
注释提取及回滚
目的:iOS SDK 开发,代码不应带有注释,但是为方便后续开发,注释还是需要的。(还有点问题,主要是正则问题,待我正则有所小成再来搞定它) (这个问题已针对我自身代码搞定了)
目标:将代码中注释内容提取写入txt文件,将原注释位置用特定标识替换,待打包完成后再将注释内容回滚。
提取注释:注释方式包括 “//注视著是” 、“#pragma mark - 注释注释”、“/*注视著是*/” 三种
大体步骤:
提取注释
1、获取指定文件路径下的所有 .h 和 .m 和.mm 文件
2、提取 1 中的所有文件的注释并替换为uuid
3、格式化成json写入txt文件
回滚
1、获取指定文件路径下的所有 .h 和 .m和.mm 文件
2、获取回滚文件内容,遍历回滚文件和工程文件,将特定字符串替换为原注释内容
具体体现:
替换前:
// 加载pop框
/** 展示Pop 推荐使用链式语法 */
#pragma mark - 颜色转换
替换后:
//e295ea66-cf58-11e7-bff7-a860b63b7bbf
/*e295d9cf-cf58-11e7-b8d3-a860b63b7bbf*/
//e295e1ba-cf58-11e7-bd21-a860b63b7bbf
使用:
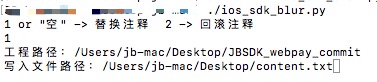
提取
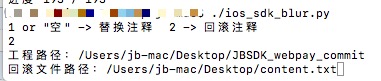
回滚
代码:
#!/usr/bin/env python
#coding=utf8
import os
import re
import json
import sys
import uuid
reload(sys)
sys.setdefaultencoding('utf8')
#获取路径下的所有文件
def get_all_files():
path = raw_input('工程路径:')
try:
all_files = []
for root, dirs, files in os.walk(path):
for file in files:
if os.path.splitext(file)[1] == '.m' or os.path.splitext(file)[1] == '.h' or os.path.splitext(file)[1] == '.mm':
all_files.append(os.path.join(root, file))
except:
print '获取文件失败'
return all_files
#提取注释写入文件
def get_all_content():
files = get_all_files()
re_before_contents = []
rollback_path = raw_input('写入文件路径:')
for index_pag, file_path in enumerate(files):
print '进度',index_pag + 1,'/',len(files)
with open(file_path,'r') as file:
#全部内容
content = file.read()
#多行注释
mlines_mth = re.findall("\/\*[^(;q=0.8)].*?\*\/",content,re.S)
for item in mlines_mth:
re_content = '/*' + str(uuid.uuid1()) + '*/'
save_arr = [re_content, item]
re_before_contents.append(save_arr)
content = content.replace(item,re_content,1)
#正常注释
normal_mth = re.findall("//[^\n(mclient)(sdktest)].*?$",content, flags=re.DOTALL+re.MULTILINE)
for item in normal_mth:
re_content = '//' + str(uuid.uuid1())
save_arr = [re_content, item]
re_before_contents.append(save_arr)
content = content.replace(item,re_content,1)
#mark 注释
mark_mth = re.findall("#pragma mark.*?\n", content)
for item in mark_mth:
re_content = '//' + str(uuid.uuid1()) + '\n'
save_arr = [re_content, item]
re_before_contents.append(save_arr)
content = content.replace(item,re_content,1)
with open(file_path, 'w') as new_file:
new_file.write(content)
with open(rollback_path,'w') as file:
JsonStr = json.dumps(re_before_contents)
file.write(JsonStr)
def get_annotation():
files = get_all_files()
rollback_path = raw_input('回滚文件路径:')
with open(rollback_path, 'r') as file:
content = file.read()
content_list = list(json.loads(content))
for re_index, file_path in enumerate(files):
with open(file_path, 'r') as file:
content = file.read()
print '回滚进度:', re_index + 1, '/', len(files)
index = 0
while True:
if index < len(content_list):
re_content = content_list[index]
if re_content[0] in content:
content = content.replace(re_content[0], re_content[1])
content_list.remove(re_content)
content_list = content_list
else:
index += 1
else:
break
with open(file_path, 'w') as new_file:
new_file.write(content)
if __name__ == "__main__":
select_method = raw_input('1 or "空" -> 替换注释 2 -> 回滚注释\n')
if select_method == '1' or select_method == '':#提取注释内容
get_all_content()
elif select_method == '2':#还原
get_annotation()
else:
print '结束'
#/Users/jb-mac/Desktop/JBSDK_webpay_commit
#/Users/jb-mac/Desktop/content.txt
