
Python自然语言处理学习笔记(45):5.6 基于转换的标记
5.6 Transformation-Based Tagging 基于转换的标记
A potential issue with n-gram taggers is the size of their n-gram table (表的大小问题or language model). If tagging is to be employed in a variety of language technologies deployed on mobile computing devices, it is important to strike a balance(公平处理) between model size and tagger performance. An n-gram tagger with backoff may store trigram and bigram tables, which are large, sparse arrays that may have hundreds of millions of entries.
A second issue concerns context(内容). The only information an n-gram tagger considers from prior context is tags, even though words themselves might be a useful source of information(n-gram标注器仅关心的信息是先前内容的标记,即时单词本身可能是有用的信息资源). It is simply impractical for n-gram models to be conditioned on the identities of words in the context. In this section, we examine Brill tagging, an inductive tagging method which performs very well using models that are only a tiny fraction of the size of n-gram taggers.
Brill tagging is a kind of transformation-based learning, named after(以...命名) its inventor. The general idea is very simple: guess the tag of each word, then go back and fix the mistakes.猜测每个单词的标志,然后返回修复错误
In this way, a Brill tagger successively transforms a bad tagging of a text into a better one. As with n-gram tagging, this is a supervised learning(监督学习) method, since we need annotated training data to figure out whether the tagger’s guess is a mistake or not. However, unlike n-gram tagging, it does not count observations but compiles a list of transformational correction rules(不是统计而是编辑出一个转换修正的规则).
The process of Brill tagging is usually explained by analogy with painting. Suppose we were painting a tree, with all its details of boughs(大树枝), branches, twigs(小枝), and leaves, against a uniform sky-blue background. Instead of painting the tree first and then trying to paint blue in the gaps, it is simpler to paint the whole canvas blue, then “correct” the tree section by over-painting the blue background. In the same fashion, we might paint the trunk(树干) a uniform brown before going back to over-paint further details with even finer(出色的) brushes. Brill tagging uses the same idea: begin with broad brush strokes(画笔, and then fix up the details, with successively finer changes.(先完成整体,然后从细节上一点点地修正) Let’s look at an example involving the following sentence:
(1) The President said he will ask Congress to increase grants to states for vocational rehabilitation(职业康复).
We will examine the operation of two rules: (a) replace NN with VB when the previous word is TO; (b) replace TO with IN when the next tag is NNS. Table 5-6 illustrates this process, first tagging with the unigram tagger, then applying the rules to fix the errors.
Table 5-6. Steps in Brill tagging
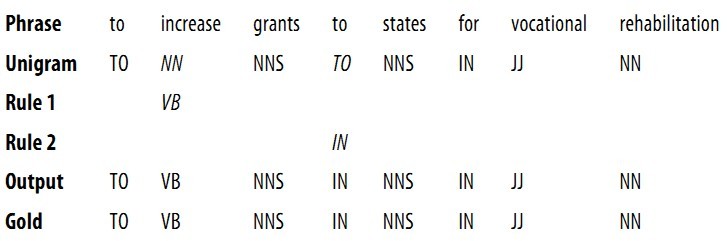
In this table, we see two rules. All such rules are generated from a template of the following form: “replace T1 with T2 in the context C.” Typical contexts are the identity or the tag of the preceding or following word, or the appearance of a specific tag within two to three words of the current word. During its training phase, the tagger guesses values for T1, T2, and C, to create thousands of candidate(候选的) rules. Each rule is scored according to its net benefit(净收益): the number of incorrect tags that it corrects, less(减去) the number of correct tags it incorrectly modifies.
Brill taggers have another interesting property: the rules are linguistically interpretable(规则是可用语言解释的). Compare this with the n-gram taggers, which employ a potentially massive table of n-grams. We cannot learn much from direct inspection of such a table, in comparison to the rules learned by the Brill tagger. Example 5-6 demonstrates NLTK’s Brill tagger.
Example 5-6. Brill tagger demonstration: The tagger has a collection of templates of the form X → Y if the preceding word is Z; the variables in these templates are instantiated to particular words and tags to create “rules”; the score for a rule is the number of broken examples it corrects minus the number of correct cases it breaks; apart from training a tagger, the demonstration displays residual(剩余的) errors.
| ||
| Example 5.10 (code_brill_demo.py): Figure 5.10: Brill Tagger Demonstration: the tagger has a collection of templates of the form X -> Y if the preceding word is Z; the variables in these templates are instantiated to particular words and tags to create "rules"; the score for a rule is the number of broken examples it corrects minus the number of correct cases it breaks; apart from training a tagger, the demonstration displays residual errors. |

