
Java基础学习(一)数据结构
基础问题
1. 几类数据结构的定义和区别是什么?
2. 容器的数据结构底层是怎么实现的?怎么进行扩容?
3. 容器的线程安全怎么实现?
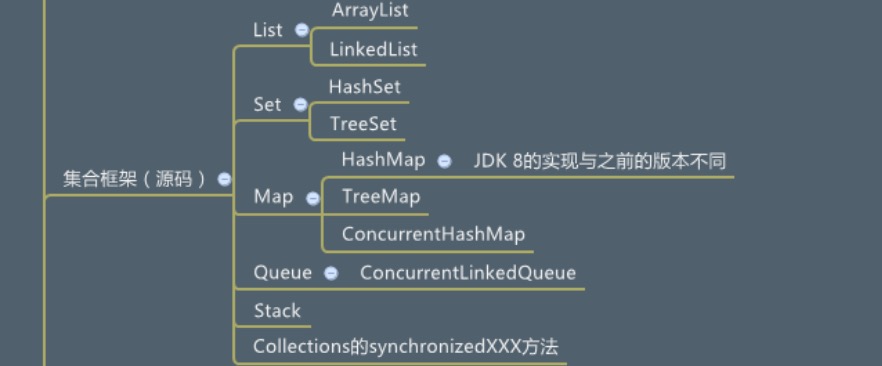
一、List容器
数据有序,允许重复数据,线程不安全。
1. linkedList 底层用双向链表实现,操作速度快,可以在头、尾、[n]操作数据。
2. ArrayList 底层用数组实现,查询速度快,默认数组大小是10。可以通过new ArrayList<Object>(n)设置n的值来指定数组的size,这样可以节省空间并避免数组扩容引起的效率下降。
ArrayList的扩容:当数据大小超过数组大小时,arrayList通过ensureCapacityd 调grow方法进行扩容,以下是jdk 1.8源码
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//默认扩容量为原size的一半
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
//最大扩容到Intger.MAX_VALUE
newCapacity = hugeCapacity(minCapacity);
// 直接用数组的copy进行扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
二、Set容器
set保存的数据不重复,set的底层都是通过其对应的map来实现的,例如HashSet底层是HashMap实现。所以常见Set与其对应的map一样是非线程安全的,但guava里实现了线程安全的ConcurrentHashSet(线程安全原理见下方ConcurrentHashMap)。
1. HashSet() :快速的定位、读取,会根据hash值来存放,因此读取出来的顺序不是插入的顺序。通常用于数据去重。
Hashset 集合收进一个对象时,会调用对象的hashcode()得到其Hashcode值来决定他的存储位置。默认的hashCode方法,是对对象进行hashCode;默认的equals方法也是比较对象是否相等。所以如果不重写这两个方法的话,下方例子中p1 和p2 都会被保存 而不会被去重。
Person p1 = new Person("fan");
Person p2 = new Person("fan");
Set<Person> personHashSet = new HashSet<Person>();
Collections.addAll(personHashSet, p1, p2);
2. TreeSet():是按照hash值的顺序(红黑树)排列的,如果要把一个对象添加进TreeSet时,则该对象的类必须实现Comparable接口。 通常用于去重+排序。
例,下方Person类没实现Comparable,添加时会报错“Person cannot be cast to java.lang.Comparable”
Person p1= new Person("小明");
Person p2= new Person("小花");
TreeSet<Person> personTreeSet = new TreeSet<>();
personTreeSet.add(p1);
personTreeSet.add(p2);
3. LinkedHashSet():按照插入顺序保存数据。 用于去重+保留插入顺序。
三、Map容器
map存储 key-value形式数据,HashMap和TreeMap不是线程安全的,ConcurrentHashMap是线程安全的
1. HashMap(): 在底层数据结构上采用了数组+链表+红黑树数组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,当链表长度大于8时转为红黑树。默认初始容量是16,负载因子0.75。
存储原理:Put键值对的时候会先计算对应Key的hash值通过hash值来确定存放的地址->如果空则存入一个新的节点(Node),反之根据前面得到的节点p的hash值以及key跟传入的hash值以及参数进行比较,如果一样则替覆盖,不一致则以链表形式保存,把当前传来的参数生成一个新的节点保存在前一节点中。若链表长度>8,则红黑树形式保存。
扩容:发生扩容的时候有两种情况,一种是元素达到阀值了,一种是HashMap准备树形化但又发现数组太短<64,均会发生扩容。
下方是树形化扩容的源码注释
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {}
下方是扩容的源码注释
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
* @return the table
*
*
* 初始化或者翻倍表大小。
* 如果表为null,则根据存放在threshold变量中的初始化capacity的值来分配table内存
* (这个注释说的很清楚,在实例化HashMap时,capacity其实是存放在了成员变量threshold中,
* 注意,HashMap中没有capacity这个成员变量)
* 。如果表不为null,由于我们使用2的幂来扩容,
* 则每个bin元素要么还是在原来的bucket中,要么在2的幂中
* 此方法功能:初始化或扩容
*/
final Node<K,V>[] resize() {}
2. TreeMap(): 有序的key-value集合,通过红黑树实现。红黑树是一颗平衡二叉查找树,其特点是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个子节点,其左右子树的高度都相近。
遍历:使用entrySet遍历方式要比keySet遍历方式快。entrySet遍历方式获取Value对象是直接从Entry对象中直接获得,时间复杂度T(n)=o(1);keySet遍历获取Value对象则要从Map中重新获取,时间复杂度T(n)=o(n);keySet遍历Map方式比entrySet遍历Map方式多了一次循环,多遍历了一次table,当Map的size越大时,遍历的效率差别就越大。
3.ConcurrentHashMap(): 线程安全的,数组+链表(红黑树)的结构,通过synchronized(Node)和cas(compare and swap)新增node。读操作不加锁。
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K, V> e = f; ; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K, V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
} else if (f instanceof TreeBin) { // 红黑树
Node<K, V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
// 具体源码我们就不看了,扩容部分后面说
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
问题:
1. hashmap什么时候扩容?怎么扩容?【答案见上方三.1】
2. A put到hashMap里,改下A的值再push到map里 会发生什么?【答案直接替换】
3. concurrent分段锁 get不加锁 写是加锁 1.8怎么实现的?【答案见三.3】
4. Q和stack的实现原理?
5. 怎样代码实现一个BlockingQ? 怎样代码实现一个线程池?
【实现线程池 https://www.cnblogs.com/wxwall/p/7050698.html】
6. list扩容要多久?
参考资料:
1.JDK 1.8 HashMap工作原理和扩容机制(源码解析)https://blog.csdn.net/u010890358/article/details/80496144
2.jdk1.8 HashMap的扩容resize()方法详解 http://www.cnblogs.com/shianliang/p/9233199.html
3.ConcurrentHashMap的JDK1.8实现 https://blog.csdn.net/fouy_yun/article/details/77816587

