
Python自然语言处理学习笔记(19):3.3 使用Unicode进行文字处理
3.3 Text Processing with Unicode 使用Unicode进行文字处理
Our programs will often need to deal with different languages, and different character sets. The concept of “plain text” is a fiction(虚构). If you live in the English-speaking world you probably use ASCII, possibly without realizing it. If you live in Europe you might use one of the extended Latin character sets, containing such characters as “ø” for Danish(丹麦语) and Norwegian(挪威语), “ő” for Hungarian(匈牙利语), “ñ” for Spanish and Breton(法国的布列塔尼语), and “ň” for Czech(捷克语) and Slovak(斯洛伐克语). In this section, we will give an overview of how to use Unicode for processing texts that use non-ASCII character sets.
What Is Unicode? 神马是Unicode?
Unicode supports over a million characters. Each character is assigned a number, called a code point(编码点). In Python, code points are written in the form \uXXXX, where XXXX is the number in four-digit hexadecimal form(十六进制).
Within a program, we can manipulate Unicode strings just like normal strings. However, when Unicode characters are stored in files or displayed on a terminal, they must be encoded as a stream of bytes. Some encodings (such as ASCII and Latin-2) use a single byte per code point, so they can support only a small subset of Unicode, enough for a single language. Other encodings (such as UTF-8) use multiple bytes and can represent the full range of Unicode characters.
Text in files will be in a particular encoding, so we need some mechanism for translating it into Unicode—translation into Unicode is called decoding(解码). Conversely, to write out Unicode to a file or a terminal, we first need to translate it into a suitable encoding— this translation out of Unicode is called encoding(编码), and is illustrated in Figure 3-3.
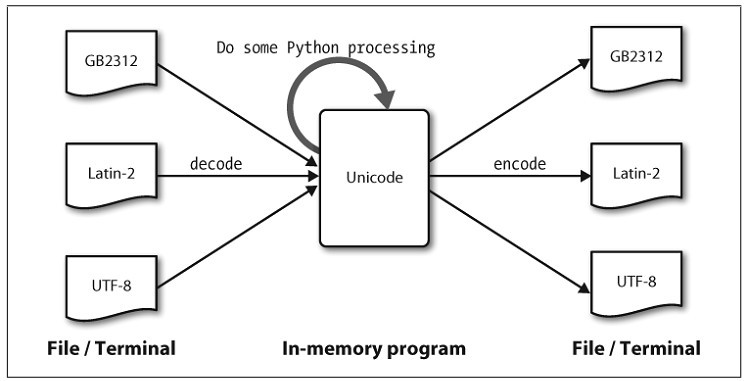
Figure 3-3. Unicode decoding and encoding
From a Unicode perspective, characters are abstract entities that can be realized as one or more glyphs(图像字符). Only glyphs can appear on a screen or be printed on paper. A font(字体) is a mapping from characters to glyphs.
Extracting Encoded Text from Files 从文件提取编码文本
Let’s assume that we have a small text file, and that we know how it is encoded. For example, polish-lat2.txt, as the name suggests, is a snippet(片段) of Polish text (from the Polish Wikipedia; see http://pl.wikipedia.org/wiki/Biblioteka_Pruska ). This file is encoded as Latin-2, also known as ISO-8859-2. The function nltk.data.find() locates the file for us.
>>> path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
The Python codecs(编码解码器) module provides functions to read encoded data into Unicode strings, and to write out Unicode strings in encoded form. The codecs.open() function takes an encoding parameter to specify the encoding of the file being read or written. So let’s import the codecs module, and call it with the encoding 'latin2' to open our Polish file as Unicode:
>>> f = codecs.open(path, encoding='latin2')
For a list of encoding parameters allowed by codecs, see http://docs.python.org/lib/standard-encodings.html . Note that we can write Unicode-encoded data to a file using f = codecs.open(path, 'w', encoding='utf-8'). Text read from the file object f will be returned in Unicode. As we pointed out earlier, in order to view this text on a terminal, we need to encode it, using a suitable encoding.
The Python-specific encoding unicode_escape is a dummy(傻瓜) encoding that converts all non-ASCII characters into their \uXXXX representations. Code points above the ASCII 0–127 range but below 256 are represented in the two-digit form \xXX.
... line = line.strip()
... print line.encode('unicode_escape')
Pruska Biblioteka Pa\u0144stwowa. Jej dawne zbiory znane pod nazw\u0105
"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez
Niemc\xf3w pod koniec II wojny \u015bwiatowej na Dolny \u015al\u0105sk, zosta\u0142y
odnalezione po 1945 r. na terytorium Polski. Trafi\u0142y do Biblioteki
Jagiello\u0144skiej w Krakowie, obejmuj\u0105 ponad 500 tys. zabytkowych
archiwali\xf3w, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.
