
Ubuntu16.04上搭建CDH5.14集群
硬件平台介绍
集群总共包括三台电脑,一台主机两台从机,电脑名称和名称对应关系如下:
hadoop-master 大电脑hadoop-slave1 一体机hadoop-slave2 台式机
各个主机通过路由器组件局域网,通常路由器会给每个主机分配固定的IP地址,在Ubuntu终端下,可以使用ifconfig查看机器的IP地址。如下为集群的主机和IP对应关系(需要根据自己的情况修改):
192.168.1.129 hadoop-master 192.168.1.78 hadoop-slave1 192.168.1.53 hadoop-slave2
Hostname、hosts和防火墙设置
首先在此强调所有的命令都是在root用户下执行的。
-
hostname设置
首先设置所有主机的hostname,使用下面的命令
vim /etc/hostname
hosts配置
修改所有主机的hosts配置,使用如下的命令:
vim /etc/hosts
- 关闭防火墙
使用下面的命令关闭所有主机的防火墙
iptables-save > /root/firewal.rules #保存防火墙的规则
serviece ufw stop #关闭防火墙
ssh服务配置
再次强调,所有的指令都是在root命令下执行的。
为了能够让机器远程ssh登录到root账号,需要进行两个配置:修改ssh的配置,允许远程登录到root用户;拷贝公钥。
- 修改ssh配置
首先确认在所有的节点上都安装了ssh,测试的方法为在终端输入ssh会弹出提示信息,否则显 示没有这个可执行程序。
如果没有安装ssh,则使用下面的命令安装
apt-get install openssh-*
然后使用下面的命令打开ssh配置
vim /etc/ssh/sshd_config
修改ssh的root用户远程设置
#PermitRootLogin prohibit-password #注释掉下面这一行,有时候为without-password
PermitRootLogin yes
- 生成并拷贝
ssh公钥
在所有的节点上,执行下面的命令生成ssh的公钥
ssh-keygen -t rsa
上面的命令会在当前用户目录(也就是root用户)下生成.ssh文件,里面存放了公钥和私钥,需要将公钥添加到hadoop-master和hadoop-slave[1-2]上
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-master ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-slave1 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-slave2
上面的命令会将公钥添加到远程机器相同账号(root用户)的~/.ssh/authorized_keys文件夹中。
【注意】在所有的机器上进行完上面的命令以后,再进行测试。
配置JDK环境和MySQL
- JDK安装
在Ubunt16.04上默认的jdk版本就已经够了,如果在系统上没有进行过修改, 输入java -version命令应该就会直接显示java的版本。 -
