


工厂模式——抽象工厂模式(+反射)
这里又出现了一个抽象工厂模式,这个抽象工厂模式又是什么呢?
我们现在来模拟一个场景,现在用的是Mysql数据库,明天让你更换为Oracle数据库。此时,想想要做多少的改动。但我们如果用工厂模式,这会让你节省大量时间。
首先,我们用工厂方法模式来设计这个程序。
我们画出类的UML图。
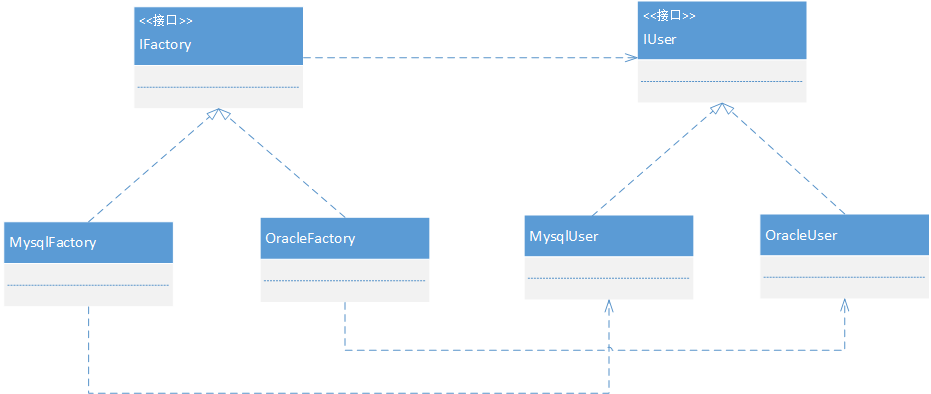
IFactory作为工厂类的接口,有两个子类,分别用来构造不同的实例。
IFactory工厂接口代码如下:
package day_3_facoryMethod_db; /** * 数据库工厂类 * @author turbo * * 2016年9月6日 */ public interface IFactory { IUser createUser(); }
MysqlFactory代码如下,省去OracleFactory。
package day_3_facoryMethod_db; /** * @author turbo * * 2016年9月6日 */ public class MysqlFactory implements IFactory { /* (non-Javadoc) * @see day_3_facoryMethod_db.IFactory#createUser() */ @Override public IUser createUser() { return new MysqlUser(); } }
IUser是对User表操作的接口,不同数据库的操作只需继承实现它即可。
package day_3_facoryMethod_db; /** * 操作数据库User表的接口 * @author turbo * * 2016年9月6日 */ public interface IUser { void insert(User user); User getUserById(int userId); }
MysqlUser是对IUser接口的实现,是对User表操作的具体实现。省去OracleUser。
package day_3_facoryMethod_db; /** * Mysql对User表的操作 * @author turbo * * 2016年9月6日 */ public class MysqlUser implements IUser { /* (non-Javadoc) * @see day_3_facoryMethod_db.IUser#insert(day_3_facoryMethod_db.User) */ @Override public void insert(User user) { System.out.println("插入一条数据"); } /* (non-Javadoc) * @see day_3_facoryMethod_db.IUser#getUserById(int) */ @Override public User getUserById(int userId) { System.out.println("获取一条数据"); return null; } }
现在通过客户端代码来观察是如何做到业务逻辑和数据访问的解耦的。
package day_3_facoryMethod_db; /** * 客户端 * @author turbo * * 2016年9月6日 */ public class Main { public static void main(String[] args){ IFactory factory = new MysqlFactory(); //如果需要修改数据库,则只需将new MysqlFactory()修改为new OracleFactory()。 IUser iu = factory.createUser(); iu.insert(new User()); iu.getUserById(1); } }
如果要更改数据库,则只需将new MysqlFactory()修改为new OracleFactory()即可,这就是所谓的业务逻辑和数据访问的解耦。
上面我们实际上重新回顾了工厂方法模式,似乎已经达到了我们想要的效果。但是,数据库里不止一张表,两个数据库又是两大不同分类,解决这种涉及多个产品系列的问题,有一个专门的工厂模式叫抽象工厂模式。所以实际上,如果增加一个新表,上面的工厂方法模式就有了一个新的名字——抽象工厂模式。
抽象工厂模式:提供一个创建一些列有关或互相依赖对象的接口,而无需制定它们具体的类。
下面我们进阶一下:用反射+抽象工厂的方式来设计这个程序。
是否记得在简单工厂模式中,我们用到了switch或者if。有用到switch和if的地方,我们都可以考虑利用反射技术来去除,以解除分支带来的耦合。
这其实将会引申一个概念:依赖注入(DI),或者称为控制反转,将传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理,什么意思?就是直观上代码里看不到new 对象,这个操作交给了外部容器,这样将会大大降低程序的耦合性。比如:Spring框架的IoC容器。
我们先来看如果要实例化上面的的IUser会怎么做?
IUser iu = new MysqlUser();
如果是用反射呢?
Class classType = Class.forName("day_3_facoryMethod_db.MysqlUser"); //“类所在的包名.类名”
Object obj = classType.newInstance();
我们对obj做验证。
System.out.println(obj instanceof MysqlUser);
输出为true,用反射机制成功实例化对象。
反射和直接new有什么区别呢?答案就在于:反射使用的字符串,也就是说可以用变量来处理。而new的常规方法是已经编译好了的,不能随意灵活更换其实例化对象。所以,思考,如果我们用配置文件的方式,是不是能灵活替换我们想要的实例化对象呢?

