
Python自然语言处理学习笔记(8):1.6-1.8 小结&深入阅读&练习
Updated log

1.6 Summary 小结
• Texts are represented in Python using lists: ['Monty', 'Python']. We can use indexing, slicing,and the len() function on lists.
在Python中文本用列表来表示:['Monty', 'Python']。我们可以使用indexing, slicing, 和len()函数对列表操作。
• A word “token” is a particular appearance of a given word in a text; a word “type”is the unique form of the word as a particular sequence of letters. We count word tokens using len(text) and word types using len(set(text)).
单词的“token”是指在文本中给定单词的特定出现;单词的“type”则是指单词作为特定序列字母的唯一形式。我们使用len(text)和len(set(text))对单词的token和单词的types
• We obtain the vocabulary of a text t using sorted(set(t)).
我们使用sorted(set(t))来获得文本t的词汇表。
• We operate on each item of a text using [f(x) for x in text].
我们使用[f(x) for x in text]对文本的每一条目操作
• To derive the vocabulary, collapsing(折叠,意译为压缩) case distinctions and ignoring punctuation, we can write set([w.lower() for w in text if w.isalpha()]).
为了导出词汇表,压缩大小写区分和忽略标点符号,我们可以使用set([w.lower() for w in text if w.isalpha()])
• We process each word in a text using a for statement, such as for w in t: or for word in text:. This must be followed by the colon character and an indented block of code, to be executed each time through the loop.
我们使用for语句对文本中的每个单词进行处理,例如for win t:或者for word in text:。后面必须紧跟冒号和一块缩进的代码,在循环中每次都被执行。
• We test a condition using an if statement: if len(word) < 5:. This must be followed by the colon character and an indented block of code, to be executed only if the condition is true.
我们测试一个条件使用if语句:if len(word)<5:。后面必须紧跟冒号和一块缩进的代码,仅当条件为真时执行。
• A frequency distribution is a collection of items along with their frequency counts (e.g., the words of a text and their frequency of appearance).
频率分布是单词的频率计数的采集(例如,一个文本中的单词以及它们出现的频率)
• A function is a block of code that has been assigned a name and can be reused. Functions are defined using the def keyword, as in def mult(x, y); x and y are parameters of the function, and act as placeholders for actual data values.
函数是一个已经指定名字并且可以重用的代码块。函数通过def关键字定义,例如在def mult(x, y)中;x和y是函数的参数,变现为实际数据值的占位符。
• A function is called by specifying its name followed by one or more arguments inside parentheses, like this: mult(3, 4), e.g., len(text1).
函数是通过说明它的名字和一个或更多个在形参里的实参来调用,就像这样:mult(3, 4),len(text1).
1.7 Further Reading 深入阅读
This chapter has introduced new concepts in programming, natural language processing, and linguistics, all mixed in together. Many of them are consolidated in the following chapters. However, you may also want to consult the online materials provided with this chapter (at http://www.nltk.org/), including links to additional background materials, and links to online NLP systems. You may also like to read up on some linguistics and NLP-related concepts in Wikipedia (e.g., collocations, the Turing Test, the type-token distinction).
You should acquaint(熟悉) yourself with the Python documentation available at http://docs.python.org/, including the many tutorials and comprehensive reference materials linked there.
A Beginner’s Guide to Python is available at http://wiki.python.org/moin/BeginnersGuide.
Miscellaneous(各种各样的)questions about Python might be answered in the FAQ at http://www.python.org/doc/faq/general/.
As you delve into NLTK, you might want to subscribe(订阅) to the mailing list where new releases of the toolkit are announced. There is also an NLTK-Users mailing list, where users help each other as they learn how to use Python and NLTK for language analysis work. Details of these lists are available at http://www.nltk.org/. For more information on the topics covered in Section 1.5, and on NLP more generally, you might like to consult one of the following excellent books:
Indurkhya, Nitin and Fred Damerau (eds., 2010) Handbook of Natural Language Processing (second edition), Chapman & Hall/CRC.
