
记一次druid线程池溢出的分析解决过程--来源于生产实践
背景:
1、2019年春节前后,在将近一个月的时间内,生产服务集群中的两个节点先后发生连接池(druid实现)溢出现象,无法获取连接进行DB操作。
2、通过Jconsole连接到生产JVM,方便观察其随时间累积,各指标的运行轨迹,以此确定分析入口。
方向:
1、短时间内有大量的获取连接请求,超过了连接池配置的最大阈值,导致获取不到连接。
2、活跃连接没有放入连接池复用,同时占用连接数的统计名额(代码使用不规范未释放DB连接、druid参数配置不合理或者其本身存在bug等)。
现象:
从生产日志分析,并结合Jconsole关键指标的轨迹和druid的监控数据,得到如下现象:
1、没有可用的连接持续时间很长,从当天19点左右第一次出现问题之后,直到服务重启(持续时间12小时以上),该节点再也不能获取到连接
2、jvm内存指标保持在合理运行区间,没有异常,但线程有泄露(随着时间累积,线程数量缓慢上升)
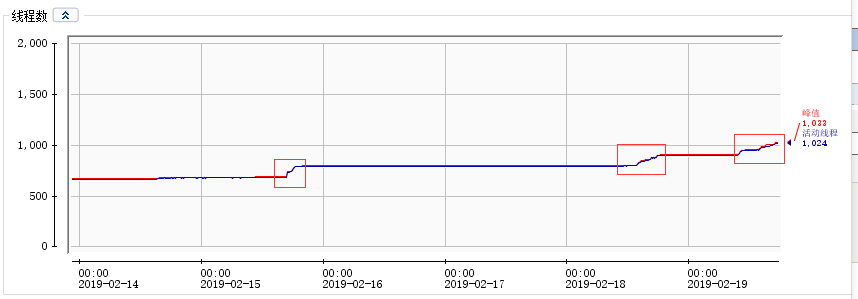
3、DB连接获取不到前,日志中发现有线程创建失败(java.lang.OutOfMemoryError: unable to create new native thread)
4、DB连接获取不到的同时,伴随着执行线程(http-bio-8080-exec-244等,来源于tomcat维护的线程池)莫名退出(追踪DB持久化的处理失败任务的日志轨迹得出)
5、存在比较多耗时长的SQL操作
分析:
通过现象1,并结合服务在重启前长时间内的请求流量指标(不大),可以排除方向1。
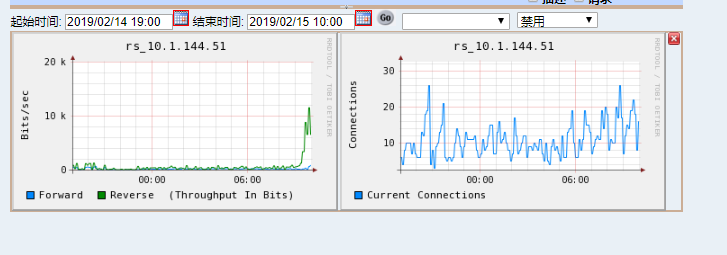
基本认定方向2。
经过代码梳理,数据库连接均通过druid管理维护,没有自主获取连接的代码;
生产druid的主要参数配置如下:
initialSize:10
minIdle:10
maxActive:100
maxWait:60000
timeBetweenEvictionRunsMillis:60000
minEvictableIdleTimeMillis:300000
注:没有配置removeAbandoned/removeAbandonedTimeout/logAbandoned(强制物理断开超过指定时间的连接并记录日志)。
如果配置这些参数,不会发生此问题,但应知道此配置会严重影响druid性能。它们只能作为验证或者发现问题的手段,不能作为常规参数配置。
结合配置参数,进行源码分析(因为之前不知天高地厚的怀疑过druid源码可能存在bug,花费比较大的经历来阅读,虽然方向错误,但收获很大。
真切的看到了其实现机制,不在是想象,以后要多创造机会品读优秀源码),比较深入的了解到其实现细节后,
明确正常情况下,活跃连接执行完操作后,会被立即放回池中待复用。
担当线程池没能正常修改池状态,就会导致其认为该连接一直处于活跃状态,不能被复用。
因为没有空闲连接可用,线程池只能通过创建新的物理连接来满足需要,直到达到池阈值,再也不能创建新的连接。
进一步从DB来验证结论,请DBA抓取事故当日指定用户的登入/登出情况(集群整体数据)。
经过匹配,发现有110个连接登入后,没有登出(2个节点,事故节点连接100,非事故节点连接10),与上面分析结论吻合。
至此,确定方向2是导致问题的原因,并进一步明确是线程突然退出导致的。
结论:
那是什么原因导致线程退出的呢?
一个进程中,能创建的线程是有上限的,在java语言里, 当你创建一个线程的时候,虚拟机会在JVM内存创建一个Thread对象,同时创建一个操作系统线程,而这个系统线程的内存用的不是JVMMemory。
理论上系统线程内存可用的最大空间为(MaxProcessMemory - JVMMemory - ReservedOsMemory)。
这正好解释了现象2和现象3,也为现象4的出现提供了可能性。
方案:
1、进一步定位线程资源溢出的问题,并修复。
2、针对现象5,对SQL进行分析优化,缩短执行时长,让DB连接尽快能够复用,提升系统TPS。
不足:
没有在准生产环境进行问题复现(复现有一定难度),并验证方案的有效性,问题的解决不应只停留在理论分析层面,要尽量创造环境来验证分析的过程和结论。
以上是关于这一生产事故的分析处理过程。
备注:druid源码分析基于1.0.13版本
