
Python自然语言处理学习笔记(16):2.8 Exercises 练习
博主懒人...练习未做完,下回补全...
2.8 Exercises 练习
1. ○ Create a variable phrase containing a list of words. Experiment with the operations described in this chapter, including addition, multiplication, indexing, slicing, and sorting.
List_practice+['Pythoner']
List_practice*3
List_practice.index(‘Hello’)
List_practice[:]
List_practice.sort()
2. ○ Use the corpus module to explore austen-persuasion.txt. How many word tokens does this book have? How many word types?
austen =gutenberg.words('austen-persuasion.txt')
len(austen)=98171
不太明白这里的单词种类是指单词有多少种还是单词类型有多少?
len(set((s.lower() for s in austen if s.isalpha())))
5739
3. ○ Use the Brown Corpus reader nltk.corpus.brown.words() or the Web Text Corpus reader nltk.corpus.webtext.words() to access some sample text in two different genres.
romance_text=brown.words(categories='romance')
print ' '.join(romance_text[:50])
from nltk.corpus import webtext
firefox_text=webtext.words('firefox.txt')
print ' '.join(firefox_text[:50])
4. ○ Read in the texts of the State of the Union addresses, using the state_union corpus reader. Count occurrences of men, women, and people in each document. What has happened to the usage of these words over time?
from nltk.corpus import inaugural
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['men', 'women', 'people']
if w.lower().startswith(target))
cfd.plot()
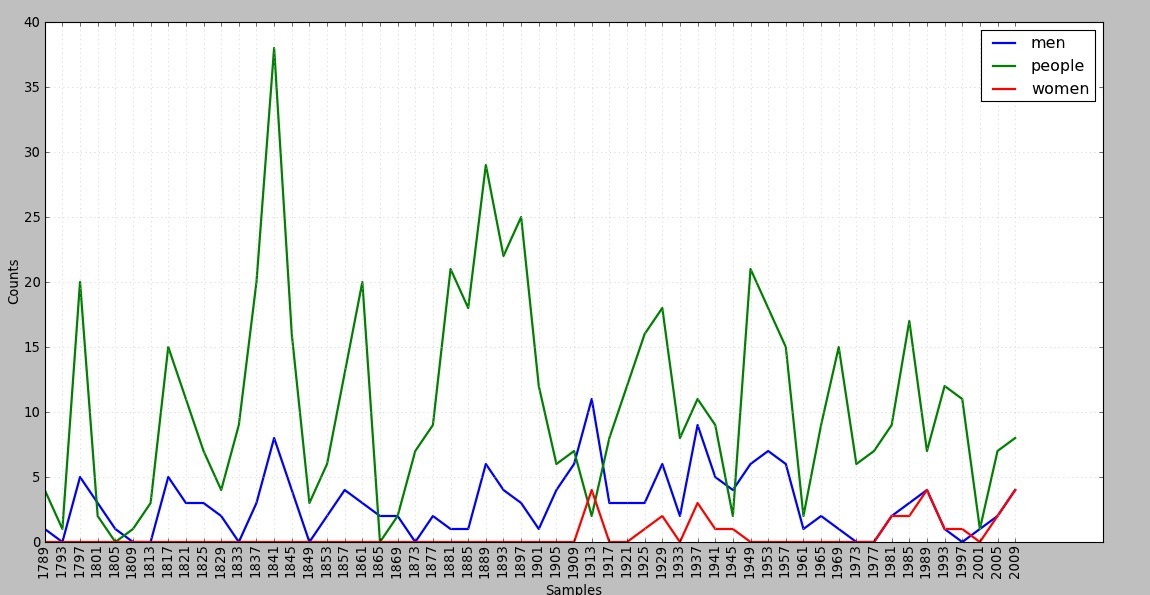
men:内战和二次大战的时候出现的比较多,参军保卫国家呗,冷战之后频率下降
women:1909年之前为0!之后开始出现,1913年最多,从1949年到1977年又为0,估计那会都去搞苏联,冷战,建立北约什么去了。1981年之后又开始出现,看来米国的性别歧视相当严重。
people:只要是打仗的时候出现的非常频率...人民啊人民,仅挂在嘴上的这群政客!跑题了...
7/16更新 发现审题审错了...应该是State of the Union addresses(国情咨文),不是就职演讲...重做!
from nltk.corpus import state_union
cfd = nltk.ConditionalFreqDist(
(target,fileid[:4])
for fileid in state_union.fileids()
for w in state_union.words(fileid)
for target in ['men', 'women', 'people']
if w.lower().startswith(target))
cfd.plot()
5. ○ Investigate the holonym-meronym relations for some nouns. Remember that there are three kinds of holonym-meronym(整体部分) relation, so you need to use member_meronyms(),part_meronyms(),substance_meronyms(), member_holonyms(),
part_holonyms(), and substance_holonyms().
N=wn.synset('human.n.01')
>>> N
Synset('homo.n.02')
>>> N. member_meronyms()
[]
>>> N.part_meronyms()
[Synset('human_head.n.01'), Synset('foot.n.01'), Synset('mane.n.02'), Synset('loin.n.02'), Synset('face.n.01'), Synset('arm.n.01'), Synset('hand.n.01'), Synset('human_body.n.01'), Synset('body_hair.n.01')]
>>> N.substance_meronyms()
[]
>>> N.member_holonyms()
[Synset('genus_homo.n.01')]
>>> N.part_holonyms()
[]
>>> N.substance_holonyms()
[]
>>> F=wn.synset('fish.n.01')
>>> F
Synset('fish.n.01')
>>> F.member_meronyms()
[]
>>> F.part_meronyms()
[Synset('tail_fin.n.03'), Synset('milt.n.02'), Synset('fin.n.06'), Synset('fishbone.n.01'), Synset('roe.n.02'), Synset('fish_scale.n.01'), Synset('lateral_line.n.01')]
>>> F.substance_meronyms()
[]
>>> F.member_holonyms()
[Synset('school.n.07'), Synset('pisces.n.04')]
>>> F.substance_holonyms()
[]
>>> F.part_holonyms()
[]
6. ○ In the discussion of comparative wordlists, we created an object called translate, which you could look up using words in both German and Italian in order to get corresponding words in English. What problem might arise with this approach? Can you suggest a way to avoid this problem?
如果输入错误、不存在的词语或者其他没有通过translate.update(dict(XX2en))加入字典的语言词语,则会引发KeyError。添加一个错误处理或者用if判断
7. ○ According to Strunk and White’s Elements of Style, the word however, used at the start of a sentence, means “in whatever way” or “to whatever extent,” and not “nevertheless.” They give this example of correct usage: However you advise him, he will probably do as he thinks best. (http://www.bartleby.com/141/strunk3.html) Use the concordance tool to study actual usage of this word in the various texts we have been considering. See also the LanguageLog posting “Fossilized prejudices about ‘however’” at http://itre.cis.upenn.edu/~myl/languagelog/archives/001913.html.
emma.concordance("However")

