
【C#】C#实现对网站数据的采集和抓取
首先大家需要清楚一点的是:任何网站的页面,无论是php、jsp、aspx这些动态页面还是用后台程序生成的静态页面都是可以在浏览器中查看其HTML源文件的。
所以当你要开发数据采集程序的时候,你必须先对你试图采集的网站的前台页面结构(HTML)要有所了解。
当你对要采集数据的网站里的HTML源文件内容十分熟悉之后,剩下程序上的事情就很好办了。因为C#对Web站点进行数据采集其原理就在于“把你要采集的页面HTML源文件下载下来,分析其中HTML代码然后抓取你需要的数据,最后将这些数据保存到本地文件”。
基本流程如下图所示:
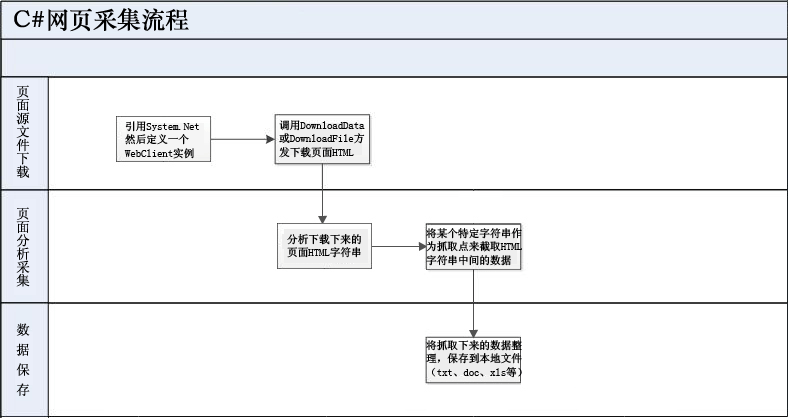
1.页面源文件下载
首先引用System.Net命名空间
此外还需引用
using System.IO;
引用完后实例化一个WebClient对象
调用DownloadData方法将指定网页的源文件下载一组BYTE数据,然后将BYTE数组转为字符串。
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的网页地址")));
或则也可以调用DownloadFile方法,先将源文件下载到本地然后再读取其字符串
wc.DownloadFile("你要采集的网页URL","保存源文件的本地文件路径");
//读取下载下来的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路径",Encoding.UTF8);
有了网页HTML格式字符串,就可以对网页分析采集并抓取你所需要的内容了。
2.页面分析采集
页面分析就是要将网页源文件中某个特定或是唯一的字符(串)作为抓取点,以这个抓取点作为开端来截取你想要的页面上的数据。
以博客园为列,比方说我要采集博客园首页上列出来的文章的标题和链接,就必须以"<a class=\"titlelnk\" href=\""作为抓取点,以此展开来抓取文章的标题和链接。

CODE:
mainData=mainData.Substring(mainData.IndexOf("<a class=\"titlelnk\" href=\"") + 26);
//获取文章页面的链接地址
string articleAddr = mainData.Substring(0,mainData.IndexOf("\""));
//获取文章标题
string articleTitle = mainData.Substring(mainData.IndexOf("target=\"_blank\">") + 16,
mainData.IndexOf("</a>") - mainData.IndexOf("target=\"_blank\">") - 16);
注意:当你要采集的网页前台HTML格式变了之后,作为抓取点的字符窜也因做相应地改变,否则是采集不到任何东西的
3.数据保存
当你把需要的数据从网页截取下来后,将数据在程序中稍加整理保存到本地文件(或插入到自己本地的数据库中)。这样整个采集工作就算搞一段落了。
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
articleData,
Encoding.UTF8);
此外附上一个我自己写的采集博客园首页文章的小程序代码,该程序的功能是可以将发布到博客园首页上所有文章采集下来。
下载地址:CnBlogCollector.rar
当然如果博客园前台页面格式调整了,那程序的采集功能肯定是无效的了,只能自己重新调整程序才能继续采集,呵呵。。。
程序效果如下:


