

本节内容
- 模块初识
- .pyc是什么?
- 数据类型初识
- 数据运算
- 入门知识拾遗
一、模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
sys
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#sys.argv[0] sys.argv[1] sys.argv[2] 对应的位置 |
os
|
1 2
3
4
5 6 |
|
另一个例子:
>>> import os
>>> cmd_res=os.system("dir")
驱动器 C 中的卷是 Windows
卷的序列号是 C40C-8699
C:\Users\ysuking的目录
2017/12/16 16:58 <DIR> .
2017/12/16 16:58 <DIR> ..
2017/09/14 16:34 <DIR> .android
2017/09/21 17:19 <DIR> .PyCharm2017.1
2018/01/10 13:24 <DIR> Videos
0 个文件 0 字节
17 个目录 83,628,920,832 可用字节
>>> print(cmd_res)
0 #结果为0;执行命令不保存结果,保存返回值,0表示执行正常,与linux的$?执行结果类似。
>>> cmd_res1=os.popen("dir")
>>> print(cmd_res1)
<os._wrap_close object at 0x03755850> #os.popen()函数:打印内存对象地址
>>> cmd_res2=os.popen("dir").read() #想要打印出来命令执行内容,在popen()后加.read()函数即可
>>> print(cmd_res2)
驱动器 C 中的卷是 Windows
卷的序列号是 C40C-8699
C:\Users\ysuking的目录
2017/12/16 16:58 <DIR> .
2017/12/16 16:58 <DIR> ..
2017/09/14 16:34 <DIR> .android
2017/09/21 17:19 <DIR> .PyCharm2017.1
2018/01/10 13:24 <DIR> Videos
0 个文件 0 字节
17 个目录 83,626,369,024 可用字节
完全结合一下
|
1 2 3 |
|
自己写个模块
python tab补全模块
for mac
1 import sys
2 import readline
3 import rlcompleter
4
5 if sys.platform == 'darwin' and sys.version_info[0] == 2:
6 readline.parse_and_bind("bind ^I rl_complete")
7 else:
8 readline.parse_and_bind("tab: complete") # linux and python3 on mac
for Linux
1 #!/usr/bin/env python
2 # python startup file
3 import sys
4 import readline
5 import rlcompleter
6 import atexit
7 import os
8 # tab completion
9 readline.parse_and_bind('tab: complete')
10 # history file
11 histfile = os.path.join(os.environ['HOME'], '.pythonhistory')
12 try:
13 readline.read_history_file(histfile)
14 except IOError:
15 pass
16 atexit.register(readline.write_history_file, histfile)
17 del os, histfile, readline, rlcompleter
写完保存后就可以使用了
|
1 2 3 4 5 |
|
你会发现,上面自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
二、.pyc是什么?
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
三、数据类型初识
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。(python3中没有了,只有int)
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3
* 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。在量子力学、空气动力学等物理学科使用。
注:Python中存在小数字池:-5 ~ 257
2、布尔值
真或假
1 (True)或 0 (False,跟执行命令返回码相反)
3、字符串
"hello world"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化输出
|
1 2 3 4 |
|
PS: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
- 移除空白
- 分割
- 长度
- 索引
- 切片
4、列表
创建列表:
|
1 2 3 |
|
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
5、元组(不可变列表)
创建元组:
|
1 2 3 |
|
6、字典(无序)
创建字典:
|
1 2 3 |
|
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
四、数据运算
算数运算:
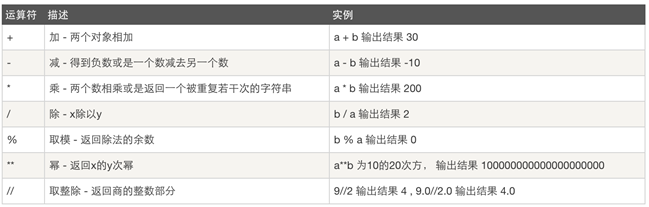
比较运算:

赋值运算:
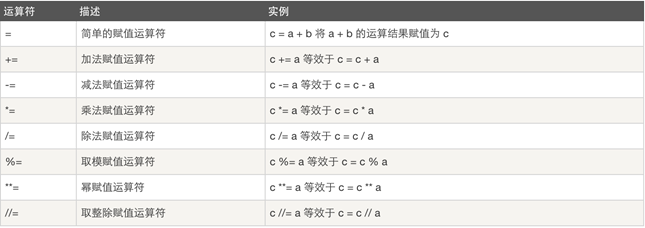
逻辑运算:

成员运算:

身份运算:id()函数,查看变量是否用同一个内存区域的内容;

