
Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜。可惜,笔者不善JAVA,只有PYTHON和SCALA接口。花了不少时间从零开始认识PYTHON和SCALA,不少时间答了VIM的IDE,总算走入正途。下面将一些SPARK集群搭建心得简单写一下。期间也零星碰到不少问题。
//spark
1,去mirror站点下138M大小的编译好的包,去下SCALA 2.9.X,HADOOP该启动的启动
2,配置各种$HOME和$PATH
配置$SPARK_HOME/conf/spark-env.sh中的javahome,scalehome,sparkhome
配置slaves文件加入主机名
配置.bash_profile javahome,scalehome,sparkhome 和path
3,把1主和2备用SCP同步一下
scp scala root@192.168.137.104:/root/soft
scp spark root@192.168.137.104:/root
主:start-all.sh
jps多了一个master,jps多了一个worker
http://cent3:8080/
http://cent4:8081/
http://cent2:8081/
4,跑自带实例
./run org.apache.spark.examples.SparkPi local
./run-example org.apache.spark.examples.SparkPi spark://cent3:7077
./run-example org.apache.spark.examples.SparkLR spark://cent3:7077
./run-example org.apache.spark.examples.SparkKMeans spark://cent3:7077 ./kmeans_data.txt 2 1
5,跑spark-shell 【SBT理解不能。。-_-,好复杂】
MASTER=spark://cent3:7077 ./spark-shell
scala> System.setProperty("spark.executor.memory", "512") #调优MEM参数
scala> System.setProperty("spark.cores.max", "5") #调优CPU参数
scala> val file = sc.textFile("hdfs://cent3:9000/user/root/mandela.txt")
scala> val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
scala> count.collect()
res0: Array[(java.lang.String, Int)] = Array((peacefully,2), ("",15), (domination,,1), (African,3), (Peace,1), (handed,1), (awarded,1), (era,,1), (cut,1), (example,1), (my,1), (probed,1), (as,2), (country's,3), (rural,1), (his,9), (voluntary,1), (when,3), (last,1), (elections,1), (its,2), (who,1), (appearance,1), (teeth,1), (neighborhood,1), (three,1), (new,1), (jail,1), (president,3), (Charged,1), (died,1), (prisoner.,1), (mission,1), (years,2), (Mandela,6), (Madiba,,1), (myself,1), (1999.,1), (disease,1), (President,3), (after,1), (grip,1), (ovation,1), (office.,1), (from,8), (prolonged,1), (Nobel,1), (sides,1), (died:,1), (other,1), (personal,1), (wounds.,1), (one,1), (Africa,2), (obscurity,1), (As,1), (forging,1), (son,1), (this,1), (president,,1), (has,2), (Mandela,,3), (apartheid,...
6,跑pyspark实例
cd /root/spark/python
[ALONE+LOCAL] pyspark examples/wordcount.py local[2] mandela.txt
[ALONE+HDFS] pyspark examples/wordcount.py local[2] hdfs://cent3:9000/user/root/mandela.txt
[CLUSTER+LOCAL] pyspark examples/wordcount.py spark://cent3:7077 mandela.txt 前提是所有Master和Worker主机上都有
[CLUSTER+HDFS pyspark examples/wordcount.py spark://cent3:7077 hdfs://cent3:9000/user/root/mandela.txt
好,至此基本上可以随便玩了,github上有官网python例子,省了不少事儿。下面开始他的真身验明,交手C/CPP/HADOOP
环境介绍:
1,某想 E49 Inter Core i5-3320M CPU@2.6GHz / 2048MB / 128G 某星 SSD
2,VituralBox 三台虚拟机cent2,cent3,cent4。其中cent3是老大
虚拟机配置: 1 core / 2048MB / 10G VMDX(SPLIT=2G)/ CENTOS 6,不启用过量分配。
3,单挑对象简介
- 纯C:以stdio的fgets作为标准输入,sscanf拆分,在一套循环内完成word count。
- CPP:以std::cin作为标准输入,未加速,自动空格拆分,用pipe模拟MR,一个读,一个汇总。
- HADOOP:以CPP为模板做Streaming,HDFS做介质。
- SPARK:本地LOCAL用单线程、双线程共同测试(虽然CPU是1core)
- SPARK:AMP最推荐的运载方式,不多言。
4,关联文件,从网上DOWN篇E文小说,复制成100M/500M/1024M,做WORDCOUNT。
5,所有平台做初始配置,不调优。
最终测得结果如下:
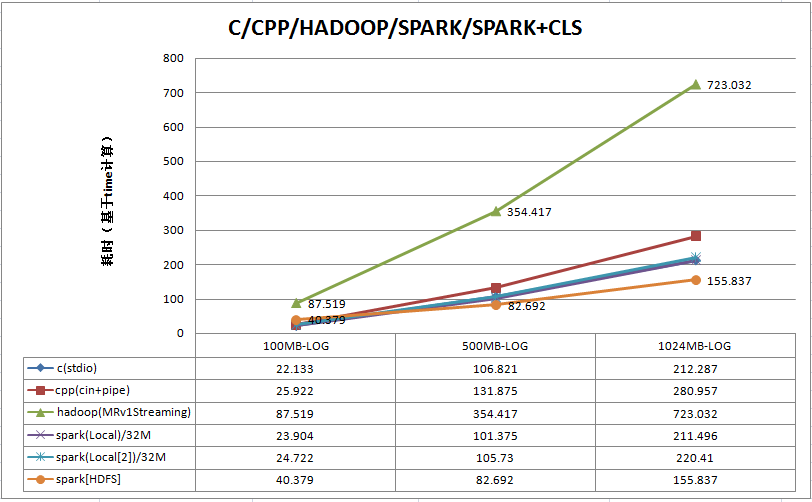
结论:
- 在单机版上spark与纯C不分伯仲,但也领先了cpp不少。
- 在分布式上,的确比hadoop快N倍,真心强,这还是在split 32MB的情况下。
- 此次纯c的mmap和OS RawDevice未参与,即便参与估计也就再多给1~3秒,个人感觉spark应该有用到这块一口闷的关键技术。
- 此次仅仅是wordcount,谣传k-means效果恐怖,有空再测试一把。
- 由于1核VM,基本上跑起来CPU就是100%。不过SPARK有个特点就是SYS%用的少,这应该就是纯MEM计算的特征。
心得:
- 集群搭建不难,难在lamada编程,真心考验脑力,有时感觉比ML还复杂,多少理解不能,但还得去学,应该蛮有意思的。
- python的同学别高兴太早,关键代码还是要lamada编程。
- java和scala同学的福音,自带N多MLLIB。
- 中文版调优文档较少,国外论坛和WIKI较少,还是得自学。希望国内有人开个BBS组织一下。^_^