Jurafsky, Daniel and James Martin (2008) Speech and Language Processing (second edition), Prentice Hall.
Mitkov, Ruslan (ed.,2002) The
The Association for Computational Linguistics is the international organization that represents the field of NLP. The ACL website hosts many useful resources, including: information about international and regional conferences and workshops; the ACL Wiki with links to hundreds of useful resources; and the ACL Anthology(选集), which contains most of the NLP research literature from the past 50 years, fully indexed and freely downloadable.
Some excellent introductory linguistics textbooks are: (Finegan, 2007), (O’Grady et al., 2004), (OSU, 2007). You might like to consult LanguageLog, a popular linguistics blog with occasional posts that use the techniques described in this book.
1.8 Exercises 练习
1. ○ Try using the Python interpreter as a calculator, and typing expressions like 12 /(4 + 1).
/在Python中是整除
2. ○ Given an alphabet of 26 letters, there are 26 to the power 10, or 26 ** 10, 10-letter strings we can form. That works out to 141167095653376L (the L at the end just indicates that this is Python’s long-number format). How many hundred-letter strings are possible?
26**100
3. ○ The Python multiplication operation can be applied to lists. What happens when you type ['Monty', 'Python'] * 20, or 3 * sent1?
*N,则复制N个列表
4. ○ Review Section 1.1 on computing with language. How many words are there in text2? How many distinct words are there?
len(text2) =141576 len(set(text2))= 6833
5. ○ Compare the lexical diversity scores for humor and romance fiction in Table 1-1. Which genre is more lexically diverse?
romance fiction
6. ○ Produce a dispersion plot of the four main protagonists(主角) in Sense and Sensibility: Elinor, Marianne, Edward, and Willoughby. What can you observe about the different roles played by the males and females in this novel? Can you identify the couples?
text2.dispersion_plot(["Elinor", "Marianne", "Edward", "Willoughby"])
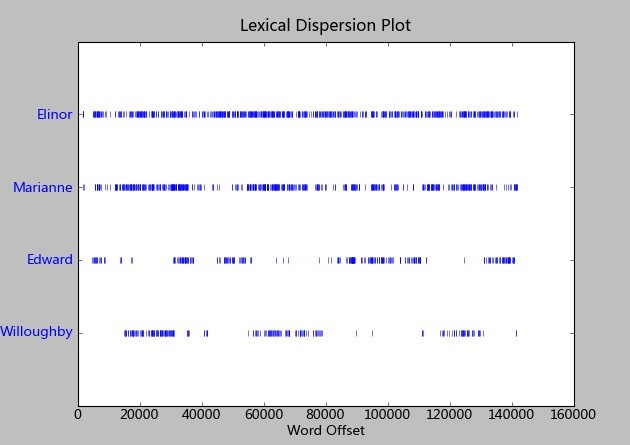
Elinor和Marianne是女一和女二号,Edward和Willoughby应该就属于男一,男二。其中E对E,M对W一共两对,推测这是部小说应该是主要讲两个女主人公的。
7. ○ Find the collocations in text5.
text5.collocations()
8. ○ Consider the following Python expression: len(set(text4)). State the purpose of this expression. Describe the two steps involved in performing this computation.
set(text4) 未排序的收集唯一元素
len(set(text4)) 计算单词量
9. ○ Review Section 1.2 on lists and strings.
a. Define a string and assign it to a variable, e.g., my_string = 'My String' (but put something more interesting in the string). Print the contents of this variable in two ways, first by simply typing the variable name and pressing Enter, then by using the print statement.
>>> my_string = 'Hello'
>>> print my_string
Hello
>>>
b. Try adding the string to itself using my_string + my_string, or multiplying it by a number, e.g., my_string * 3. Notice that the strings are joined together without any spaces. How could you fix this?
my_string+' '+my_string
10. ○ Define a variable my_sent to be a list of words, using the syntax my_sent = ["My", "sent"] (but with your own words, or a favorite saying).
a. Use ' '.join(my_sent) to convert this into a string.
>>> ' '.join(my_sent)
'My sent'
b. Use split() to split the string back into the list form you had to start with.