位运算:
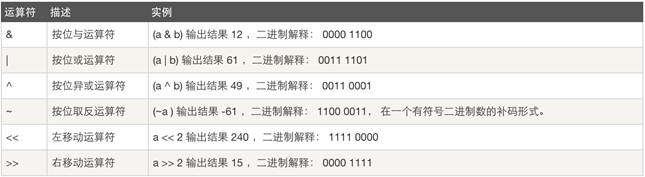
eg.
#!/usr/bin/python
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b # 12 = 0000 1100
print("Line 1 - Value of c is ", c)
c = a | b # 61 = 0011 1101
print("Line 2 - Value of c is ", c)
c = a ^ b # 49 = 0011 0001 #相同为0,不同为1
print("Line
3 - Value of c is ", c)
c = ~a # -61 = 1100 0011
print("Line 4 - Value of c is ", c)
c = a << 2 # 240 = 1111 0000
print("Line 5 - Value of c is ", c)
c = a >> 2 # 15 = 0000 1111
print("Line 6 - Value of c is ", c)
运算符优先级:
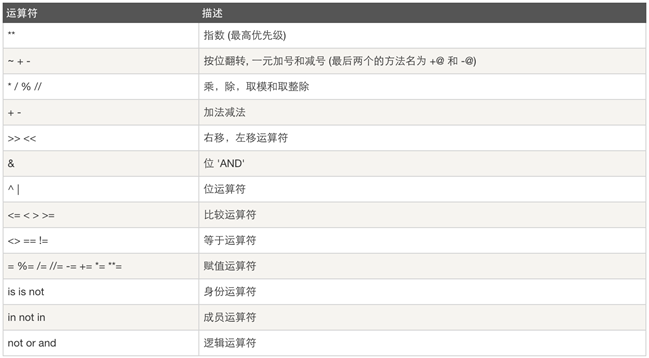
更多内容:猛击这里http://www.runoob.com/python/python-operators.html
五、入门知识拾遗
5.1三元运算
|
1 |
|
如果条件为真:result = 值1
如果条件为假:result = 值2
eg.
>>> a,b,c = 1,3,5
>>> d = a if a > b else c
>>> d
5
>>> a,b,c = 1,3,5
>>> d = a if a < b else c
>>> d
1
5.2 进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF (可以用字母H后缀表示,也可以用0x前缀表示) eg. BH(对应十进制11),0xB(也是十进制的11)。
二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
计算机内存地址和为什么用16进制?
为什么用16进制
1、计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据。十六进制更简短,因为换算的时候一位16进制数可以顶4位2进制数,也就是一个字节(8位进制可以用两个16进制表示)
2、最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
3、计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
4、为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
16进制用在哪里
1、网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
2、数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式
3、一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
5.3 对于Python,一切事物都是对象,对象基于类创建
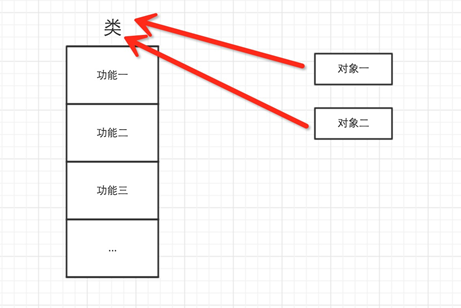
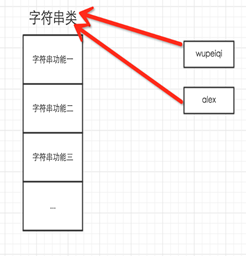
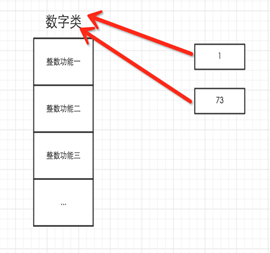
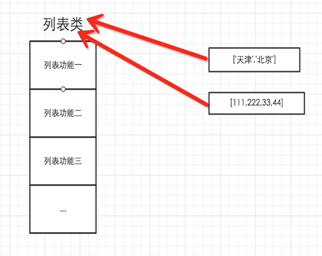
所以,以下这些值都是对象: "wupeiqi"、38、['北京', '上海', '深圳'],并且是根据不同的类生成的对象。
5.4 bytes和str
Python3的bytes/str之别
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据(例如视频、音频等)则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
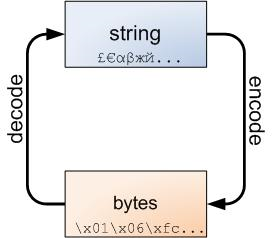
str字符串可以编码成字节包(在socket网络编程时,网络数据传输都是二进制字节包进行传输的),而字节包可以解码成字符串。
eg.字符串转二进制字节包(需要加.encode(‘utf-8’)来表示转换前的str的编码类型)
>>>'€20'.encode('utf-8')
b'\xe2\x82\xac20' # b表示二进制bytes类型
>>> b'\xe2\x82\xac20'.decode('utf-8')
'€20'
eg.
msg = '我爱北京天安门'
print(msg.encode())
print(msg.encode().decode("utf-8"))
结果:
b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
我爱北京天安门
这个问题要这么来看:字符串是文本的抽象表示。字符串由字符组成,字符则是与任何特定二进制表示无关的抽象实体。在操作字符串时,我们生活在幸福的无知之中。我们可以对字符串进行分割和分片,可以拼接和搜索字符串。我们并不关心它们内部是怎么表示的,字符串里的每个字符要用几个字节保存。只有在将字符串编码成字节包(例如,为了在信道上发送它们)或从字节包解码字符串(反向操作)时,我们才会开始关注这点。
传入encode和decode的参数是编码(或codec)。编码是一种用二进制数据表示抽象字符的方式。目前有很多种编码。上面给出的UTF-8是其中一种,下面是另一种:
>>>'€20'.encode('iso-8859-15')
b'\xa420'
>>> b'\xa420'.decode('iso-8859-15')
'€20'
编码是这个转换过程中至关重要的一部分。离了编码,bytes对象b'\xa420'只是一堆比特位而已。编码赋予其含义。采用不同的编码,这堆比特位的含义就会大不同:
>>> b'\xa420'.decode('windows-1255')
'₪20'
据说百分之八十的金钱损失皆因使用错误的编码导致,因此务必小心谨慎。
