
MySQL table_id原理及风险分析
1. 什么是table_id
MySQL binlog文件按格式分为文件头部和事件信息。文件头部占4字节,内容固定为:"\xfe\x62\x69\x6e",接下来就是各个event了。event有多种类型,比如ROTATE_EVENT对应的记录了binlog切换到下一个binlog文件的信息,XID_EVENT记录了一个事务提交的相关信息。
binlog_format可以设置为statement和row的方式。当设置为statement情况下,DML会记录为原始的SQL,也就是记录在QUERY_EVENT中。而row会记录为TABLE_MAP_EVENT+ROW_LOG_EVENT(包括WRITE_ROWS_EVENT,UPDATE_ROWS_EVENT,DELETE_ROWS_EVENT)。
binlog_format设置为row时,执行一句insert,对应的binlog如下所示:

为什么一个insert在row模式下需要分解成两个event:一个Table_map,一个Write_rows?假如一个insert更新了10000条数据,那么对应的表结构信息是否需要记录10000次列?其实是对同一个表的操作,所以这里binlog只是记录了一个Table_map用于记录表结构相关信息,而后面的Write_rows记录了更新数据的行信息。他们之间是通过table_id来联系的。
table_id用来做hash key,通过set_table(table_id)的方法将某个表的信息hash到cache中;又可以通过get_table()方法来根据table_id获得对应的表信息。
要注意table_id并不是固定的绑定在一个表上,它是表载入table cache时临时分配的,一个不断增长的变量。
2. table_id的增长机制
连续往同一个table中进行多次DML操作,table_id不变。 一般来说,出现DDL操作时,table_id才会变化。
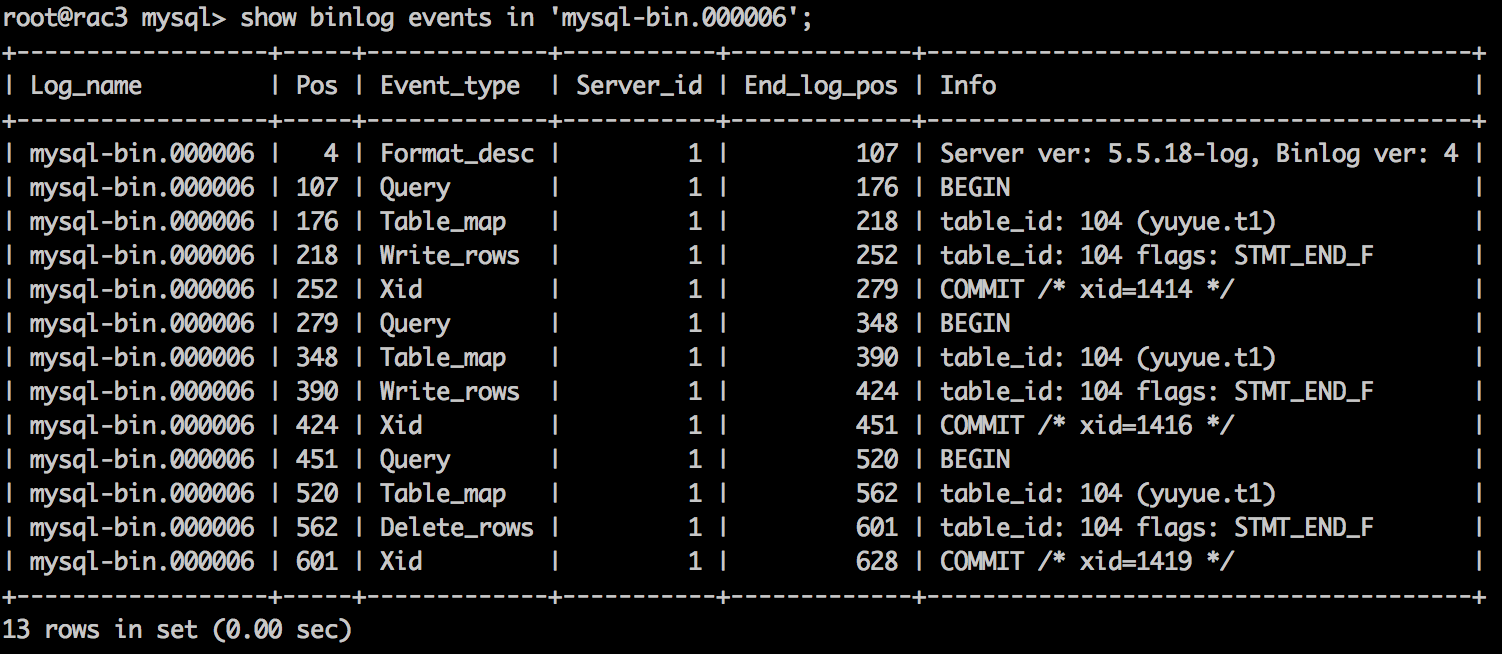
