
调参,正则化
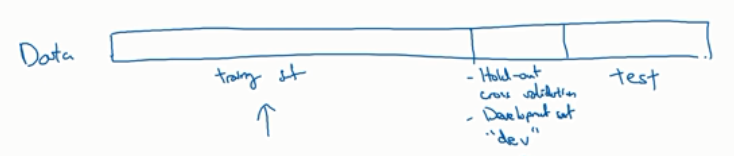
1.数据集的划分:
训练集(train),
交叉验证集(dev):用来选取最好的模型,选择最好的算法(需要验证的可能是很多个算法)
测试集(test):用来评估
有时候不需要无偏估计的时候,就只需要训练集和验证集
确保dev ,train来自同一个分布
划分:70%train dev 30%test 百万数据;或者60%,20%,20%(小数据的划分)过百万数据
大数据时代:验证集和测试集占比要减小:98%,1%,1%;99.,5%,0.4%,0.1%;99.,5%,0.25%,0.25%
2.偏差方差的均衡
衡量指标
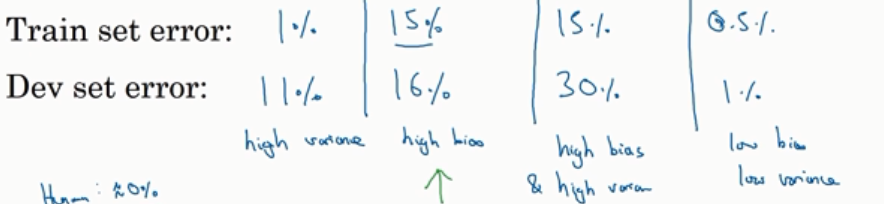
最优误差(贝叶斯误差):0%时,对应上面的误差可以得出,高方差,高偏差(16%的验证误差是由15%的训练误差+1%新误差产生),偏方差都高。
当最优误差很大时上诉分析不合适;所以要最优误差小,训练集和验证集来自同一个分布
