


CQRS,中文翻译命令和查询职责分离,它是一种架构,不仅可以从数据库层面实现读写分离,在代码层面上也是推荐读写分离的。在接口上可以更为简单
命令端定义
ICommandResult Execute(ICommand command)
查询端定义
IQueryResult Fetch(IQuery query)
它的好处是CQ每端对外只有一个接口,职责单一。带来的不便就是要定义好多命令(Command)和查询(Query)对象。但相比定义好多个接口个人觉得还是这样的方式更好。
CQRS不是一个特别炫丽的架构,我觉得他更多的是为了解决数据显示的复杂性。在实际项目中,往往是要查询的数据非常复杂和多样性(也许你并不认同),这样就可以针对查询定义相对需要的ReadModel,也可以设计多个有针对性的读库。
当我们的应用程序开发完之后就需要发布部署了,在部署之前你的应用程序需要有个宿主可以对外提供服务,它可以是WebService,Wcf,WebApi等等。
单机
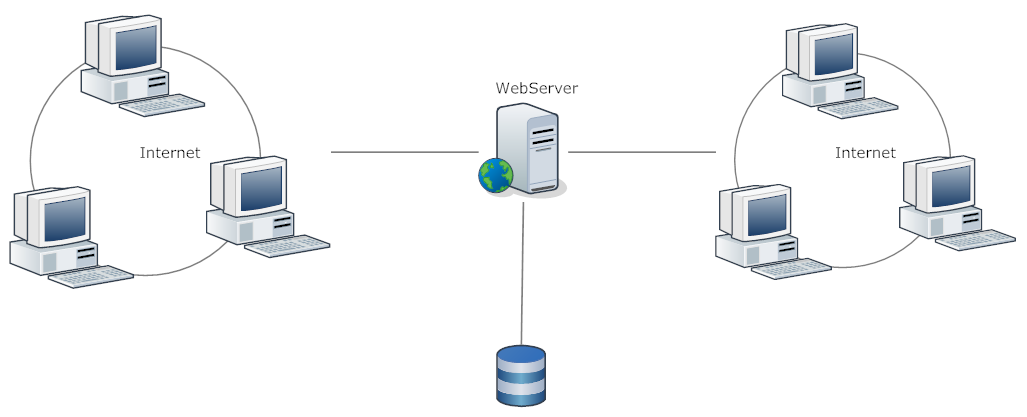
单机是一个最简单的部署方式,优点是维护和部署起来很方便, 缺点是一旦宕机你的整个服务将不可用,处理能力有限,更新应用程序可能要停止服务。
集群
最简单的方式是部署多个单机,利用DNS轮询就可以实现简单的负载均衡,这种方案的缺点就是存在会话丢失,这是因为上一次的会话是在服务器1上,可能下一次的会话DNS就会将域名指向服务器2上,可以采用Cookie或者其他方案解决这一问题。还有就是这一集群方式在处理并发上难度较大,当然也可以采用乐观锁和数据库的悲观锁机制,不过这会带来性能问题。
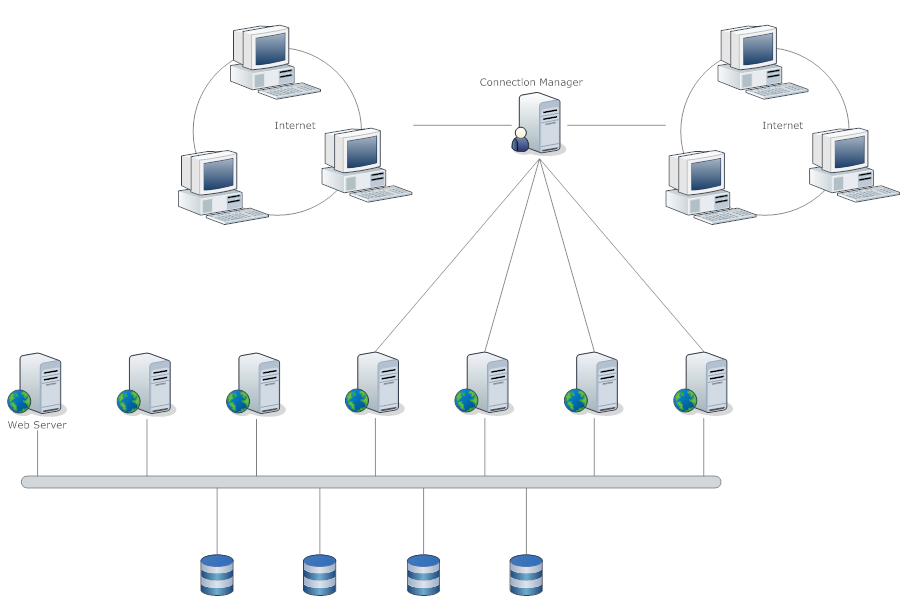
上图只是对单机集群的一种扩展,Connection Manager负责管理与客户端的连接及请求,然后将具体的命令和查询转发到具体的Server,以达到负载均衡的目的,同时它可以将处理相同命令的请求路由到同一个服务器上,可以初步解决并发问题。这种方案也有点类似ngixn,缺点就是带宽压力较大
