
Python自然语言处理学习笔记(36): 4.8 Python库的样本
4.8 A Sample of Python Libraries Python库的样本
Python has hundreds of third-party libraries, specialized software packages that extend the functionality of Python. NLTK is one such library. To realize the full power of Python programming, you should become familiar with several other libraries. Most of these will need to be manually installed on your computer.
Matplotlib 绘图工具
Python has some libraries that are useful for visualizing language data. The Matplotlib package supports sophisticated plotting functions with a MATLAB-style interface, and is available from http://matplotlib.sourceforge.net/ .
So far we have focused on textual presentation and the use of formatted print statements to get output lined up in columns. It is often very useful to display numerical data in graphical form, since this often makes it easier to detect patterns. For example, in Example 3.7 we saw a table of numbers showing the frequency of particular modal verbs in the Brown Corpus, classified by genre. The program in Example 4.13 presents the same information in graphical format. The output is shown in Figure 4.14 (a color figure in the graphical display).
| ||
| ||
| Example 4.13 (code_modal_plot.py): Figure 4.13: Frequency of Modals in Different Sections of the Brown Corpus |
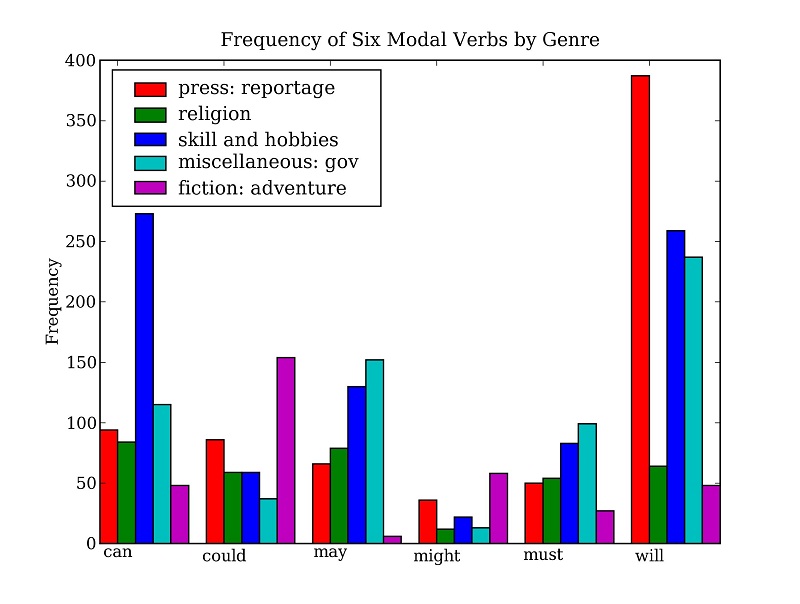
Figure 4.14: Bar Chart(柱状图) Showing Frequency of Modals in Different Sections of Brown Corpus
From the bar chart it is immediately obvious that may and must have almost identical relative frequencies. The same goes for could and might.
It is also possible to generate such data visualizations on the fly. For example, a web page with form input could permit visitors to specify search parameters, submit the form, and see a dynamically generated visualization. To do this we have to specify the Agg backend for matplotlib, which is a library for producing raster (pixel) images . Next, we use all the same PyLab methods as before, but instead of displaying the result on a graphical terminal using pylab.show(), we save it to a file using pylab.savefig() . We specify the filename and dpi, then print HTML markup that directs the web browser to load the file.
|
NetworkX
The NetworkX package is for defining and manipulating structures consisting of nodes and edges, known as graphs. It is available from https://networkx.lanl.gov/ . NetworkX can be used in conjunction with Matplotlib to visualize networks, such as WordNet (the semantic network(语义网络) we introduced in Section 2.5). The program in Example 4.15 initializes an empty graph then traverses the WordNet hypernym hierarchy adding edges to the graph . Notice that the traversal is recursive , applying the programming technique discussed in Section 4.7. The resulting display is shown in Figure 4.16.
