Java IO详解(六)------序列化与反序列化(对象流)
File 类的介绍:http://www.cnblogs.com/ysocean/p/6851878.html
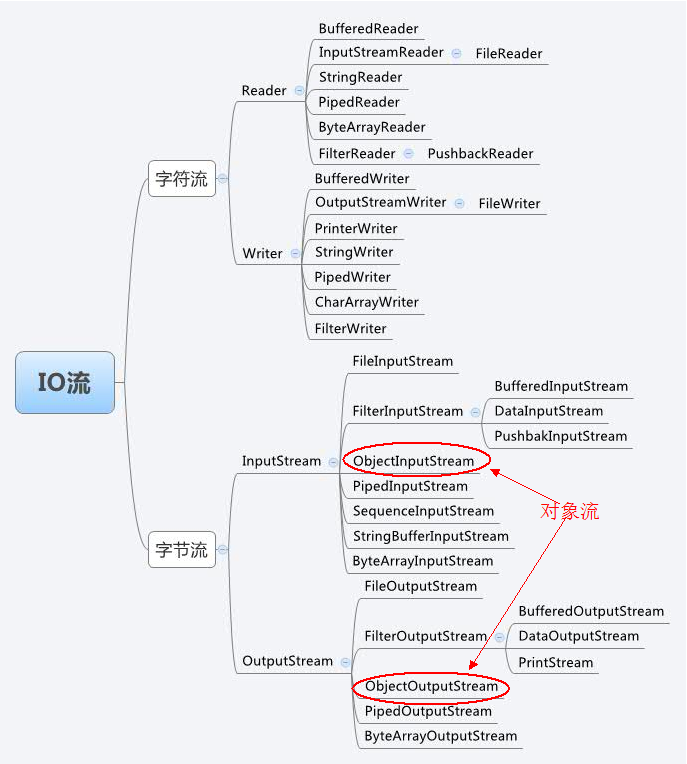
Java IO 流的分类介绍:http://www.cnblogs.com/ysocean/p/6854098.html
Java IO 字节输入输出流:http://www.cnblogs.com/ysocean/p/6854541.html
Java IO 字符输入输出流:https://i.cnblogs.com/EditPosts.aspx?postid=6859242
Java IO 包装流:http://www.cnblogs.com/ysocean/p/6864080.html
1、什么是序列化与反序列化?
序列化:指把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。这个过程称为序列化。通俗来说就是将数据结构或对象转换成二进制串的过程
反序列化:把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
2、为什么要做序列化?
①、在分布式系统中,此时需要把对象在网络上传输,就得把对象数据转换为二进制形式,需要共享的数据的 JavaBean 对象,都得做序列化。
②、服务器钝化:如果服务器发现某些对象好久没活动了,那么服务器就会把这些内存中的对象持久化在本地磁盘文件中(Java对象转换为二进制文件);如果服务器发现某些对象需要活动时,先去内存中寻找,找不到再去磁盘文件中反序列化我们的对象数据,恢复成 Java 对象。这样能节省服务器内存。
3、Java 怎么进行序列化?
①、需要做序列化的对象的类,必须实现序列化接口:Java.lang.Serializable 接口(这是一个标志接口,没有任何抽象方法),Java 中大多数类都实现了该接口,比如:String,Integer
②、底层会判断,如果当前对象是 Serializable 的实例,才允许做序列化,Java对象 instanceof Serializable 来判断。
③、在 Java 中使用对象流来完成序列化和反序列化
ObjectOutputStream:通过 writeObject()方法做序列化操作
ObjectInputStream:通过 readObject() 方法做反序列化操作
第一步:创建一个 JavaBean 对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | public class Person implements Serializable{ private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } public Person(String name, int age) { super(); this.name = name; this.age = age; }} |
第二步:使用 ObjectOutputStream 对象实现序列化
1 2 3 4 5 6 | //在根目录下新建一个 io 的文件夹 OutputStream op = new FileOutputStream("io"+File.separator+"a.txt"); ObjectOutputStream ops = new ObjectOutputStream(op); ops.writeObject(new Person("vae",1)); ops.close(); |
我们打开 a.txt 文件,发现里面的内容乱码,注意这不需要我们来看懂,这是二进制文件,计算机能读懂就行了。
错误一:如果新建的 Person 对象没有实现 Serializable 接口,那么上面的操作会报错:

第三步:使用ObjectInputStream 对象实现反序列化
反序列化的对象必须要提供该对象的字节码文件.class
1 2 3 4 5 6 7 | InputStream in = new FileInputStream("io"+File.separator+"a.txt"); ObjectInputStream os = new ObjectInputStream(in); byte[] buffer = new byte[10]; int len = -1; Person p = (Person) os.readObject(); System.out.println(p); //Person [name=vae, age=1] os.close(); |
问题1:如果某些数据不需要做序列化,比如密码,比如上面的年龄?
解决办法:在字段面前加上 transient
1 2 | private String name;//需要序列化 transient private int age;//不需要序列化 |
那么我们在反序列化的时候,打印出来的就是Person [name=vae, age=0],整型数据默认值为 0
问题2:序列化版本问题,在完成序列化操作后,由于项目的升级或修改,可能我们会对序列化对象进行修改,比如增加某个字段,那么我们在进行反序列化就会报错:
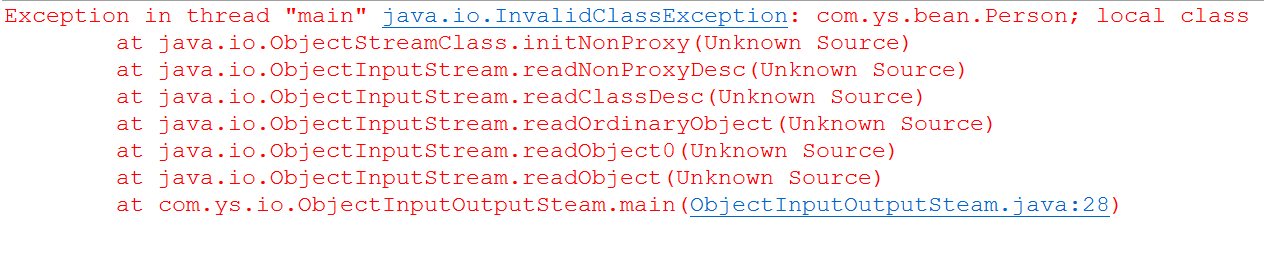

解决办法:在 JavaBean 对象中增加一个 serialVersionUID 字段,用来固定这个版本,无论我们怎么修改,版本都是一致的,就能进行反序列化了
1 | private static final long serialVersionUID = 8656128222714547171L; |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异