>>> 'My sent'.split()
['My', 'sent']
11. ○ Define several variables containing lists of words, e.g., phrase1, phrase2, and so on. Join them together in various combinations (using the plus operator) to form whole sentences. What is the relationship between len(phrase1 + phrase2) and len(phrase1) + len(phrase2)?
>>> phrase1=['Hello']
>>> phrase2=[' ,World!']
>>> phrase1+phrase2
['Hello', ' ,World!']
>>> len(phrase1 + phrase2)
2
>>> len(phrase1) + len(phrase2)
2
>>> len(phrase1 + phrase2)==len(phrase1) + len(phrase2)
True
>>> len(phrase1 + phrase2) is len(phrase1) + len(phrase2)
True
12. ○ Consider the following two expressions, which have the same value. Which one will typically be more relevant in NLP? Why?
a. "Monty Python"[6:12]
b. ["Monty", "Python"][1]
b. 因为在NLP中主要处理的元素是单词,words
13. ○ We have seen how to represent a sentence as a list of words, where each word is a sequence of characters. What does sent1[2][2] do? Why? Experiment with other index values.
列表中第3个字符中的第三个元素
14. ○ The first sentence of text3 is provided to you in the variable sent3. The index of the in sent3 is 1, because sent3[1] gives us 'the'. What are the indexes of the two other occurrences of this word in sent3?
我只有这个办法,想不起其他方法了…index()只查找列表里第一个匹配的。
>>> [i for i,j in enumerate(sent3) if j=='the']
[1, 5, 8]
15. ○ Review the discussion of conditionals in Section 1.4. Find all words in the Chat Corpus (text5) starting with the letter b. Show them in alphabetical order.
sorted(set([v for v in text5 if v.startswith('b')]))
16. ○ Type the expression range(10) at the interpreter prompt. Now try range(10, 20), range(10, 20, 2), and range(20, 10, -2). We will see a variety of uses for this built-in function in later chapters.
range的说明文档
range([start,] stop[, step]) -> list of integers
Return a list containing an arithmetic progression of integers.
range(i, j) returns [i, i+1, i+2, ..., j-1]; start (!) defaults to 0.
When step is given, it specifies the increment (or decrement).
For example, range(4) returns [0, 1, 2, 3]. The end point is omitted!
These are exactly the valid indices for a list of 4 elements.
17. ◑ Use text9.index() to find the index of the word sunset. You’ll need to insert this word as an argument between the parentheses. By a process of trial and error, find the slice for the complete sentence that contains this word.
没有用什么技巧,so我觉得此办法不够简洁,哪位有更好的方法?
import nltk
from nltk.book import *
for var in [i for i,j in enumerate(text9) if j=='sunset']:
ori_var=var
pun=['!','?','.']
start=0
stop=0
while start==0 or stop==0:
if text9[var] in pun and stop==0:
stop=var+1
var=ori_var
elif text9[var] not in pun and stop==0:
var+=1
elif text9[var] not in pun and stop!=0 and start==0:
var-=1
elif text9[var] in pun and stop!=0:
start=var+1
print 'start from %d to end in %d'%(start,stop)
print ' '.join(text9[start:stop])
还有一种方法,用两个集合,一个存放sunset的位置,一个存放标点符号的位置,然后将sunset插入到标点符号之间
18. ◑ Using list addition, and the set and sorted operations, compute the vocabulary of the sentences sent1 ... sent8.