安装MySQL
在
hadoop-master节点上,使用下面的命令安装MySQL
apt-get install mysql-server mysql-client
部署Cloudera Manager
为了安装Cloudera Manager,需要执行如下的几个步骤
软件准备
(这个步骤只需要在hadoop-master上执行)首先需要准备四个文件cloudera-manager-xenial-cm5.14.0_amd64.tar.gz,CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel,CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel.sha1和manifest.json文件。如果没有这四个文件,可以使用下面的命令安装
# 默认下载在/root/backup文件夹下 mkdir -p /root/backup cd /root/backup # 下载cloudera-manager wget -c http://archive.cloudera.com/cm5/cm/5/cloudera-manager-xenial-cm5.14.0_amd64.tar.gz # 下载cdh的parcel文件 wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel # 下载cdh的parcel.sha文件 wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel.sha1 # 下载manifest文件 wget -c http://archive.cloudera.com/cdh5/parcels/latest/manifest.json
下载了四个文件以后,需要将CDH-5.14.0-1.cdh5.14.0.p0.24-xenial-parcel.sha1改名为CDH-5.14.0-1.cdh5.14.0.p0.24-xenial-parcel.sha,使用下面的命令
cd /root/backup mv CDH-5.14.0-1.cdh5.14.0.p0.24-xenial-parcel.sha1 CDH-5.14.0-1.cdh5.14.0.p0.24-xenial-parcel.sha
然后建立如下所示的文件树
| --/opt |--/cloudera |--/parcels |--/parcel-repo |--/CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel |--/CDH-5.14.0-1.cdh5.14.0.p0.24-xenial.parcel.sha |--/manifest.json |--/cm-5.14.0
- 为
Cloudera Manager连接MySQL
首先在所有节点上安装mysql-connector-java软件包
apt-get install libmysql-java
在hadoop-master上链接mysql连接库到cm