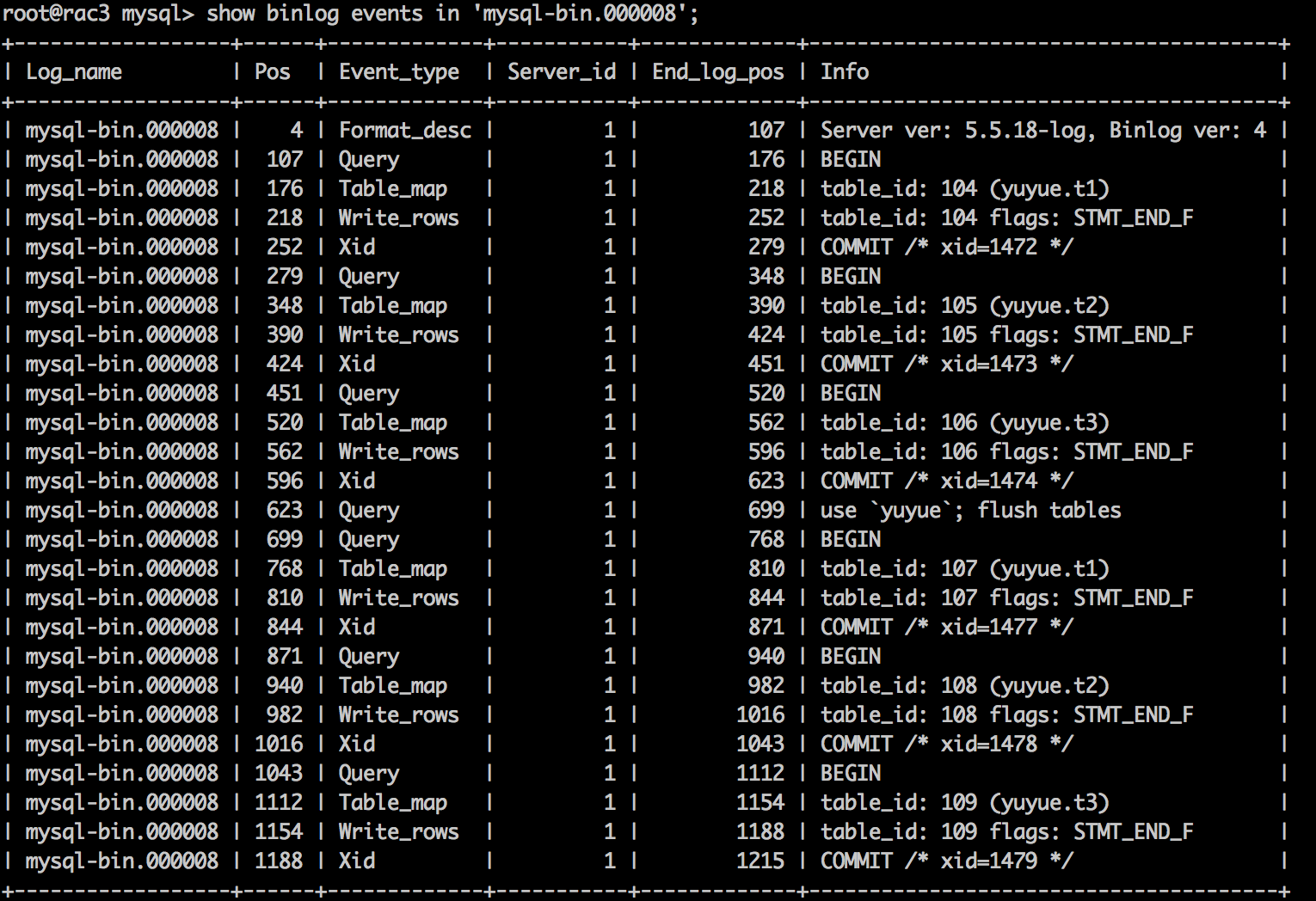
下图中有3个表(t1、t2、t3),执行flush tables,再进行DML操作,每个表的table_id都在增长。
如果表太多,又有频繁的flush tables,会导致table_id增长比较快。
根据MySQL binlog table_id源码分析 ,可以知道:
table id的变化依赖于table cache中是否存储了binlog操作表的表定义。如果table cache中存在,则table id不变;而当table cache中不存在时,该值根据上一次操作的table id自增1。因此,table id与实际操作的数据表没有直接对应关系,而与操作的数据表是否在table cache中有关。此外,table_definition_cache中默认存放400个表定义,如果超出该范围,会将最久未用的表定义置换出table cache。
3. table_id快速增长的风险
binlog中table_id是一个ulong类型(无符号长整形),在slave进行重做binlog events之前,会先将这个ulong的table_id(为了避免混淆,用m_table_id表示)传给一个它内部维护的一个数据结构RPL_TABLE_LIST,这个里面有一个变量table_id用来存储binlog中的m_table_id,问题出现了:数据结构的变量table_id是一个uint(无符号整形),如果m_table_id超过uint的范围会发生截断。而MySQL内部在构造hash,从hash表中取值是这样的做法:set_table(table_id),get_table(m_table_id),在两个阶段用到的key因为发生了数据截断所以必然也就不能取到预期的值。也就是说之前用uint型的table_id构建出来的key-value的hash对,用ulong型的m_table_id是无法查询到的。
具体的源码分析可以参考:淘宝物流MySQL slave数据丢失详细原因

 浙公网安备 33010602011771号
浙公网安备 33010602011771号