


TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu
import tensorflow as tf from sklearn.datasets import load_digits #from sklearn.cross_validation import train_test_split from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer # load data digits = load_digits() X = digits.data y = digits.target y = LabelBinarizer().fit_transform(y) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, ) Wx_plus_b = tf.matmul(inputs, Weights) + biases # here to dropout Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b, ) tf.summary.histogram(layer_name + '/outputs', outputs) return outputs # define placeholder for inputs to network keep_prob = tf.placeholder(tf.float32) xs = tf.placeholder(tf.float32, [None, 64]) ys = tf.placeholder(tf.float32, [None, 10]) # add output layer l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh) prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax) # the loss between prediction and real data cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) tf.summary.scalar ('loss', cross_entropy) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session() merged = tf.summary.merge_all() # summary writer goes in here train_writer = tf.summary.FileWriter("logs4/train", sess.graph) test_writer = tf.summary.FileWriter("logs4/test", sess.graph) sess.run(tf.global_variables_initializer()) for i in range(500): # here to determine the keeping probability sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) if i % 50 == 0: # record loss train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1}) train_writer.add_summary(train_result, i) test_writer.add_summary(test_result, i)
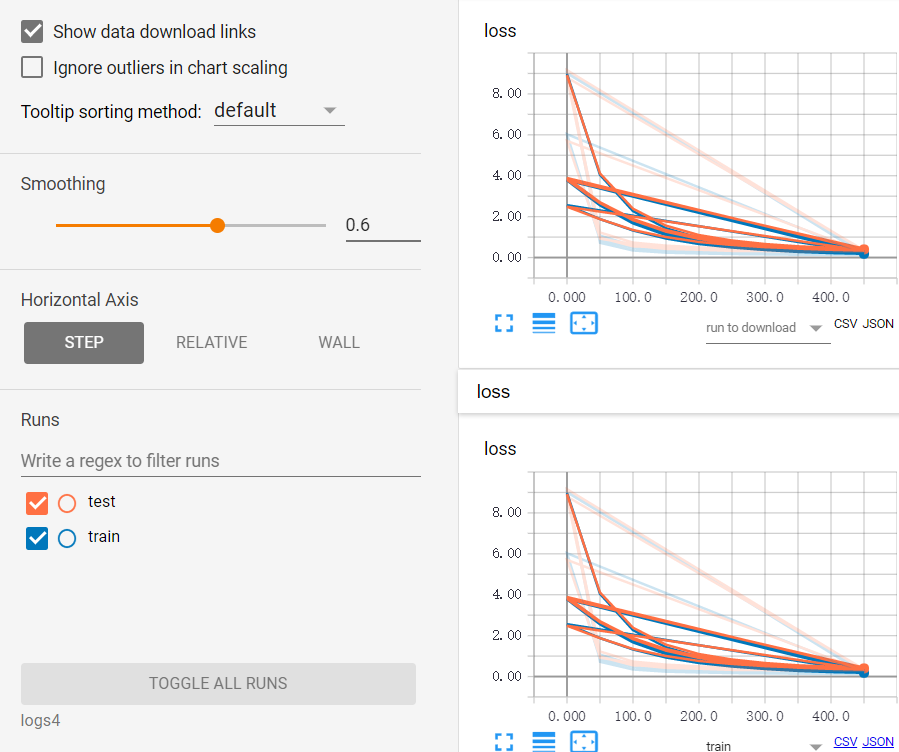
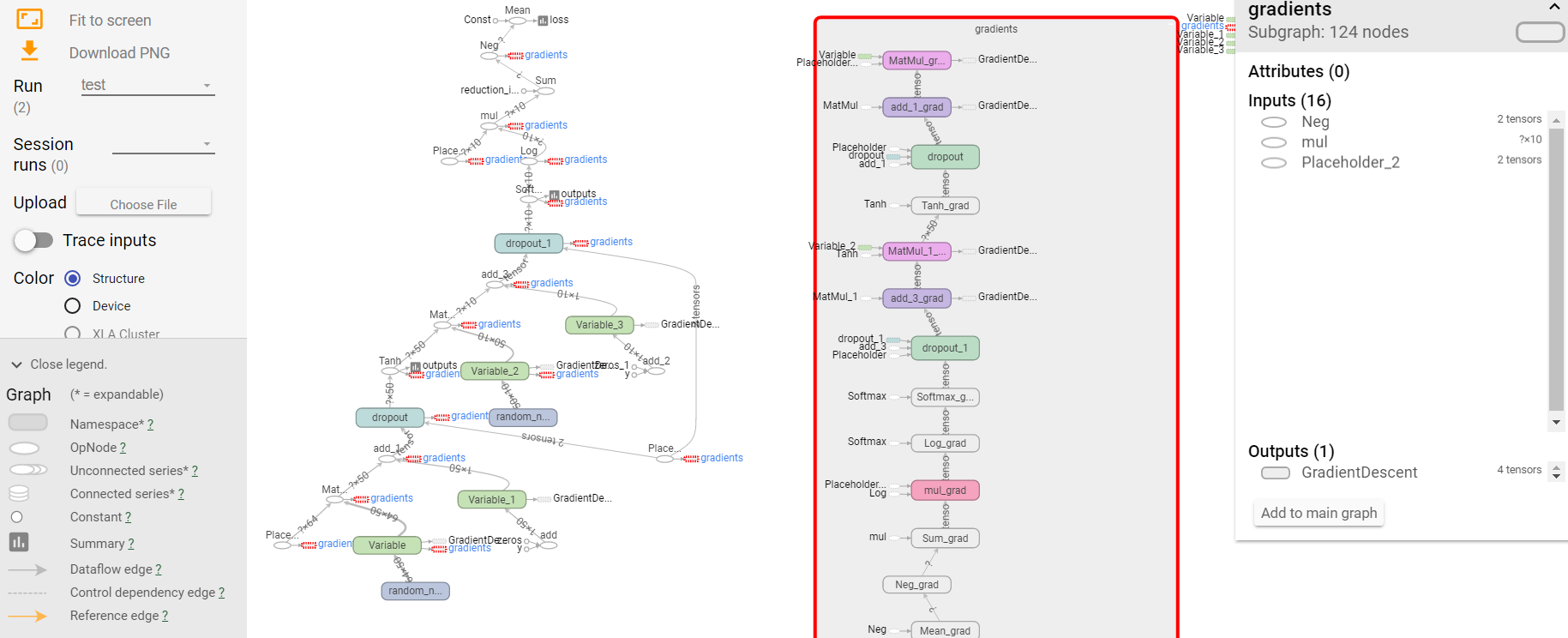
不念过去,不畏将来!
理想,信仰,使命感……
愿你出走半生,归来仍是少年……
