
分布式网络爬虫关键技术分析与实现——分布式网络爬虫体系结构设计
一、 研究所属范围
分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行。由于并行爬行器需要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网络爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网络连接相互通信。这些爬虫通过同一个网络去访问外部互联网,下载网页,所有的网络负载都集中在他们所在的那个局域网的出口上。由于局域网的带宽较高,爬虫之间的通信的效率能够得到保证;但是网络出口的总带宽上限是固定的,爬虫的数量会受到局域网出口带宽的限制。
2、基于广域网分布式网络爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网络位置),我们称这种并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能位于中国,日本,和美国,分别负责下载这三地的网页;或者位于CHINANET,CERNET,CEINET,分别负责下载这三个网络的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网络流量,减小网络出口的负载。如果爬虫分布在不同的地理位置(或网络位置),需要间隔多长时间进行一次相互通信就成为了一个值得考虑的问题。爬虫之间的通讯带宽可能是有限的,通常需要通过互联网进行通信。
在实际应用中,基于局域网分布式网络爬虫应用的更广一些,而基于广域网的爬虫由于实现复杂,设计和实现成本过高,一般只有实力雄厚和采集任务较重的大公司才会使用这种爬虫。本论文所设计的爬虫就是基于局域网分布式网络爬虫。
二、分布式网络爬虫整体分析
分布式网络爬虫的整体设计重点应该在于爬虫如何进行通信。目前分布式网络爬虫按通信方式不同分布式网路爬虫可以分为主从模式、自治模式与混合模式三种。
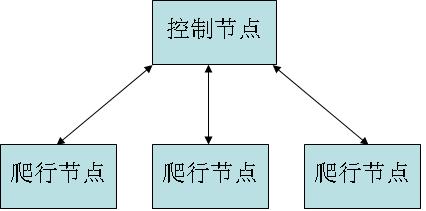
主从模式是指由一台主机作为控制节点负责所有运行网络爬虫的主机进行管理,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单利于管理。而控制节点则需要与所有爬虫进行通信,它需要一个地址列表来保存系统中所有爬虫的信息。当系统中的爬虫数量发生变化时,协调者需要更新地址列表里的数据,这一过程对于系统中的爬虫是透明的。但是随着爬虫网页数量的增加。控制节点会成为整个系统的瓶颈而导致整个分布式网络爬虫系统性能下降。主从模式的整体结构图:
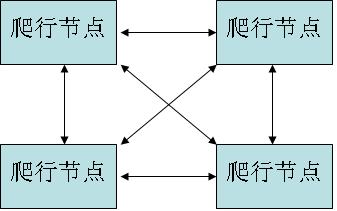
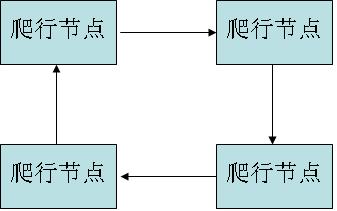
自治模式是指系统中没有协调者,所有的爬虫都必须相互通信,比主从模式下爬虫要复杂一些。自治模式的通信方式可以使用全连接通信或环形通信。全连接通信是指所用爬虫都可以相互发送信息,使用这种方式的每个网络爬虫会维护一个地址列表,表中存储着整个系统中所有爬虫的位置,每次通信时可以直接把数据发送给需要此数据的爬虫。当系统中的爬虫数量发生变化时,每个爬虫的地址列表都需要进行更新。环形通信是指爬虫在逻辑上构成一个环形网,数据在环上按顺时针或逆时针单向传输,每个爬虫的地址列表中只保存其前驱和后继的信息。爬虫接收到数据之后判断数据是否是发送给自己的,如果数据不是发送给自己的,就把数据转发给后继;如果数据是发送给自己的,就不再发送。假设整个系统中有n个爬虫,当系统中的爬虫数量发生变化时,系统中只有n-1个爬虫的地址列表需要进行更新。
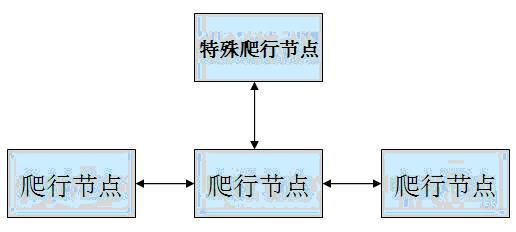
混合模式是结合上面两种模式的特点的一种折中模式。该模式所有的爬虫都可以相互通信同时都具有任务分配功能。不过所有爬虫中有个特殊的爬虫,该爬虫主要功能对已经经过爬虫任务分配后无法分配的任务进行集中分配。使用这个方式的每个网络爬虫只需维护自己采集范围的地址列表。而特殊爬虫需除了保存自己采集范围的地址列表外还保存需要进行集中分配的地址列表。混合模式的整体结构图:
三、大型分布式网络爬虫体系结构图:
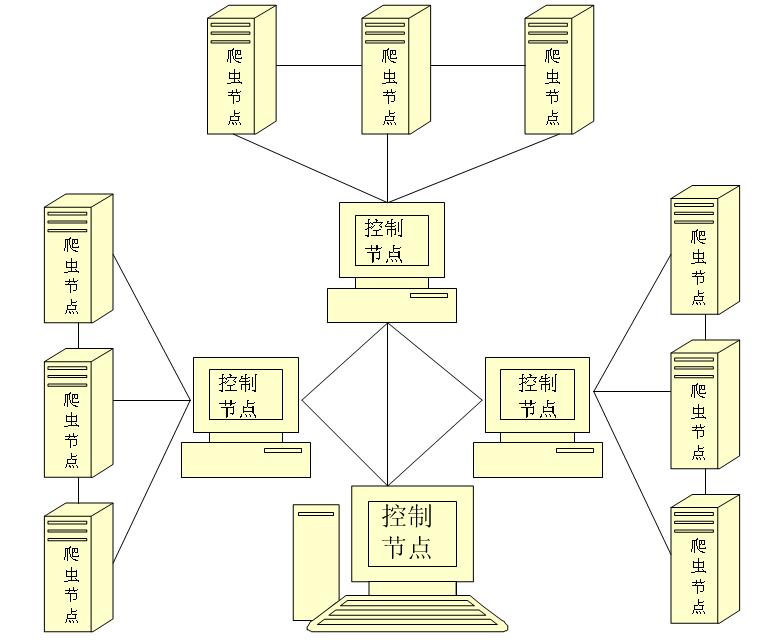
从这些图可以看出,分布式网络爬虫是一项十分复杂系统。需要考虑很多方面因素。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。不过不在本系列考虑范围。从下篇开始,我将从单机网络爬虫一步步介绍我们需要考虑的问题的解决方案。如果大家有更好的解决方案。欢迎指教。
吉日的一句话说的很有道理,一个人一辈子只能做好几件事。希望大家支持我的这个系列。