voc=[]
for sent in [sent1,sent2,sent3,sent4,sent5,sent6,sent7,sent8]:
voc+=sent
sorted(set(voc))
没说要求去掉符号和数字。
['!', ',', '-', '.', '1', '25', '29', '61', ':', 'ARTHUR', 'Call', 'Citizens', 'Dashwood', 'Fellow', 'God', 'House', 'I', 'In', 'Ishmael', 'JOIN', 'KING', 'MALE', 'Nov.', 'PMing', 'Pierre', 'Representatives', 'SCENE', 'SEXY', 'Senate', 'Sussex', 'The', 'Vinken', 'Whoa', '[', ']', 'a', 'and', 'as', 'attrac', 'been', 'beginning', 'board', 'clop', 'created', 'director', 'discreet', 'earth', 'encounters', 'family', 'for', 'had', 'have', 'heaven', 'in', 'join', 'lady', 'lol', 'long', 'me', 'nonexecutive', 'of', 'old', 'older', 'people', 'problem', 'seeks', 'settled', 'single', 'the', 'there', 'to', 'will', 'wind', 'with', 'years']
19. ◑ What is the difference between the following two lines? Which one will give a larger value? Will this be the case for other texts?
>>> sorted(set([w.lower() for w in text1]))
>>> sorted([w.lower() for w in set(text1)])
不同,
第一句,对于text1中的所有w先小写(如A和a都变成a了),然后set,删除相同元素(a只保留一个)。
第二句,先set(text1),删除相同元素(A和a是两个不同的元素),然后变成小写的(那么就有相同的元素a了),所以值更大
Will this be the case for other texts? 应该是吧,我没有去试
20. ◑ What is the difference between the following two tests: w.isupper() and not w.islower()?
w.isupper() 全大写
w.islower() 全小写
not w.islower() 可能包括了数字,标点符号
21. ◑ Write the slice expression that extracts the last two words of text2.
text2[-2:]
22. ◑ Find all the four-letter words in the Chat Corpus (text5). With the help of a frequency distribution (FreqDist), show these words in decreasing order of frequency.
fdist=FreqDist([w for w in text5 if len(w)==4])
for s in fdist:
print fdist.freq(s)
23. ◑ Review the discussion of looping with conditions in Section 1.4. Use a combination of for and if statements to loop over the words of the movie script for Monty Python and the Holy Grail (text6) and print all the uppercase words, one per line.
for eachword in text6:
if eachword.isupper():
print eachword
24. ◑ Write expressions for finding all words in text6 that meet the following conditions. The result should be in the form of a list of words: ['word1', 'word2', ...].
a. Ending in ize
b. Containing the letter z
c. Containing the sequence of letters pt
d. All lowercase letters except for an initial capital (i.e., titlecase)
a.
speclist=[]
for eachword in text6:
if eachword.endswith(‘ize’):
speclist.append(eachword)
b.
speclist=[]
for eachword in text6:
if ‘z’ in eachword:
speclist.append(eachword)
c.只改判断语句if ‘pt’ in eachword,其他相同
d. if eachword.istitle():
25. ◑ Define sent to be the list of words ['she', 'sells', 'sea', 'shells', 'by', 'the', 'sea', 'shore']. Now write code to perform the following tasks:
a. Print all words beginning with sh.
sent=['she', 'sells', 'sea', 'shells', 'by', 'the', 'sea', 'shore']
for words in sent:
if words.startswith(‘sh’):
print words
b. Print all words longer than four characters
for words in sent:
if len(words)>4:
print words
26. ◑ What does the following Python code do? sum([len(w) for w in text1]) Can you use it to work out the average word length of a text?
统计text1的字符总长
average_word_length= sum([len(w) for w in text1])/len(text1)
27. ◑ Define a function called vocab_size(text) that has a single parameter for the text, and which returns the vocabulary size of the text.
def vocab_size(text):
count=0
for vocab in text:
count+=len(vocab)
return count
28. ◑ Define a function percent(word, text) that calculates how often a given word occurs in a text and expresses the result as a percentage.
import nltk
from nltk.book import *
def percent(word, text):
count=0
for words in text:
if words==word:
count+=1
return '%f%%'%(count*1.0/len(text)*100)
29. ◑ We have been using sets to store vocabularies. Try the following Python expression: set(sent3) < set(text1). Experiment with this using different arguments to set().
What does it do? Can you think of a practical application for this?
sent3的词汇集合属于text1的词汇集合
set()属于集合概念,可用来评价分词的性能,例如,已分完词的集合A与词典B比较,列出不属于B的单词集合。
set(A)-set(B)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号