
Python中的字符串与字符编码
本节内容:
- 前言
- 相关概念
- Python中的默认编码
- Python2与Python3中对字符串的支持
- 字符编码转换
一、前言
Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章。有的人云亦云,也有的写得很深入。近日看到某知名培训机构的教学视频中再次谈及此问题,讲解的还是不尽人意,所以才想写这篇文字。一方面,梳理一下相关知识,另一方面,希望给其他人些许帮助。
Python2的 默认编码 是ASCII,不能识别中文字符,需要显式指定字符编码;Python3的 默认编码 为Unicode,可以识别中文字符。
相信大家在很多文章中都看到过类似上面这样“对Python中中文处理”的解释,也相信大家在最初看到这样的解释的时候确实觉得明白了。可是时间久了之后,再重复遇到相关问题就会觉得貌似理解的又不是那么清楚了。如果我们了解上面说的默认编码的作用是什么,我们就会更清晰的明白那句话的含义。
需要说明的是,“字符编码是什么”,以及“字符编码的发展过程” 不是本节讨论的话题,这些内容可以参考我之前的 <<这篇文章>>。
二、相关概念
1. 字符与字节
一个字符不等价于一个字节,字符是人类能够识别的符号,而这些符号要保存到计算的存储中就需要用计算机能够识别的字节来表示。一个字符往往有多种表示方法,不同的表示方法会使用不同的字节数。这里所说的不同的表示方法就是指字符编码,比如字母A-Z都可以用ASCII码表示(占用一个字节),也可以用UNICODE表示(占两个字节),还可以用UTF-8表示(占用一个字节)。字符编码的作用就是将人类可识别的字符转换为机器可识别的字节码,以及反向过程。
UNICDOE才是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。关于这点,我们可以在Python的官方文档中经常可以看到这样的描述"Unicode string" , " translating a Unicode string into a sequence of bytes"
我们写代码是写在文件中的,而字符是以字节形式保存在文件中的,因此当我们在文件中定义个字符串时被当做字节串也是可以理解的。但是,我们需要的是字符串,而不是字节串。一个优秀的编程语言,应该严格区分两者的关系并提供巧妙的完美的支持。JAVA语言就很好,以至于了解Python和PHP之前我从来没有考虑过这些不应该由程序员来处理的问题。遗憾的是,很多编程语言试图混淆“字符串”和“字节串”,他们把字节串当做字符串来使用,PHP和Python2都属于这种编程语言。最能说明这个问题的操作就是取一个包含中文字符的字符串的长度:
- 对字符串取长度,结果应该是所有字符串的个数,无论中文还是英文
- 对字符串对应的字节串取长度,就跟编码(encode)过程使用的字符编码有关了(比如:UTF-8编码,一个中文字符需要用3个字节来表示;GBK编码,一个中文字符需要2个字节来表示)
注意:Windows的cmd终端字符编码默认为GBK,因此在cmd输入的中文字符需要用两个字节表示
>>> # Python2
>>> a = 'Hello,中国' # 字节串,长度为字节个数 = len('Hello,')+len('中国') = 6+2*2 = 10
>>> b = u'Hello,中国' # 字符串,长度为字符个数 = len('Hello,')+len('中国') = 6+2 = 8
>>> c = unicode(a, 'gbk') # 其实b的定义方式是c定义方式的简写,都是将一个GBK编码的字节串解码(decode)为一个Uniocde字符串
>>>
>>> print(type(a), len(a))
(<type 'str'>, 10)
>>> print(type(b), len(b))
(<type 'unicode'>, 8)
>>> print(type(c), len(c))
(<type 'unicode'>, 8)
>>>
Python3中对字符串的支持做了很大的改动,具体内容会在下面介绍。
2. 编码与解码
先做下科普:UNICODE字符编码,也是一张字符与数字的映射,但是这里的数字被称为代码点(code point), 实际上就是十六进制的数字。
Python官方文档中对Unicode字符串、字节串与编码之间的关系有这样一段描述:
