
Python自然语言处理学习笔记(24):3.8 分割
3.8 Segmentation 分割
This section discusses more advanced concepts, which you may prefer to skip on the first time through this chapter. Tokenization is an instance of a more general problem of segmentation. In this section, we will look at two other instances of this problem, which use radically(根本上)different techniques to the ones we have seen so far in this chapter.
Sentence Segmentation 断句
Manipulating texts at the level of individual words often presupposes(假定) the ability to divide a text into individual sentences. As we have seen, some corpora already provide access at the sentence level. In the following example, we compute the average number of words per sentence in the Brown Corpus:
20.250994070456922
In other cases, the text is available only as a stream of characters. Before tokenizing the text into words, we need to segment it into sentences. NLTK facilitates this by including the Punkt sentence segmenter (Kiss & Strunk, 2006). Here is an example of its use in segmenting the text of a novel. (Note that if the segmenter’s internal data has been updated by the time you read this, you will see different output.)
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents = sent_tokenizer.tokenize(text)
>>> pprint.pprint(sents[171:181])
['"Nonsense!',
'" said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\nrailway trains look so sad and tired,...',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\nis because they know that whatever place they have taken a ticket\nfor that ...',
'It is because after they have\npassed Sloane Square they know that the next stat...',
'Oh, their wild rapture!',
'oh,\ntheir eyes like stars and their souls again in Eden, if the next\nstation w...'
'"\n\n"It is you who are unpoetical," replied the poet Syme.']
Notice that this example is really a single sentence, reporting the speech of Mr. Lucian Gregory. However, the quoted speech contains several sentences, and these have been split into individual strings. This is reasonable behavior for most applications.
Sentence segmentation is difficult because a period is used to mark abbreviations, and some periods simultaneously(同时)mark an abbreviation and terminate a sentence, as often happens with acronyms like U.S.A. For another approach to sentence segmentation, see Section 6.2.
Word Segmentation 断词
For some writing systems, tokenizing text is made more difficult by the fact that there is no visual representation of word boundaries. For example, in Chinese, the three-character string: 爱国人 (ai4 “love” [verb], guo3 “country”, ren2 “person”) could be tokenized as 爱国 / 人, “country-loving person,” or as 爱 / 国人, “love country-person.”
A similar problem arises in the processing of spoken language, where the hearer must segment a continuous speech stream into individual words. A particularly challenging version of this problem arises when we don’t know the words in advance. This is the problem faced by a language learner, such as a child hearing utterances(说话) from a parent.
Consider the following artificial example, where word boundaries have been removed:
(1) a. doyouseethekitty
b. seethedoggy
c. doyoulikethekitty
d. likethedoggy
Our first challenge is simply to represent the problem: we need to find a way to separate text content from the segmentation. We can do this by annotating each character with a boolean value to indicate whether or not a word-break appears after the character (an idea that will be used heavily for “chunking” in Chapter 7). Let’s assume that the learner is given the utterance breaks, since these often correspond to extended pauses. Here is a possible representation, including the initial and target segmentations:
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
Observe that the segmentation strings consist of zeros and ones. They are one character shorter than the source text, since a text of length n can be broken up in only n–1 places. The segment() function in Example 3-2 demonstrates that we can get back to the original segmented text from its representation.
Example 3-2. Reconstruct segmented text from string representation: seg1 and seg2 represent the initial and final segmentations of some hypothetical(假设)child-directed speech; the segment() function can use them to reproduce the segmented text.
words = []
last = 0
for i in range(len(segs)):
if segs[i] == '1':
words.append(text[last:i+1])
last = i+1
words.append(text[last:])
return words
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
>>> segment(text, seg1)
['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
>>> segment(text, seg2)
['do', 'you', 'see', 'the', 'kitty', 'see', 'the', 'doggy', 'do', 'you',
'like', 'the', kitty', 'like', 'the', 'doggy']
Now the segmentation task becomes a search problem: find the bit string that causes the text string to be correctly segmented into words. We assume the learner is acquiring words and storing them in an internal lexicon. Given a suitable lexicon, it is possible to reconstruct the source text as a sequence of lexical items. Following (Brent & Cart-wright, 1995), we can define an objective function(目标函数), a scoring function whose value we will try to optimize, based on the size of the lexicon and the amount of information needed to reconstruct the source text from the lexicon. We illustrate this in Figure 3-6.
