,可以去百度搜一下。后面的文章我也会写一些算法的相关内容。 // 我们回到这里,insertNode有两个参数,在insert方法调用的时候我们传入了root,newNode。以便我们从根节点去查找。 var insertNode = function (node,newNode) { // 这里就分为了两种情况,其实后面的方法也是这样,新插入的key和node(第一次执行的时候是root)相对比。 // 如果新插入的key小于node的key,我们要插入到left里,如果是大于等于node的key,就插入到right。这是我们二叉搜索树的规则。 if(newNode.key < node.key) { // 那么这里,如果(或者说是‘直到’)node.left是空,也就是没有元素,那么就插入到node.left中。 // 否则,再调用一下这个函数自身(也就是递归了,这就是为什么上面也可以说是‘直到’,递归必须有递归终止的条件,不然会陷入死循环)。 // 那么下面的else情况也是同理。 if (node.left === null) { node.left = newNode; } else { insertNode(node.left,newNode); } } else { if (node.right === null) { node.right = newNode; } else { insertNode(node.right,newNode); } } } // 中序遍历,首先需要说一下什么是中序遍历。 // 中序遍历是一种以上行顺序访问BST所有节点的遍历方式(也就是从小到大的顺序访问所有节点),BST就是binary search tree。 // 那么该方法有两个参数,一个是node,一个是回调函数(这个回调函数,在本文的应用是下面的console每一个节点的值,当然,你也可以用回调函数做一些羞羞的事)。 var inOrderTraverseNode = function (node,callback) { // 我们要递归使用该方法,前面说了,必须有一个终止回调的条件。这里就是如果节点为空,我们就认为元素遍历完成,停止递归。 if(node !== null) { // 这里,递归调用相同的函数来访问左侧子节点,然后对这个节点进行一些操作,最后访问右侧子节点。 // 到这里,其实中序遍历可以说是,左(左侧子节点),中(该节点),右(右侧子节点)的访问方式。 inOrderTraverseNode(node.left,callback); callback(node.key); inOrderTraverseNode(node.right,callback); } } // 先序遍历,其实我们看代码就可以知道了,先序遍历就是中,左,右。也就是先访问节点本身,再访问左侧然后是右侧子节点。 var preOrderTraverseNode = function (node,callback) { if(node !== null) { callback(node.key); preOrderTraverseNode(node.left,callback); preOrderTraverseNode(node.right,callback); } } // 那么后序遍历呢?额......可想而知,也就是左右中的方式,先访问节点的后代节点,再访问节点本身。 var postOrderTraverseNode = function (node,callback) { if(node !== null) { postOrderTraverseNode(node.left,callback); postOrderTraverseNode(node.right,callback); callback(node.key); } } // 搜索树中的最小值,嗯......我们根据前面了解的内容,猜猜看最小的值是哪一个?如果你说不知道,请从头再来! // 树中最小的值,就是在树的最底层最左侧的节点。那么最大值就是右侧的节点了。 // 为什么会这样呢?如果你还是不知道。请从头再......再来! var minNode = function (node) { // 如果该节点是否是合法值,是->继续,不是,返回null。 if(node) { // 这里就是循环判断node.left是否存在,知道不存在的时候(说明已经得到最左侧的子节点了)就直接返回上一次赋值的node.key。 while(node && node.left !== null) { node = node.left; } return node.key; } return null; } // 同上 var maxNode = function (node) { if(node) { while(node && node.right !== null) { node = node.right; } return node.key; } return null; } // 其实这里,我真的不想说......