
Tensorflow(一)
One_hot#
一个长度为n的数组,只有一个元素是1,其他元素是0。
在n为8的情况下,标签2对应的One_hot标签是
00100000
使用One_hot是因为cnn网络的输出通常是softmax层,其输出是一个概率分布,所以输入的标签也以概率分布的形式的出现,从而进行交叉熵计算。
训练神经网络的过程#
- 定义神经网络的结构和前向传播的输出的结果
- 定义损失函数以及选择反向传播优化的算法
- 生成会话,并且在训练数据上反复运行反向传播优化算法
无论神经网络的结构如何变化,这3个步骤是不变的
张量与变量#
Tensorflow的核心概念是张量,所有的数据都是通过张量的形式来组织的,变量声明函数tf.Variable是一个运算,这个运算的输出就是一个张量。所以变量只是一种特殊的张量。
可以通过声明函数中的trainble参数来区分需要优化的参数和其他参数。如果声明变量时参数trainable为True,那么这个变量会被加入GrapKeys.TRAINBLE_VRIABLES集合。在Tensorflow中可以通过tf.trainable_variable函数得到所有需要优化的参数,tensorflow中提供给的神经网络优化算法会将GraphKeys.TRAINABLE_BARIABLES集合中的变量作为默认的优化对象。
维度和类型#
维度和类型也是变量最重要的两个属性,和大部分程序语言类似,变量的类型是不可改变的,一个变量在构建后,它的类型就不能再改变了。
维度是变量另一个重要的属性,和类型不大一样的是,维度在程序运行中是有可能改变的,但是需要通过设置参数validate_shape=False,不过尽管支持改变,但是这种用法在实践中比较罕见。
Placeholder#
如果每次迭代中选取的数据都要通过常量来表示,那么tensorflow的计算图将会太大, 因为每生成一个常量,tensorflow都会在计算图中增加一个节点,一般来说,一个神经网络的训练会需要经过几百万升值几亿轮次的迭代,这样计算图就会非常大,而且利用率很低,为了避免这个问题,tensorflow提供了placeholder机制用于提供输入数据,placeHolder相当于定义了一个位置,这个位置中的数据在程序运行时再指定,这样在程序中就不要生成大量常量来提供输入数据,而只需要将数据通过placeholder传入tensorflow计算图,在placeholder定义时,这个位置上的数据类型是需要指定的,和其他张量一样,placehodler的类型也是不可以改变的,placeholder中数据的维度信息可以根据提供的数据推导给出。
将一个张量中的数值限制在一个范围内#
v=tf.constant([[1.0,2.0,3.0),[4.0,5.0,6.0]])
tf.clip_by_value(v,2.5,4.5).eval()
输出[[2.5,2.5,3.],[4,4,5,4.5]]
可以看出,小于2.5的数都被换成了2.5,大于4.5的数被换成了4.5,这样就可以保证在进行相关运算,如log运算时,不会出现log0这样的错误或者大于1的概率。
对张量中所有的元素以此求对数#
v=tf.constant([1.0,2.0,3.0])
tf.log(v).eval()
输出[0.,0/693214718,1.0966123]
比较张量中每一个元素的大小#
tf.greater(v1,v2).eval()
输入的是两个张量,比较两个输入张量中每一个元素的大小,并返回比较结果,如果输入的张量维度不一样,会进行类似numpy广播操作的处理。
tf.select#
tf.select(tf.greater(v1,v2),v1,v2).eval()
tf.select函数会根据第一个参数判断选择第二个参数还是第三个参数。tf.select函数判断和选择都是在元素级别进行。
v1=tf.constant([1,2,3,4])
v2=tf.constant([4,3,2,1])
tf.greater(v1,v2).eval()
输出[F,F,T,T]
tf.select(tf.greater(v1,v2),v1,v2).eval()
输出 [4,3,4,4]
session#
Tensorflow中的Session来执行定义好的运算,会话拥有并管理程序运行时的所有资源。
sess=tf.Session()
sess.run(...)
sess.close
这种模式在计算完成之后,需要明确调用Session.close函数来关闭会话并释放资源。否则会造成资源泄露。
with tf.Session() as sess
sess.run(...)