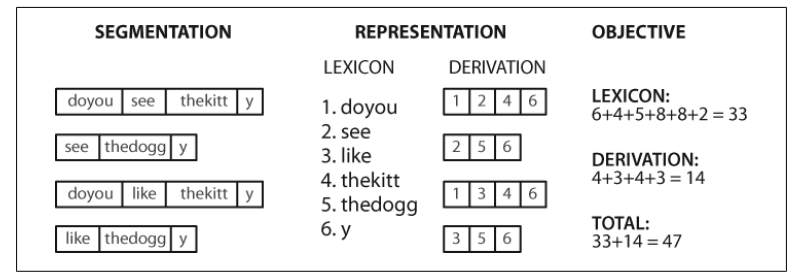
Figure 3-6. Calculation of objective function: Given a hypothetical segmentation of the source text (on the left), derive a lexicon and a derivation table(推导表) that permit the source text to be reconstructed, then total up(合计) the number of characters used by each lexical item (including a boundary marker 界标) and each derivation, to serve as a score of the quality of the segmentation; smaller values of the score indicate a better segmentation(得分值与分割性能成反比).(词汇的分数是按长度+界标,推导是由分割的数量)
It is a simple matter to implement this objective function, as shown in Example 3-3.
Example 3-3. Computing the cost of storing the lexicon and reconstructing the source text.
words = segment(text, segs)
text_size = len(words)
lexicon_size = len(' '.join(list(set(words))))
return text_size + lexicon_size
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
>>> seg3 = "0000100100000011001000000110000100010000001100010000001"
>>> segment(text, seg3)
['doyou', 'see', 'thekitt', 'y', 'see', 'thedogg', 'y', 'doyou', 'like',
'thekitt', 'y', 'like', 'thedogg', 'y']
>>> evaluate(text, seg3)
46
>>> evaluate(text, seg2)
47
>>> evaluate(text, seg1)
63
The final step is to search for the pattern of zeros and ones that maximizes this objective function, shown in Example 3-4. Notice that the best segmentation includes “words” like thekitty, since there’s not enough evidence in the data to split this any further.
Example 3-4. Non-deterministic search using simulated annealing(模拟退火算法): Begin searching with phrase segmentations only; randomly perturb(扰乱) the zeros and ones proportional to the “temperature”; with each iteration the temperature is lowered and the perturbation(扰乱) of boundaries is reduced.
刚开始仅搜索短语分词;随机地扰乱0和1,与“temperature”成比例;每次迭代温度降低并且边界的扰乱减少了。
def flip(segs, pos):
return segs[:pos] + str(1-int(segs[pos])) + segs[pos+1:]
def flip_n(segs, n):
for i in range(n):
segs = flip(segs, randint(0,len(segs)-1))
return segs
def anneal(text, segs, iterations, cooling_rate):
temperature = float(len(segs))
while temperature > 0.5:
best_segs, best = segs, evaluate(text, segs)
for i in range(iterations):
guess = flip_n(segs, int(round(temperature)))
score = evaluate(text, guess)
if score < best:
best, best_segs = score, guess
score, segs = best, best_segs
temperature = temperature / cooling_rate
print evaluate(text, segs), segment(text, segs)
return segs
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> anneal(text, seg1, 5000, 1.2)
60 ['doyouseetheki', 'tty', 'see', 'thedoggy', 'doyouliketh', 'ekittylike', 'thedoggy']
58 ['doy', 'ouseetheki', 'ttysee', 'thedoggy', 'doy', 'o', 'ulikethekittylike', 'thedoggy']
56 ['doyou', 'seetheki', 'ttysee', 'thedoggy', 'doyou', 'liketh', 'ekittylike', 'thedoggy']
54 ['doyou', 'seethekit', 'tysee', 'thedoggy', 'doyou', 'likethekittylike', 'thedoggy']
53 ['doyou', 'seethekit', 'tysee', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
51 ['doyou', 'seethekittysee', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
42 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
'0000100100000001001000000010000100010000000100010000000'
With enough data, it is possible to automatically segment text into words with a reasonable degree of accuracy. Such methods can be applied to tokenization for writing systems that don’t have any visual representation of word boundaries.