分布式

上图的部署方式将命令和查询服务严格区分开来,利用消息队列达到流量削锋、应用解藕和异步处理的目的。命令服务接收到命令后将其发送到Kafka,将相同类型的命令发送到同一topic中,再根据Key分发到不同的partition上,利用Kafka的Rebalance动态添加消费服务,这样的话就可以当请求过多时增加服务,闲时减少服务,非常灵活。
个人觉得这样的部署有类似微服务,在此基础上还可以分离出ValidationService和AuthenticationService等,如CommandService接收到命令后通过验证服务后再发送到Kafka中,同时也是将软件层面的AOP替换成服务层面,每个CommandConsumer像是一个黑盒,外部无法访问。
简单的示例可以参考 https://github.com/imyounghan/umizoo/tree/master/src/Samples
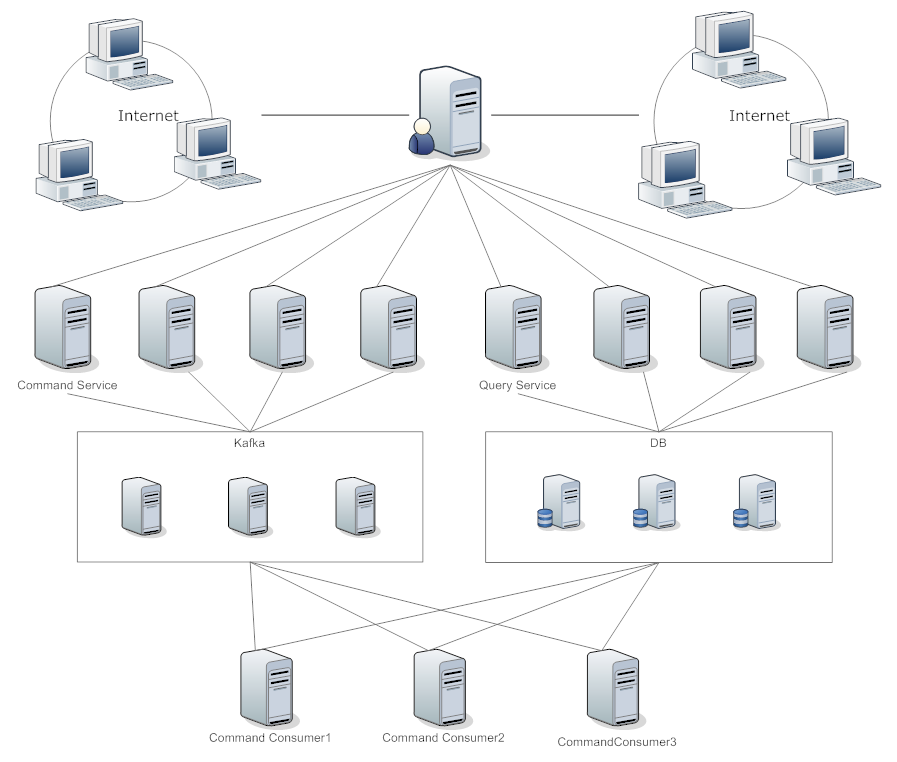
上图是对图2和图3的一个整合,利用了各自的优点。还有一种方案就是Connection Manager提供给客户端一个可用的CommandService或QueryService与客户端进行直连,这样可以避免所有的请求都要经过Connection Manager,减轻Connection Manager的带宽压力,可以参照P2P的思路。
采用了分布式后会导致服务增多,问题也会增多,管理起来也会变得复杂,可以借助Zookeeper来管理监控这些服务。总之分布式情况下要考虑的问题会有很多,本文也无逐一续清,需要掌握的知识点也较多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号