

理清Java中的编码解码转换
1、字符集及编码方式
概括:字符编码方式及大端小端
详细:彻底理解字符编码
可以通过Charset.availableCharsets()获取Java支持的字符集,以JDK8为例,得到其支持的字符集:



1 SortedMap<String, Charset> charsets = Charset.availableCharsets(); 2 System.out.println(charsets.size()); 3 for (String key : charsets.keySet()) { 4 System.out.println(key + ": " + charsets.get(key)); 5 } 6 7 8 //结果 9 169 10 Big5: Big5 11 Big5-HKSCS: Big5-HKSCS 12 CESU-8: CESU-8 13 EUC-JP: EUC-JP 14 EUC-KR: EUC-KR 15 GB18030: GB18030 16 GB2312: GB2312 17 GBK: GBK 18 IBM-Thai: IBM-Thai 19 IBM00858: IBM00858 20 IBM01140: IBM01140 21 IBM01141: IBM01141 22 IBM01142: IBM01142 23 IBM01143: IBM01143 24 IBM01144: IBM01144 25 IBM01145: IBM01145 26 IBM01146: IBM01146 27 IBM01147: IBM01147 28 IBM01148: IBM01148 29 IBM01149: IBM01149 30 IBM037: IBM037 31 IBM1026: IBM1026 32 IBM1047: IBM1047 33 IBM273: IBM273 34 IBM277: IBM277 35 IBM278: IBM278 36 IBM280: IBM280 37 IBM284: IBM284 38 IBM285: IBM285 39 IBM290: IBM290 40 IBM297: IBM297 41 IBM420: IBM420 42 IBM424: IBM424 43 IBM437: IBM437 44 IBM500: IBM500 45 IBM775: IBM775 46 IBM850: IBM850 47 IBM852: IBM852 48 IBM855: IBM855 49 IBM857: IBM857 50 IBM860: IBM860 51 IBM861: IBM861 52 IBM862: IBM862 53 IBM863: IBM863 54 IBM864: IBM864 55 IBM865: IBM865 56 IBM866: IBM866 57 IBM868: IBM868 58 IBM869: IBM869 59 IBM870: IBM870 60 IBM871: IBM871 61 IBM918: IBM918 62 ISO-2022-CN: ISO-2022-CN 63 ISO-2022-JP: ISO-2022-JP 64 ISO-2022-JP-2: ISO-2022-JP-2 65 ISO-2022-KR: ISO-2022-KR 66 ISO-8859-1: ISO-8859-1 67 ISO-8859-13: ISO-8859-13 68 ISO-8859-15: ISO-8859-15 69 ISO-8859-2: ISO-8859-2 70 ISO-8859-3: ISO-8859-3 71 ISO-8859-4: ISO-8859-4 72 ISO-8859-5: ISO-8859-5 73 ISO-8859-6: ISO-8859-6 74 ISO-8859-7: ISO-8859-7 75 ISO-8859-8: ISO-8859-8 76 ISO-8859-9: ISO-8859-9 77 JIS_X0201: JIS_X0201 78 JIS_X0212-1990: JIS_X0212-1990 79 KOI8-R: KOI8-R 80 KOI8-U: KOI8-U 81 Shift_JIS: Shift_JIS 82 TIS-620: TIS-620 83 US-ASCII: US-ASCII 84 UTF-16: UTF-16 85 UTF-16BE: UTF-16BE 86 UTF-16LE: UTF-16LE 87 UTF-32: UTF-32 88 UTF-32BE: UTF-32BE 89 UTF-32LE: UTF-32LE 90 