但是我还是要'磨叽'一下...... // 这里第一个的node参数,在search中传入的是root,因为要从root开始执行逻辑。 // 还有,后面就几乎所有的传入node参数的私有方法,传入的都是root,因为要从root开始。 var searchNode = function (node,key) { // 如果是null了,返回false if(node === null) { return false; } // 这里,其实也就是根据不同的值得大小来判断递归时所需要传入的参数是什么,如果即不大也不小。bingo,说明找到了。 if(key < node.key) { return searchNode(node.left,key); } else if(key > node.key) { return searchNode(node.right,key); } else { return true; } } // 这个方法稍微复杂并且有意思一点,我们详细来说说。 var removeNode = function (node,key) { // 这个判断没什么好说的了,如果是null说明在树中没有这个键,直接返回null就可以了。 if(node === null) { return null; } // 那么这里会有三种情况的判断,如果要找的key小于当前的node.key,就递归调用函数,沿着树的左边一直找下去。 // 那么如果要找的key大于当前的node.key,就沿着树的右边一直找下去。直到找到为止。 if(key < node.key) { node.left = removeNode(node.left,key); return node; } else if(key > node.key) { node.right = removeNode(node.right,key); return node; // 这里就是找到了匹配的key的时候所处理的逻辑了 } else { // 第一种情况就是该节点是没有左右子节点的,我们直接赋值null来移除就可以了。 // 虽然该节点没有子节点,但是有一个父节点,我们需要通过返回null,来使对应的父节点的指针指向null。 // 要记得我们在remove方法中有一个root = removeNode(root,key);赋值语句,可以到下面查看。 // 就是为了让我们父节点接收到更改的指针。 if(node.left === null && node.right === null) { node = null; return node; } // 这里是第二种情况,移除有一个左侧节点或者右侧节点的节点。 // 我们只要跳过这个节点,直接将父节点的指针指向子节点就可以了。 if(node.left === null) { node = node.right; return node; } else if(node.right === null) { node = node.left; return node; } // 最后是第三种情况,稍微复杂些,其实也就是我们要做的操作多一些。 // 首先,我们在找到了需要移除的节点后,需要找到它右边子树种最小的节点。(要移除节点的继承者,也就是说在移除了匹配的节点后,这个值会替换被移除的节点) // 这里findMinNode跟min方法是一样的,只不过返回值稍有不同 var aux = findMinNode(node.right); // 然后用aux去更新要移除节点的值,这个时候,我们已经改变了要移除节点的值,也就相应的移除了该节点。 node.key = aux.key; // 但是这个时候就有两个相同的键了,所以我们要移除aux也就是node.right指向的节点。 node.right = removeNode(node.right,aux.key); // 返回更新后的引用。 return node; // 最后,要提醒大家一个需要注意的地方,移除一个树中的节点,并没有移除该节点下的所有子树或者子节点,这是一个比较容易让人迷惑的误区。 // 比如说,我有一棵下面这样的树 /* A B C D E F G */ // 我想要移除C,并没有把F,G也同时移除,只是单纯的移除了C这个节点,所以我们需要依照二叉搜索树的规则,找到一个合理的值代替这个位置(也就是F)。 // 那么我们用F替换C,并把C移除,更改对应的指针。也就完成了第三种情况的移除操作。 } } var findMinNode = function (node) { while(node && node.left !== null) { node = node.left; } return node; } // 其实这个方法很简单,一看就明白了。 // 如果root是null,说明是一个空树,我们直接让newNode为root就可以了,如果不是,我们再调用insertNode那个私有方法。 