

目前平台使用Kafka + Flume的方式进行实时数据接入,Kafka中的数据由业务方负责写入,这些数据一部分由Spark Streaming进行流式计算;另一部分数据则经由Flume存储至HDFS,用于数据挖掘或机器学习。HDFS存储数据时目录的最小逻辑单位为“小时”,为了保证数据计算过程中的数据完整性(计算某个小时目录中的数据时,该目录的数据全部写入完毕,且不再变化),我们在Flume中加入了如下策略:
每五分钟关闭一次正在写入的文件,即新创建文件进行数据写入。
这样的方式可以保证,当前小时的第五分钟之后就可以开始计算上一小时目录中的数据,一定程度上提高了离线数据处理的实时性。
随着业务的增加,开始有业务方反馈:“HDFS中实际被分析的数据量很小,但是Spark App的Task数目却相当多,不太正常”,我们跟进之后,发现问题的根源在于以下三个方面:
(1)Kafka的实时数据写入量比较小;
(2)Flume部署多个实例,同时消费Kafka中的数据并写入HDFS;
(3)Flume每五分钟会重新创建文件写入数据(如上所述);
这样的场景直接导致HDFS中存储着数目众多但单个文件数据量很小的情况,间接影响着Spark App Task的数目。
我们以Spark WordCount为例进行说明,Spark版本为1.5.1。
假设HDFS目录“/user/yurun/spark/textfile”中存在以下文件:
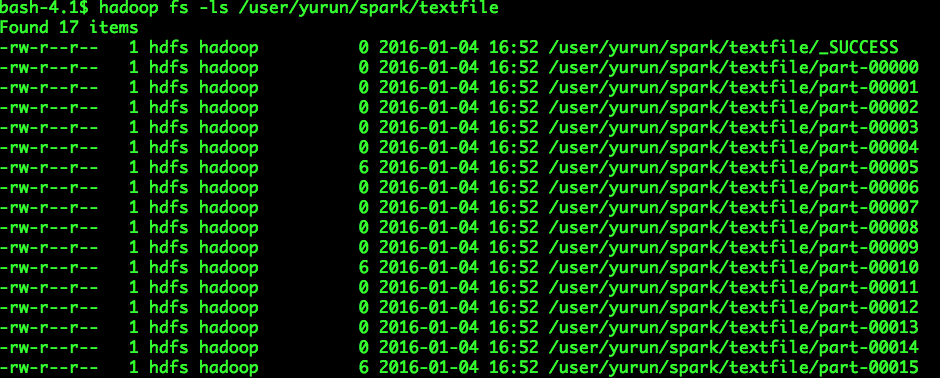
这个目录下仅三个文件包含少量数据:part-00005、part-00010、part-00015,数据大小均为6 Byte,其余文件数据大小均为0 Byte,符合小文件的场景。
注意:_SUCCESS相当于一个“隐藏”文件,实际处理时通常会被忽略。
常规实现
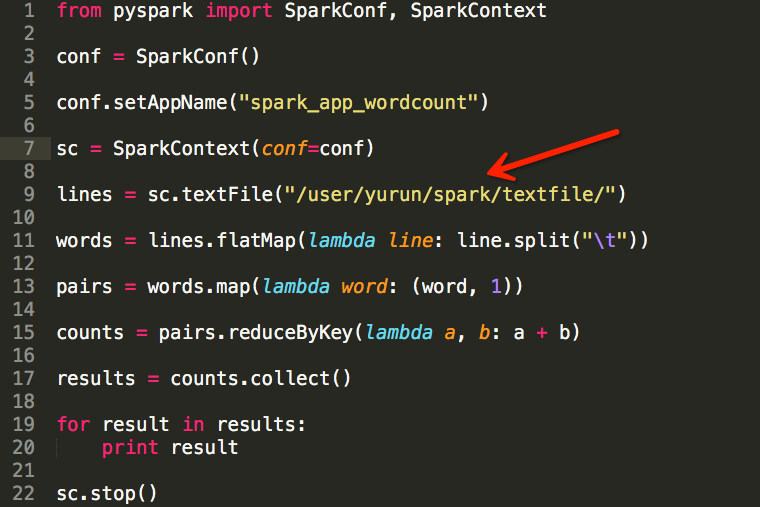
我们使用SparkContext textFile完成数据输入,应用运行完成之后,通过Spark History Server的页面可以看到:应用执行过程中,会产生一个Job,包含两个Stage,每个Stage包含16个Task,也就是说,Task的总数目为32,如下图所示:


之所以每个Stage包含16个Task,是因为目录中存有16个文本文件(_SUCCESS不参与计算)。
优化实现

在这个优化的版本中,我们使用SparkContext newAPIHadoopFile完成数据输入,需要着重说明一下“org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat”,这个类可以将多个小文件合并生成一个Split,而一个Split会被一个Task处理,从而减少Task的数目。这个应用的执行过程中,会产生两个Job,其中Job0包含一个Stage,一个Task;Job1包含两个Stage,每个Stage包含一个Task,也就是说,Task的总数目为3,如下图所示:



可以看出,通过使用“org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat”可以很大程度上缓解小文件导致Spark App Task数目过多的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号