The first line in this output illustrates a Unicode escape string preceded by the \u escape string, namely \u0144. The relevant Unicode character will be displayed on the screen as the glyph ń. In the third line of the preceding example, we see \xf3, which corresponds to the glyph ó, and is within the 128–255 range.
In Python, a Unicode string literal can be specified by preceding an ordinary string literal with a u, as in u'hello'. Arbitrary Unicode characters are defined using the \uXXXX escape sequence(转义序列) inside a Unicode string literal. We find the integer ordinal(序数) of a character using ord(). For example:
97
The hexadecimal four-digit notation for 97 is 0061, so we can define a Unicode string literal with the appropriate escape sequence:
>>> a
u'a'
>>> print a
a
Notice that the Python print statement is assuming a default encoding of the Unicode character, namely ASCII. However, ń is outside the ASCII range, so cannot be printed unless we specify an encoding. In the following example, we have specified that print should use the repr() of the string, which outputs the UTF-8 escape sequences (of the form \xXX) rather than trying to render(显示) the glyphs.
>>> nacute
u'\u0144'
>>> nacute_utf = nacute.encode('utf8')
>>> print repr(nacute_utf)
'\xc5\x84'
If your operating system and locale are set up to render UTF-8 encoded characters, you ought to be able to give the Python command print nacute_utf and see ń on your screen.
 Window的命令行不支持UTF-8的,使用print nacute_utf.decode('utf-8')可以显示
Window的命令行不支持UTF-8的,使用print nacute_utf.decode('utf-8')可以显示
There are many factors determining what glyphs are rendered on your screen. If you are sure that you have the correct encoding, but your Python code is still failing to produce the glyphs you expected, you should also check that you have the necessary fonts installed on your system.
The module unicodedata lets us inspect the properties of Unicode characters. In the following example, we select all characters in the third line of our Polish text outside the ASCII range and print their UTF-8 escaped value, followed by their code point integer using the standard Unicode convention (i.e., prefixing the hex digits with U+), followed by their Unicode name.
>>> import unicodedata
>>> lines = codecs.open(path, encoding='latin2').readlines()
>>> line = lines[2]
>>> print line.encode('unicode_escape')
Niemc\xf3w pod koniec II wojny \u015bwiatowej na Dolny \u015al\u0105sk, zosta\u0142y\n
>>> for c in line:
... if ord(c) > 127:
... print '%r U+%04x %s' % (c.encode('utf8'), ord(c), unicodedata.name(c))
'\xc3\xb3' U+00f3 LATIN SMALL LETTER O WITH ACUTE
'\xc5\x9b' U+015b LATIN SMALL LETTER S WITH ACUTE
'\xc5\x9a' U+015a LATIN CAPITAL LETTER S WITH ACUTE
'\xc4\x85' U+0105 LATIN SMALL LETTER A WITH OGONEK
'\xc5\x82' U+0142 LATIN SMALL LETTER L WITH STROKE
If you replace the %r (which yields the repr() value) by %s in the format string of the preceding code sample, and if your system supports UTF-8, you should see an output like the following:
ó U+00f3 LATIN SMALL LETTER O WITH ACUTE
ś U+015b LATIN SMALL LETTER S WITH ACUTE
Ś U+015a LATIN CAPITAL LETTER S WITH ACUTE
ą U+0105 LATIN SMALL LETTER A WITH OGONEK
ł U+0142 LATIN SMALL LETTER L WITH STROKE
Alternatively, you may need to replace the encoding 'utf8' in the example by 'latin2', again depending on the details of your system.
The next examples illustrate how Python string methods and the re module accept Unicode strings.
>>> line.find(u'zosta\u0142y')
54
>>> line = line.lower()
>>> print line.encode('unicode_escape')
niemc\xf3w pod koniec ii wojny \u015bwiatowej na dolny \u015bl\u0105sk, zosta\u0142y\n
>>> import re
>>> m = re.search(u'\u015b\w*', line)
>>> m.group()
u '\u015bwiatowej'
NLTK tokenizers allow Unicode strings as input, and correspondingly yield Unicode strings as output.
[u'niemc\xf3w', u'pod', u'koniec', u'ii', u'wojny', u'\u015bwiatowej',
u'na', u'dolny', u'\u015bl\u0105sk', u'zosta\u0142y']
Using Your Local Encoding in Python 在Python使用你的本地编码
If you are used to working with characters in a particular local encoding, you probably want to be able to use your standard methods for inputting and editing strings in a Python file. In order to do this, you need to include the string '# -*- coding: <coding> -*-' as the first or second line of your file. Note that <coding> has to be a string like 'latin-1', 'big5', or 'utf-8' (see Figure 3-4). Figure 3-4 also illustrates how regular expressions can use encoded strings.