Unicode字符串是一个代码点(code point)序列,代码点取值范围为0到0x10FFFF(对应的十进制为1114111)。这个代码点序列在存储(包括内存和物理磁盘)中需要被表示为一组字节(0到255之间的值),而将Unicode字符串转换为字节序列的规则称为编码。
这里说的编码不是指字符编码,而是指编码的过程以及这个过程中所使用到的Unicode字符的代码点与字节的映射规则。这个映射不必是简单的一对一映射,因此编码过程也不必处理每个可能的Unicode字符,例如:
将Unicode字符串转换为ASCII编码的规则很简单--对于每个代码点:
- 如果代码点数值<128,则每个字节与代码点的值相同
- 如果代码点数值>=128,则Unicode字符串无法在此编码中进行表示(这种情况下,Python会引发一个UnicodeEncodeError异常)
将Unicode字符串转换为UTF-8编码使用以下规则:
- 如果代码点数值<128,则由相应的字节值表示(与Unicode转ASCII字节一样)
- 如果代码点数值>=128,则将其转换为一个2个字节,3个字节或4个字节的序列,该序列中的每个字节都在128到255之间。
简单总结:
- 编码(encode):将Unicode字符串(中的代码点)转换特定字符编码对应的字节串的过程和规则
- 解码(decode):将特定字符编码的字节串转换为对应的Unicode字符串(中的代码点)的过程和规则
可见,无论是编码还是解码,都需要一个重要因素,就是特定的字符编码。因为一个字符用不同的字符编码进行编码后的字节值以及字节个数大部分情况下是不同的,反之亦然。
三、Python中的默认编码
1. Python源代码文件的执行过程
我们都知道,磁盘上的文件都是以二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放的。对于程序源代码文件的字符编码是由编辑器指定的,比如我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘。当执行Python代码文件中的代码时,Python解释器在读取Python代码文件中的字节串之后,需要将其转换为UNICODE字符串(decode过程)之后才执行后续操作。
上面已经解释过,这个转换过程(decode,解码)需要我们指定文件中保存的字节使用的字符编码是什么,才能知道这些字节在UNICODE这张万国码和统一码中找到其对应的代码点是什么。这里指定字符编码的方式大家都很熟悉,如下所示:
# -*- coding:utf-8 -*-
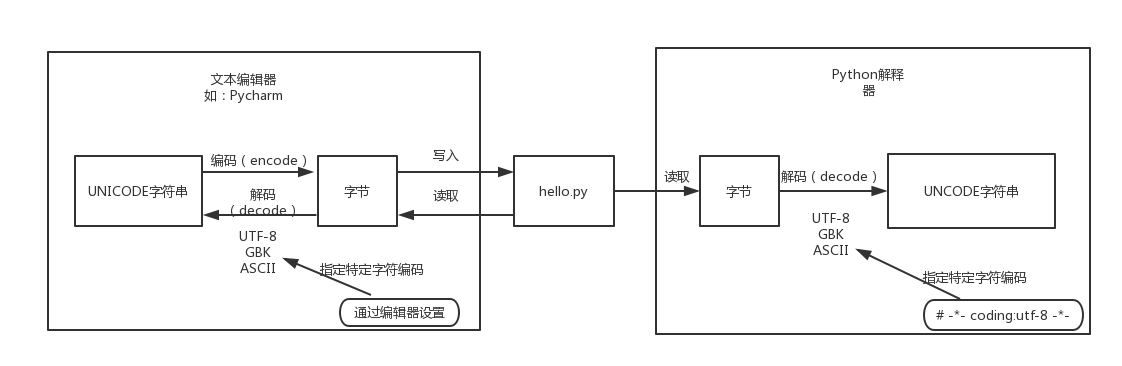
2. 默认编码
那么,如果我们没有在代码文件开始的部分指定字符编码,Python解释器就会使用哪种字符编码把从代码文件中读取到的字节转换为UNICODE代码点呢?就像我们配置某些软件时,有很多默认选项一样,需要在Python解释器内部设置默认的字符编码来解决这个问题,这就是文章开头所说的“默认编码”。因此大家所说的Python中文字符问题就可以总结为一句话:当无法通过默认的字符编码对字节进行转换时,就会出现解码错误(UnicodeEncodeError)。
Python2和Python3的解释器使用的默认编码是不一样的,我们可以通过sys.getdefaultencoding()来获取默认编码:
>>> # Python2
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
>>> # Python3
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
因此,对于Python2来讲,Python解释器在读取到中文字符的字节码尝试解码操作时,会先查看当前代码文件头部是否有指明当前代码文件中保存的字节码对应的字符编码是什么。如果没有指定则使用默认字符编码"ASCII"进行解码导致解码失败,导致如下错误:
SyntaxError: Non-ASCII character '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