| ||
| ||
| Example 4.15 (code_networkx.py): Figure 4.15: Using the NetworkX and Matplotlib Libraries |
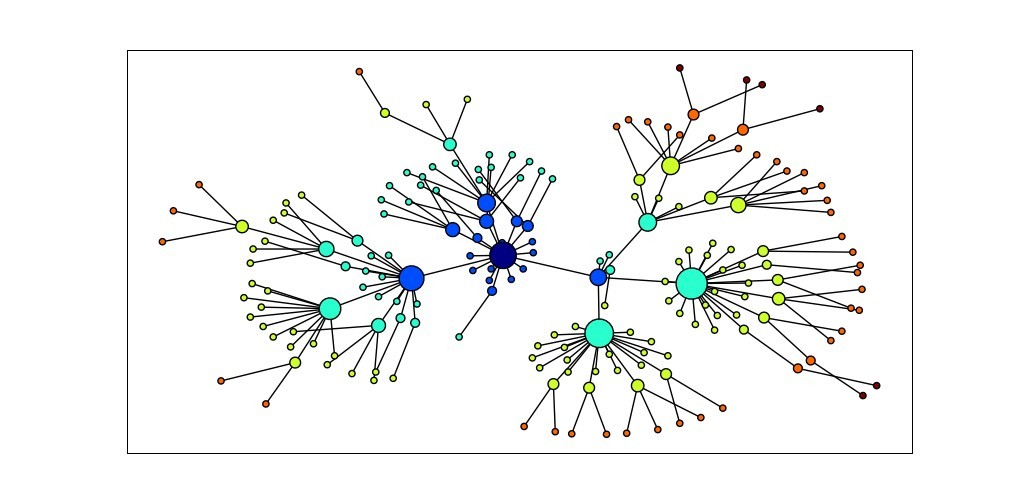
Figure 4.16: Visualization with NetworkX and Matplotlib: Part of the WordNet hypernym hierarchy is displayed, starting with dog.n.01 (the darkest node in the middle); node size is based on the number of children of the node, and color is based on the distance of the node from dog.n.01; this visualization was produced by the program in Example 4.15.
csv 逗号分隔值格式
Language analysis work often involves data tabulations, containing information about lexical items, or the participants in an empirical study, or the linguistic features extracted from a corpus. Here's a fragment of a simple lexicon, in CSV format:
sleep, sli:p, v.i, a condition of body and mind ...
walk, wo:k, v.intr, progress by lifting and setting down each foot ...
wake, weik, intrans, cease to sleep
We can use Python's CSV library to read and write files stored in this format. For example, we can open a CSV file called lexicon.csv and iterate over its rows :
|
Each row is just a list of strings. If any fields contain numerical data, they will appear as strings, and will have to be converted using int() or float().
NumPy 基本的数值运算包,高级的有SciPy
The NumPy package provides substantial support for numerical processing in Python. NumPy has a multi-dimensional array object, which is easy to initialize and access:
|
NumPy includes linear algebra functions. Here we perform singular value decomposition(奇异值分解) on a matrix, an operation used in latent semantic analysis(潜在语义分析) to help identify implicit concepts in a document collection.
|
NLTK's clustering package(聚类包) nltk.cluster makes extensive use of NumPy arrays, and includes support for k-means clustering, Gaussian EM clustering, group average agglomerative clustering, and dendrogram plots. For details, type help(nltk.cluster).
Other Python Libraries 其他的Python库
There are many other Python libraries, and you can search for them with the help of the Python Package Index http://pypi.python.org/ . Many libraries provide an interface to external software, such as relational databases (e.g. mysql-python) and large document collections (e.g. PyLucene). Many other libraries give access to file formats such as PDF, MSWord, and XML (pypdf, pywin32, xml.etree), RSS feeds (e.g. feedparser), and electronic mail (e.g. imaplib, email).