this.insert = function (key) { var newNode = new Node(key); if(root === null) { root = newNode; } else { insertNode(root,newNode); } } this.inOrderTraverse = function (callback) { inOrderTraverseNode(root,callback); } this.preOrderTraverse = function (callback) { preOrderTraverseNode(root,callback); } this.postOrderTraverse = function (callback) { postOrderTraverseNode(root,callback); } this.min = function () { return minNode(root); } this.max = function () { return maxNode(root); } this.search = function (key) { return searchNode(root,key); } this.remove = function (key) { root = removeNode(root,key); } } //这个就是callback了 function printNode (value) { console.log(value); } var tree = new BinarySearchTree(); tree.insert(11); tree.insert(7); tree.insert(15); tree.insert(5); tree.insert(3); tree.insert(9); tree.insert(8); tree.insert(10); tree.insert(13); tree.insert(12); tree.insert(14); tree.insert(20); tree.insert(18); tree.insert(25); tree.insert(6); tree.inOrderTraverse(printNode);//3,5,6,7,8,9,10,11,12,13,14,15,18,20,25 tree.remove(15); console.log("--------------") tree.inOrderTraverse(printNode);//3,5,6,7,8,9,10,11,12,13,14,18,20,25 tree.insert(100); console.log("--------------"); tree.inOrderTraverse(printNode);//3,5,6,7,8,9,10,11,12,13,14,18,20,25,100 console.log(tree.min(),"min");//3,“min” console.log(tree.max(),"max");//100,"max" console.log(tree.search(66))//false console.log(tree.search(8))//true console.log("--------------"); tree.preOrderTraverse(printNode);//11,7,5,3,6,9,8,10,18,13,12,14,20,25,100 console.log("--------------"); tree.postOrderTraverse(printNode);//3,6,5,8,10,9,7,12,14,13,100,25,20,18,11
那么我们二叉搜索树就实现完成了。其实如果大家看过前面的文章,这里的BinarySearchTree的实现其实并没有多复杂,而需要注意的是remove一个节点时在对不同的情况的处理方法。说到底,二叉搜索树也就是在插入元素也就是节点的时候要按照必要的规则,所以我们在对树进行操作的时候依照这种规则就可以了。
本来到这里就应该结束了,但是我觉得有必要给大家上几幅图片,解释解释我们上面代码中每一步的执行,在BinarySearchTree是如何操作的。

上图展示了我们依次插入各个数字的时候,二叉搜索树会根据数值的大小来安排它的位置,之后我们做了一个移除15这个节点的操作,那么在移除之后它看起来就是这样的:
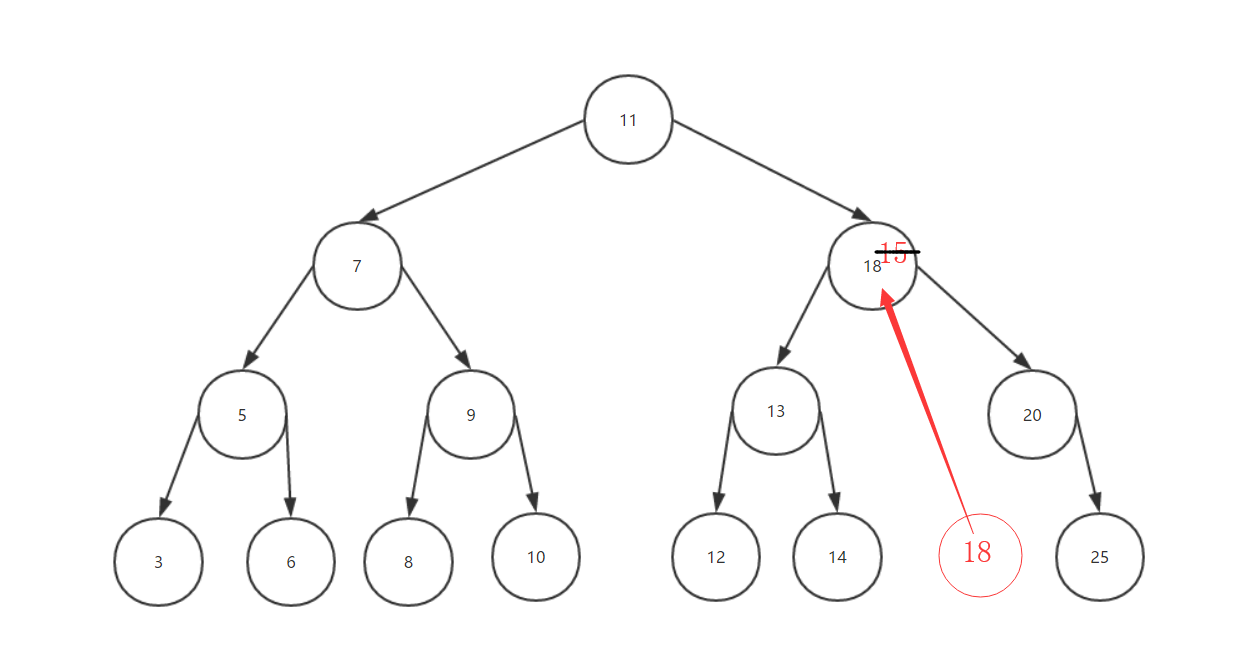
具体的解释在代码的注释中已经有了,这里就不再重复的去啰嗦了。
好了,到这里我们已经基本完成了二叉搜索树的基本实现,那么下一篇文章我们会简单的介绍一下其它类型的树结构。比如自平衡二叉搜索树,红黑树,堆积树等。
最后,由于本人水平有限,能力与大神仍相差甚远,若有错误或不明之处,还望大家不吝赐教指正。非常感谢!
本文来自博客园,作者:Zaking,转载请注明原文链接:https://www.cnblogs.com/zaking/p/8964937.html

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步