对于Python3来讲,执行过程是一样的,只是Python3的解释器以"UTF-8"作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在Windows上进行开发时,Python工程及代码文件都使用的是默认的GBK编码,也就是说Python代码文件是被转换成GBK格式的字节码保存到磁盘中的。Python3的解释器执行该代码文件时,试图用UTF-8进行解码操作时,同样会解码失败,导致如下错误:
SyntaxError: Non-UTF-8 code starting with '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
3. 最佳实践
- 创建一个工程之后先确认该工程的字符编码是否已经设置为UTF-8
- 为了兼容Python2和Python3,在代码头部声明字符编码:
-*- coding:utf-8 -*-
四、Python2与Python3中对字符串的支持
其实Python3中对字符串支持的改进,不仅仅是更改了默认编码,而是重新进行了字符串的实现,而且它已经实现了对UNICODE的内置支持,从这方面来讲Python已经和JAVA一样优秀。下面我们来看下Python2与Python3中对字符串的支持有什么区别:
Python2
Python2中对字符串的支持由以下三个类提供
class basestring(object)
class str(basestring)
class unicode(basestring)
执行help(str)和help(bytes)会发现结果都是str类的定义,这也说明Python2中str就是字节串,而后来的unicode对象对应才是真正的字符串。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
a = '你好'
b = u'你好'
print(type(a), len(a))
print(type(b), len(b))
输出结果:
(<type 'str'>, 6)
(<type 'unicode'>, 2)
Python3
Python3中对字符串的支持进行了实现类层次的上简化,去掉了unicode类,添加了一个bytes类。从表面上来看,可以认为Python3中的str和unicode合二为一了。
class bytes(object)
class str(object)
实际上,Python3中已经意识到之前的错误,开始明确的区分字符串与字节。因此Python3中的str已经是真正的字符串,而字节是用单独的bytes类来表示。也就是说,Python3默认定义的就是字符串,实现了对UNICODE的内置支持,减轻了程序员对字符串处理的负担。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
a = '你好'
b = u'你好'
c = '你好'.encode('gbk')
print(type(a), len(a))
print(type(b), len(b))
print(type(c), len(c))
输出结果:
<class 'str'> 2
<class 'str'> 2
<class 'bytes'> 4
五、字符编码转换
上面提到,UNICODE字符串可以与任意字符编码的字节进行相互转换,如图:
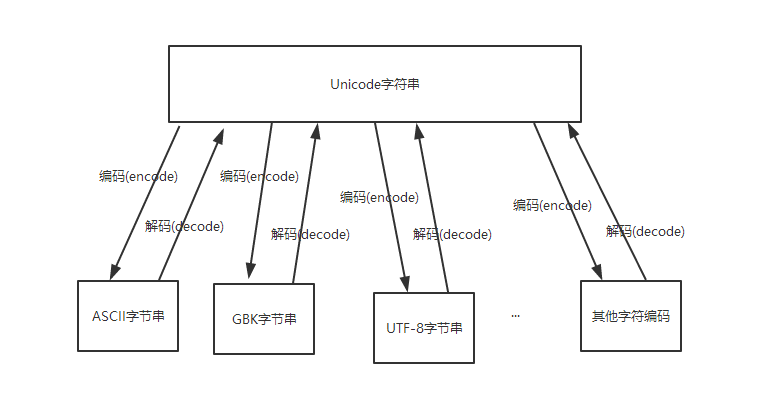
那么大家很容易想到一个问题,就是不同的字符编码的字节可以通过Unicode相互转换吗?答案是肯定的。
Python2中的字符串进行字符编码转换过程是:
字节串-->decode('原来的字符编码')-->Unicode字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
最后需要说明的是,Unicode不是有道词典,也不是google翻译器,它并不能把一个中文翻译成一个英文。正确的字符编码的转换过程只是把同一个字符的字节表现形式改变了,而字符本身的符号是不应该发生变化的,因此并不是所有的字符编码之间的转换都是有意义的。怎么理解这句话呢?比如GBK编码的“中国”转成UTF-8字符编码后,仅仅是由4个字节变成了6个字节来表示,但其字符表现形式还应该是“中国”,而不应该变成“你好”或者“China”。
前面花了很大的篇幅介绍概念和理论,后面注重实践,希望对他人有所帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号