这种通过Python上下文管理器的机制,只要将计算放在with内部就可以,当上下文管理器退出时候会自动释放所有的资源。
Tensorflow会自动生成一个默认的计算图,若是没有特殊指定,运算会自动加入这个计算图中,tensorflow中的会话也有类似的机制,但tensorflow不会自动生成默认的会话,需要手动指定,当默认的会话被指定后,可以通过tf.Tensor,eval函数来计算一个张量的取值
sess=tf.Session()
with sess.as_default():
print(result.eval())
在交互环境下, tensorflow提供了一种在交互式环境下直接构建默认会话的函数.tf.InteractiveSession,使用这个函数会自动将生成的会话注册为默认会话。
变量管理#
Tensorflo提供了通过变量名称来创建或者获取一个变量的机制。通过这个机制,在不同的函数中可以通过变量的名字 来使用变量,而不需要将变量通过参数的形式到处传递。tensorflow中通过变量名称获取变量的机制主要通过tf.get_variable和tf.variable_scope函数实现。
tf.get_variable函数创建或者获取变量。当用于创建变量时,它和tf,Variable的功能基本等价。
v=tf.get_variable("v",sape=[1],initializer=tfconstant_ininializer(1,0))
v=tf.Variable(tf.constant(1.0,shape=[1]),name="v")
tensorflow提供的initializer函数和随机数及常量产生的函数大部分是一一对应的。tensorflow提供了7种不同的初始化函数。
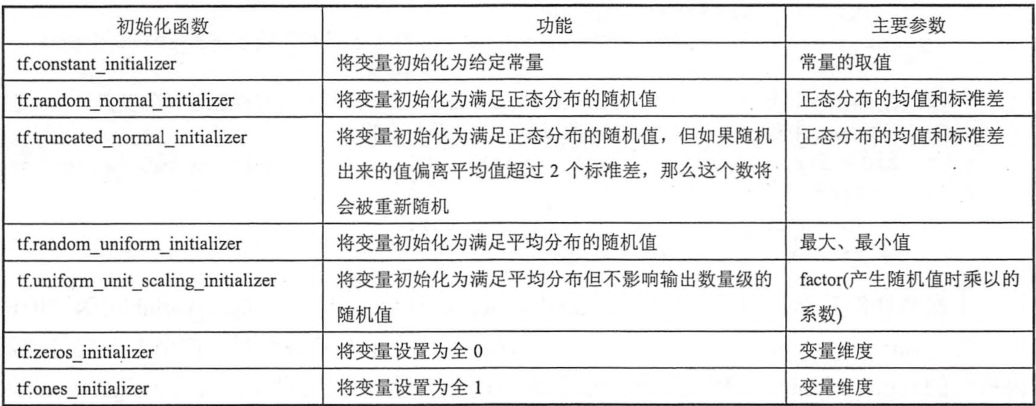
tf.get_variable和tf.Variable函数最大的区别在于指定变量名称的参数。对于tf.Variable函数,变量名称是一个可选的参数 ,通过name="v"的形式给出。但是对于tf,get_variable函数,变量名称是一个必填的参数,tf.get_variable会根据这个名字去创建或者获取变量。即它会先试图去创建一个指定名字的参数,如果创建失败(比如已经存在同名的参数),那么程序就报错,这是为了避免变量复用的危险。
如果需要通过tf.get_variable获取一个已经创建的变量,需要通过tf.variable_scope来生成一个上下文管理器,且须明确指定在这个上下文管理器中,tf.get_variable奖直接获取已经生成的变量。即是将tf.variable_scope的resuse参数设置为True。
with tf.variable_scope('foo')
v=tf.get)variable("v",[1].initializer=tf.constant_initializer(1.0))
with tf.variable_scope("foo",reuse=True)
v1=tf.get_variable("v",[1])
将reuse设置为true时,将只能获取已经创建的变量,如果命名空间内没有创建指定获取的变量,那么将会报错。默认resue参数为None等同于False,如果在嵌套内,默认值为父上下文管理器的参数。
tf.variable_scope函数生成的上下文管理器也会创建一个tensorflow中的命名空间,在命名空间内创建的变量名称都会带上这个命名空间作为前缀。
v1=tf.get_variable("v",[1])
print(v1.name)
输出v:0 为变量的名称 :0表示这个变量是生成变量这个运算的第一个结果
with tf.variable_scope("fool"):
v2=tf.get_variable("v",[1])
print(v2.name)
输出foo/v:0 在tf.variable_scope中创建的变脸,名称前会加入命名空间的名称,并同过/来分隔空间的名称和变量的名称
持久化#
Tensorflow中的 tf.train.Saver类用来保存和还原一个神经网络模型
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(op)
saver.save(sess,“../../model.ckpt”)
以上代码实现了简单得多持久化模型,tensorflow模型一般会存在后缀为.ckpt的文件中,在保存的文件目录中会出现三个文件,这是因为计算图的结构和图上参数取值是分开保存的。
model.ckpt.meta保存的是计算图的结构
model.ckpt保存的是每一个变量的取值
checkpoint文件保存了一个 目录下所有模型文件列表
加载 已经保存的模型
v1=tf.Variable(tf.constant(1.0,shape=[1]))
v2=tf.Variable(tf.constant(2.0,shape=[1]))
saver=tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,“../../model.ckpt”)
print(sees,run(v1))
这种加载方式,需要在加载变量时,先创建指定变量,才能读入
saver=tf.train.import_meta_graph(../../model.ckpt/model.ckpt.meta)
with tf.Session() as sess:
saver.restore(sess,"/path/to/model/model.ckpt)
print sess.run(tf.get_default_graph().get_tensor_by_name(add:0))
这种方式,需要加载变量时,可以直接读入
为了保存或者加载部分变量,在生命Saver类时可以提供一个列表来指定需要保存或加载的变量
saver=tf.train.Saver([v1])
以上只有v1会被加载进来。
Saver类也支持在保存或者加载时给变量重命名
v1=tf.Variable(tf.constant(1.0,shape=[1]),name="other-v1")
v2=tf.Variable(tf.constant(2.0,shape=[1]),name="other-v2");
如果直接用tf.train.Saver()加载模型会报变量找不到的错误。
使用一个字典来重命名变量就可以加载原来的模型了,字典指定了原来名称为v1的变量现在加载到变量v1中,名称为v2的变量加载到变量v2中
saver=tr.train.Saver({"v1":v1,"v2":v2})
对变量v1和v2进行了修改,如果直接通Saver默认的构造函数来加载保存的模型,那么程序会报变量找不到的错误,因为保存时变量的名称和加载时变量的名称不一致。tensorflow中可以通过字典将模型保存时的变量名和需要加载的变量联系起来。