UTF-8: UTF-8 91 windows-1250: windows-1250 92 windows-1251: windows-1251 93 windows-1252: windows-1252 94 windows-1253: windows-1253 95 windows-1254: windows-1254 96 windows-1255: windows-1255 97 windows-1256: windows-1256 98 windows-1257: windows-1257 99 windows-1258: windows-1258 100 windows-31j: windows-31j 101 x-Big5-HKSCS-2001: x-Big5-HKSCS-2001 102 x-Big5-Solaris: x-Big5-Solaris 103 x-euc-jp-linux: x-euc-jp-linux 104 x-EUC-TW: x-EUC-TW 105 x-eucJP-Open: x-eucJP-Open 106 x-IBM1006: x-IBM1006 107 x-IBM1025: x-IBM1025 108 x-IBM1046: x-IBM1046 109 x-IBM1097: x-IBM1097 110 x-IBM1098: x-IBM1098 111 x-IBM1112: x-IBM1112 112 x-IBM1122: x-IBM1122 113 x-IBM1123: x-IBM1123 114 x-IBM1124: x-IBM1124 115 x-IBM1364: x-IBM1364 116 x-IBM1381: x-IBM1381 117 x-IBM1383: x-IBM1383 118 x-IBM300: x-IBM300 119 x-IBM33722: x-IBM33722 120 x-IBM737: x-IBM737 121 x-IBM833: x-IBM833 122 x-IBM834: x-IBM834 123 x-IBM856: x-IBM856 124 x-IBM874: x-IBM874 125 x-IBM875: x-IBM875 126 x-IBM921: x-IBM921 127 x-IBM922: x-IBM922 128 x-IBM930: x-IBM930 129 x-IBM933: x-IBM933 130 x-IBM935: x-IBM935 131 x-IBM937: x-IBM937 132 x-IBM939: x-IBM939 133 x-IBM942: x-IBM942 134 x-IBM942C: x-IBM942C 135 x-IBM943: x-IBM943 136 x-IBM943C: x-IBM943C 137 x-IBM948: x-IBM948 138 x-IBM949: x-IBM949 139 x-IBM949C: x-IBM949C 140 x-IBM950: x-IBM950 141 x-IBM964: x-IBM964 142 x-IBM970: x-IBM970 143 x-ISCII91: x-ISCII91 144 x-ISO-2022-CN-CNS: x-ISO-2022-CN-CNS 145 x-ISO-2022-CN-GB: x-ISO-2022-CN-GB 146 x-iso-8859-11: x-iso-8859-11 147 x-JIS0208: x-JIS0208 148 x-JISAutoDetect: x-JISAutoDetect 149 x-Johab: x-Johab 150 x-MacArabic: x-MacArabic 151 x-MacCentralEurope: x-MacCentralEurope 152 x-MacCroatian: x-MacCroatian 153 x-MacCyrillic: x-MacCyrillic 154 x-MacDingbat: x-MacDingbat 155 x-MacGreek: x-MacGreek 156 x-MacHebrew: x-MacHebrew 157 x-MacIceland: x-MacIceland 158 x-MacRoman: x-MacRoman 159 x-MacRomania: x-MacRomania 160 x-MacSymbol: x-MacSymbol 161 x-MacThai: x-MacThai 162 x-MacTurkish: x-MacTurkish 163 x-MacUkraine: x-MacUkraine 164 x-MS932_0213: x-MS932_0213 165 x-MS950-HKSCS: x-MS950-HKSCS 166 x-MS950-HKSCS-XP: x-MS950-HKSCS-XP 167 x-mswin-936: x-mswin-936 168 x-PCK: x-PCK 169 x-SJIS_0213: x-SJIS_0213 170 x-UTF-16LE-BOM: x-UTF-16LE-BOM 171 X-UTF-32BE-BOM: X-UTF-32BE-BOM 172 X-UTF-32LE-BOM: X-UTF-32LE-BOM 173 x-windows-50220: x-windows-50220 174 x-windows-50221: x-windows-50221 175 x-windows-874: x-windows-874 176 x-windows-949: x-windows-949 177 x-windows-950: x-windows-950 178 x-windows-iso2022jp: x-windows-iso2022jp
2、Java中的几种编码格式
2.1、文件、项目、工作空间的编码格式
默认是【文件编码格式】继承于【项目编码格式】继承于【工作空间编码格式】继承于【系统编码格式】。都可以自己设置。
以eclipse里为例:
-
- 【工作空间编码格式】设置:在Winodws->Preferences->General->Workspace里设置Text file encoding,默认继承于【系统编码格式】如简体中文环境下是GBK。这样每次新建工程默认都会以此编码
- 【项目编码格式】设置:在项目右键->Source里设置Text file encoding,默认继承于【工作空间编码格式】。这样在项目下新建文件如java源文件会以此编码。
- 【文件编码格式】设置:在文件右键->Source里设置Text file encoding,默认继承于【项目编码格式】。
值得注意的是,若在eclipse里保存了.java文件后又用上述方式修改了该文件的编码方式,则可能会出现乱码,并且新输入的代码可能也保存不了,提示输入的有些字符无法用当前编码方式映射保存。乱码原因是用新指定的编码格式来解码原来格式编码成的文件,保存不了原因是新输入的有些字符如中文无法用新编码格式如ISO8859-1编码。所以要修改已写好的.java文件的编码方式,为避免乱码等问题可以在文本编辑器中打开并另存为其他格式。
2.2、运行环境的编码格式
和外部进行数据交换(如读文件时)的时候所用的编码格式。可以通过 Charset.defaultCharset().name() 查看默认编码格式,继承于【文件编码格式】。
Charset.defaultCharset()方法如下:可见 Charset.defaultCharset()优先采用 [调用此方法(直接或间接调用)的main函数所在的文件的] file.encoding,无法确认的话用UTF-8,
1 public static Charset defaultCharset() { 2 if (defaultCharset == null) { 3 synchronized (Charset.class) { 4 String csn = AccessController.doPrivileged( 5 new GetPropertyAction("file.encoding")); 6 Charset cs = lookup(csn); 7 if (cs != null) 8 defaultCharset = cs; 9 else 10 defaultCharset = forName("UTF-8"); 11 } 12 } 13 return defaultCharset; 14 }
需要注意的是,上面的file.encoding指的是main函数所在文件的编码方式,而不是Charset.defaultCharset()代码所在文件的编码方式。如有file1.java、file2.java两个文件,其编码方式不同,file1.java有个静态方法getFileEncoding()返回Charset.defaultCharset(),则file2.java里调用file1.getFileEncoding()得到的是file2.java的编码方式。
另,可在程序里获取file.encoding等system properties:
Properties prop = System.getProperties(); Iterator it = prop.keySet().iterator(); while (it.hasNext()) { String key = it.next().toString(); System.out.println(key + ": " + prop.getProperty(key)); }
结果中有几个值得注意的属性:
file.encoding: UTF-16 //即前面提到的file.encoding sun.jnu.encoding: GBK //网上说与文件命名、命令行参数等有关 sun.io.unicode.encoding: UnicodeLittle //应该是Java内部编码,UTF-16L sun.cpu.endian: little //CPU为小端
这里的file.encoding指的是main函数所在文件的编码方式。
2.3、内部的编码格式
Java内部则用的是UTF-16BE编码,所有外部字符内容在Java 程序内全部转换成此编码格式。
Java中的 char 能否表示汉字呢?答案是只能表示基本范围内(Unicode 编号 0x4E00-0x9FA5)的汉字。因为Java char 占两个字节,且存的不是UTF-16的字符编码,而是存的字符的 Unicode 值,故 char 表示的是[U+0000, U+FFFF]之间的Unicode字符,即BMP范围内的字符,该范围内的字符包含了基本汉字的范围 [0x4E00, 0x9FA5]。
如何证明?
// Unicode BMP(基本平面)的范围是[0x4e00,0x9fa5],两个边界的字符分别是'一'、'龥'。下面验证在Java中char表示的是Unicode值而非UTF-16编码值 System.out.println(Integer.toHexString('一' & 0xffff));//4e00 System.out.println(Integer.toHexString('龥' & 0xffff));//9fa5
.java文件中的字符串等(3.1)、外部文件、网络资源、数据库资源等读入后转为内部编码格式的数据;写出时从内部编码格式转为指定格式的数据;字符串在内存中也可按指定编码格式进行转换(3.2)。详见章节3。
3、Java中的数据编解码转换
.class文件:UTF-8格式
JVM内部:UTF-16格式
解码:
读:从外部读入(转换为Java内部编码UTF-16):read;用于显示:文本编辑器打开显示
解码成字符(串):new string(byte[])
编码:
写:用于保存或输出到外部(与字符流相关的才需编码,将字符按编码方式转成字节流后输出;若是字节流则直接输出,无需编码)或与外界(网络、数据库等)交互:与字符相关的write,如InputStreamReader、OutputStreamWriter、BufferedWriter等
转变成字节:String.getBytes()
字符(串)与byte[]之间转换时需要提供编码格式参数(然而很多时候我们没提供,其实此时采用了默认格式,即file.encoding)
String值始终是以内部编码格式(UTF-16)存储
3.1、默认转换:Java源文件到.class文件到内存
即编译器根据.java文件的编码格式读出其中的内容并编译成UTF-8格式的.class文件,包括字符串等;运行时JVM按UTF-8格式读取.class文件到内存中。
-
- 保存:保存.java文件时,以file.encoding将文件内容编码成二进制存入文件。
- 编译:运行javac时若没有用-encoding参数指定源文件的编码方式,则以默认格式Charset.defaultCharset()即file.encoding来解码.java文件并编译成UTF-8格式.class文件。
- 运行:运行Java程序时JVM以UTF-8格式解码.class文件并读入到内存中,此时包括字符串等都以UTF-16格式存在于内存中了。
上述过程一般不需用户干预,除非用户指定其他参数否则可以看出其就是用file.encoding格式来读.java文件并转成内部UTF-16格式的数据,因此这些默认转换一般不会出错。
3.2、运行中转换:网络文件、本地文件、数据库中的内容等
3.2.1、读入
-
- 从本地文件中读到内存:按字节读流的话结果(byte[])与程序运行环境的编码格式方式无关,只与文件的编码方式有关;按字符(串)读则与运行环境采用什么编码格式有关,需要将之指定为本地文件的编码方式或父集。这样在读时会以指定编码格式来解码被读取的文件,转变成内部的UTF-16格式于内存中。
- 从网络文件中读到内存:与上类似。对于与浏览器交互的程序,如Servlet、JSP(也是转换成Servlet放在Web容器临时目录)等,若没有指定编码方式,则默认以ISO8859-1解码接收到的参数、编码返回的数据给浏览器。过程图如下:
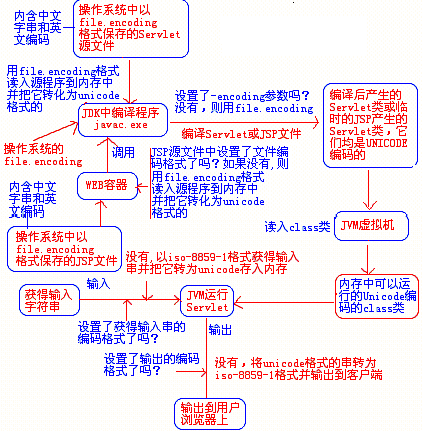
-
- 从数据库中读取到内存:与上类似,只不过默认编码格式也为8859-1。对于几乎所有数据库的JDBC驱动程序,默认的在JAVA程序和数据库之间传递数据都是以ISO-8859-1为默认编码格式的,所以,我们的程序在向数据库内存储包含中文的数据时,JDBC首先是把程序内部的UNICODE编码格式的数据转化为ISO-8859-1的格式,然后传递到数据库中,在数据库保存数据时,它默认即以ISO-8859-1保存。所以,这是为什么我们常常在数据库中读出的中文数据是乱码。 过程图如下:
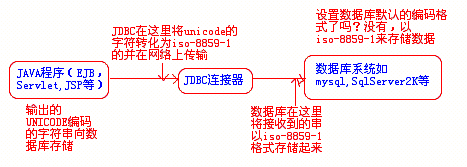
3.2.2、写出
-
- 从内存中写入到文件:将内存中UTF-16格式的内容 编码成 程序运行环境的编格式的内容,写出到文件。
- 内存中转换:
- 内存中数据编码格式转换:转换时一般都要指定某种编码格式,未指定的话采用Charset.defaultCharset()即file.encoding
- String转byte[]如getBytes():Java内部编码格式(UTF-16)的数据转换成指定格式的数据
- byte[]转String:以指定格式将byte[]数据解码成字符串
- 其他
- 内存中数据编码格式转换:转换时一般都要指定某种编码格式,未指定的话采用Charset.defaultCharset()即file.encoding
3.2.3、console交互:(包含上述的读和写过程)
-
- 这种情况,运行该类首先需要JVM支持,即操作系统中必须安装有JRE。运行过程是这样的:首先java启动JVM,此时JVM读出操作系统中保存的class文件并把内容读入内存中,此时内存中为UNICODE格式的class类,然后JVM运行它,如果此时此类需要接收用户输入,则类会默认用file.encoding编码格式对用户输入的串进行编码并转化为unicode保存入内存(用户可以设置输入流的编码格式)。程序运行后,产生的字符串(UNICODE编码的)再回交给JVM,最后JRE把此字符串再转化为file.encoding格式(用户可以设置输出流的编码格式)传递给操作系统显示接口并输出到界面上。 过程图如下:
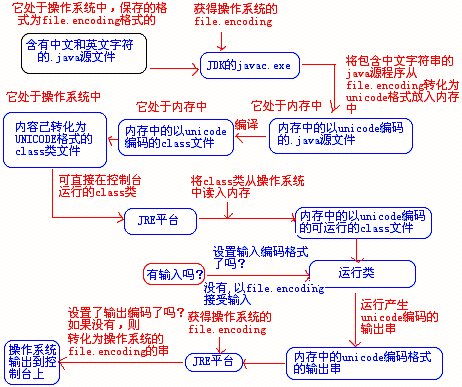
以 下面代码为例,涉及到多次编解码转换(假定文件以UTF-8编码即file.encoding为UTF-8):
FileWriter fw = new FileWriter("文件1.txt"); fw.write(new String("abc".getBytes("GBK"),"UTF-16")); fw.close();
- 默认转换
- 编码:保存.java源文件时,"abc"在文件中以file.encoding的格式编码成二进制存着。
- 解码编码:编译时,编译器以file.encoding格式解码.java文件并编译成Java内部编码格式即UTF-16格式的.class文件。
- 解码:程序运行时,JVM加载.class文件,以内部编码格式UTF-16解码.class文件,故"abc"以此格式存在内存中。
- 程序中转换
- 编码:"abc".getBytes("GBK")将内存中UTF-16格式的"abc"编码成GBK格式,得到字节数组。
- 解码:new String(bytes,"UTF-16"))将上步的GBK格式的字节数组解码成UTF-16的字符串。
- 编码:fw.write()以FileWriter的默认编码方式Charset.defaultCharset()将上步的String编码成二进制写到文件里,当然也可以指定所用的编码方式。所以要正确显示文件里的内容,需要以写入时的相应编码方式来解码打开。
另附一张不是很贴切的图,关于String、char[]、byte[]之间的转换:
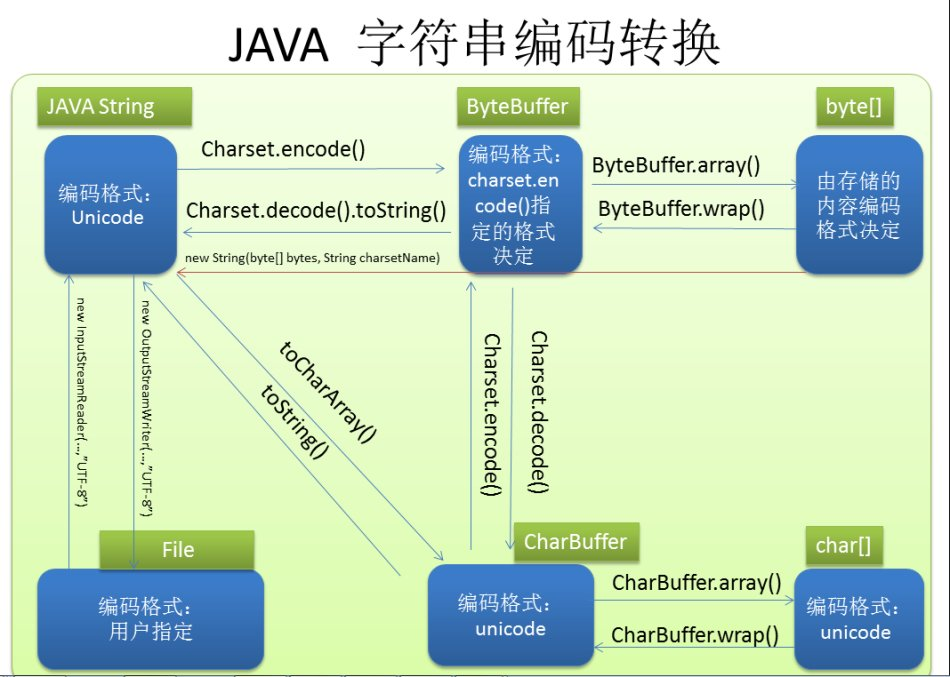
4、参考资料
[1]、http://www.voidcn.com/blog/u013678930/article/p-6166506.html
[2]、http://www.iteye.com/topic/112049


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 为DeepSeek添加本地知识库
· 精选4款基于.NET开源、功能强大的通讯调试工具
· DeepSeek智能编程
· 大模型工具KTransformer的安装
· [计算机/硬件/GPU] 显卡