ln -s /usr/share/java/mysql-connector-java.jar /opt/cm-5.14.0/share/cmf/lib/mysql-connector-java.jar
在hadoop-master上配置cm5的数据库
cd /opt/cm-5.14.0/share/cmf/schema ./scm_prepare_database.sh mysql -uroot -p123456 scm scm scm --force
在命令中加--force是为了防止重新配置时,因为scm数据库已经存在而终止执行命令。
- 配置
Agent
在hadoop-master上修改配置文件的server
vim /opt/cm-5.14.0/etc/cloudera-scm-agent/config.ini #打开config.ini文件 server_host=hadoop-master #修改server_host为hadoop-master
将hadoop-master上的cm-5.14.0复制到其他的节点上
scp -r /opt/cm-5.14.0 hadoop-slave1:/opt/ scp -r /opt/cm-5.14.0 hadoop-slave2:/opt/
启动Cloudera Manager的Server和Agent
在hadoop-master节点上启动Server进程和Agent进程
cd /opt/cm-5.14.0/etc/init.d ./cloudera-scm-server start ./cloudera-scm-agent start
在hadoop-slave[1-2]节点上启动Agent进程
cd /opt/cm-5.14.0/etc/init.d ./cloudera-scm-agent start
正式部署-可视化集群配置
在等待Cloudera Manager Server和Agent启动完毕后,就可以使用CDH5的可视化界面了,在集群的机器上浏览器输入链接http://hadoop-master/7180,登录管理界面。如果访问失败,可能需要稍微等几十秒,不停的刷新浏览器。如果还是不行,可能是前面的配置有问题,请确认前面的配置没有错误。
- 登录
如果配置没有问题,登录以后的界面为如下所示,用户名和密码默认为admin 
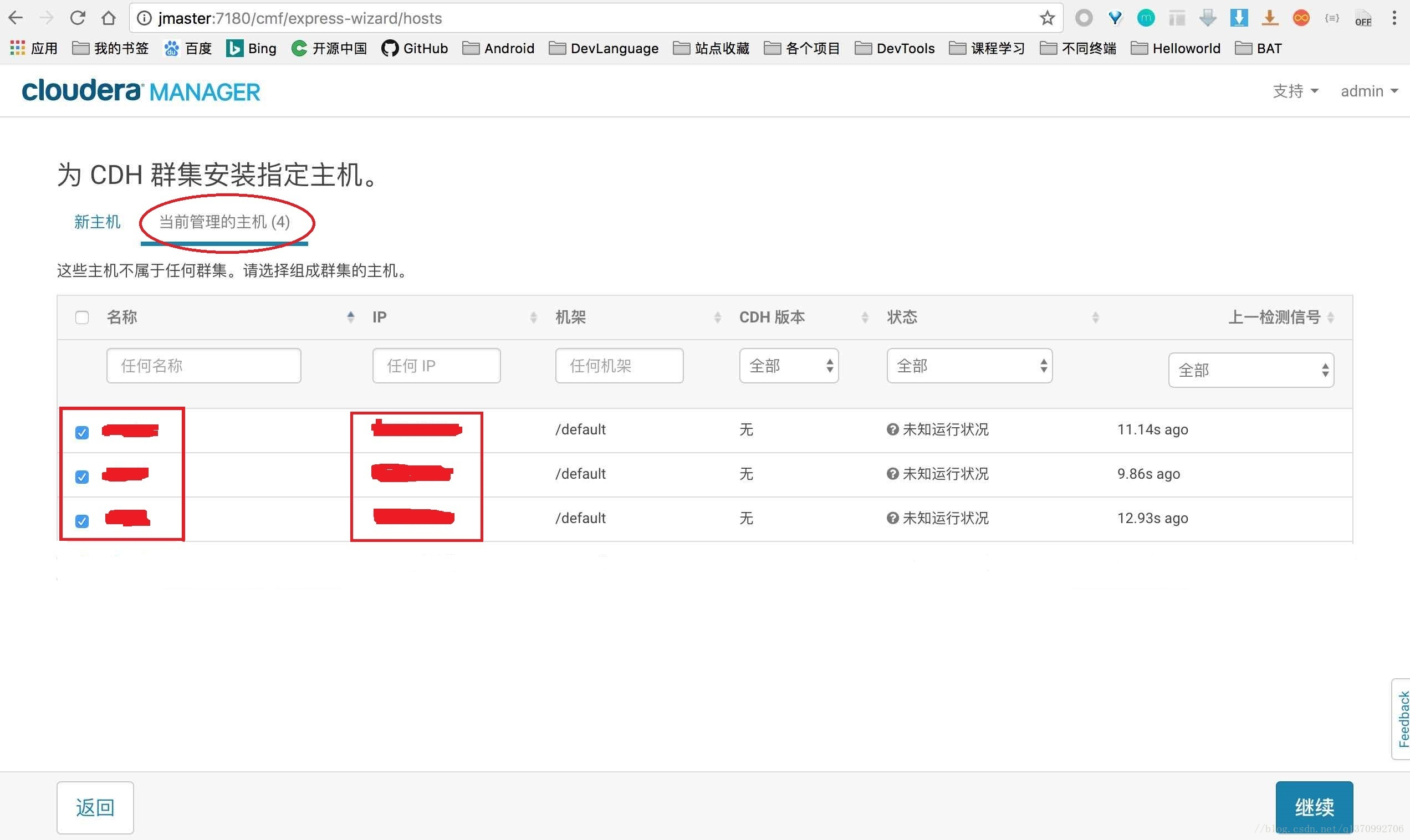
- 选择集群机器
注意,一定要选择红色椭圆那个选项,如果红色的方框内主机数目和IP地址,如果数目不对,很有可能是没有关闭防火墙,注意所有的节点都需要关闭防火墙;如果是IP地址不对,那么需要检查Hosts文件。
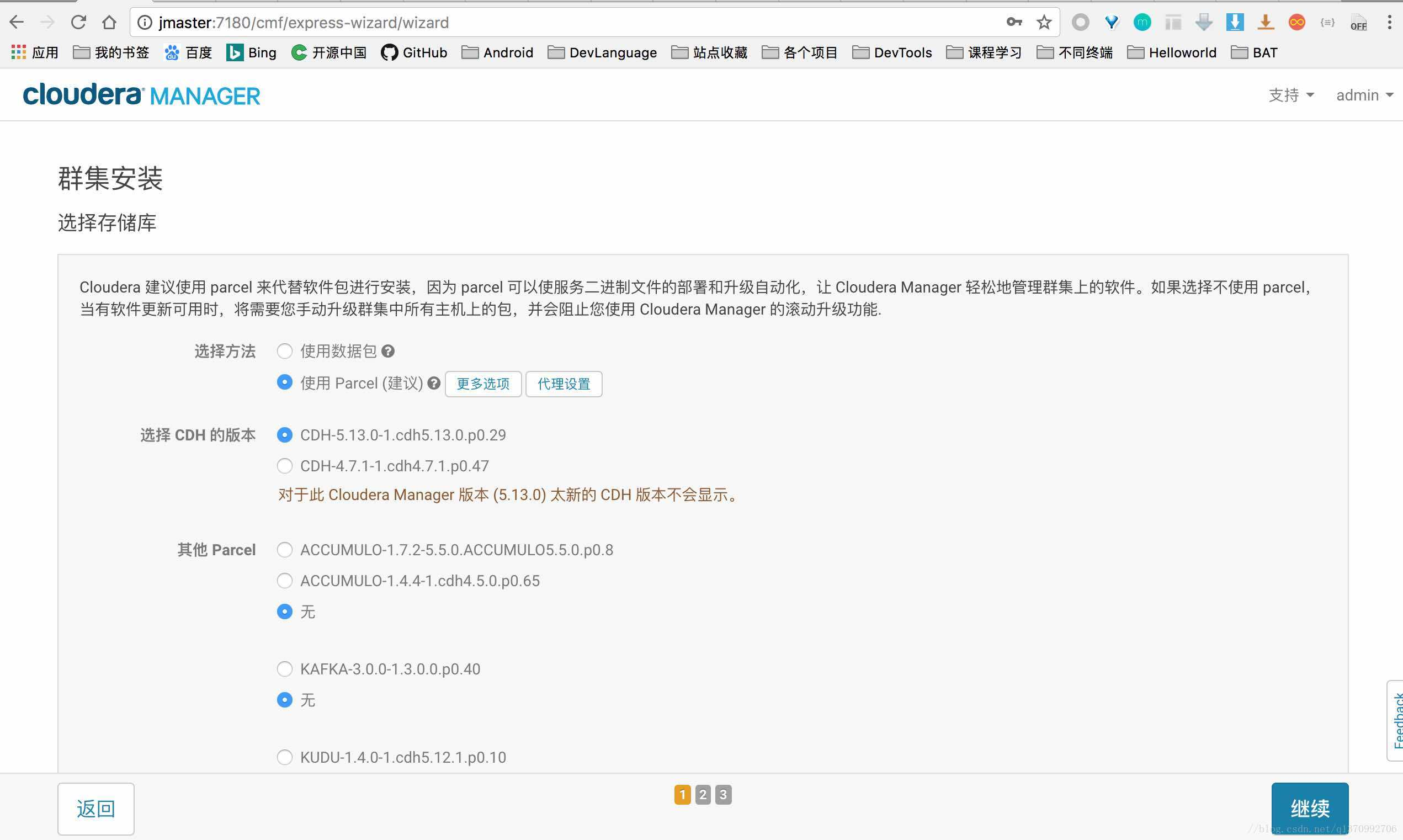
- 选择集群安装方式
请选择Parcel方式,如果CDH的版本没有5.14.0,那么请确认文件树是对的,并且xx-parcel.sha1文件名字修改为了xx-parcel.sha。
- 检测安装环境
如果出现如下的警告,在所有的节点上输入echo 10 > /proc/sys/vm/swapiness,然后刷新下浏览器。

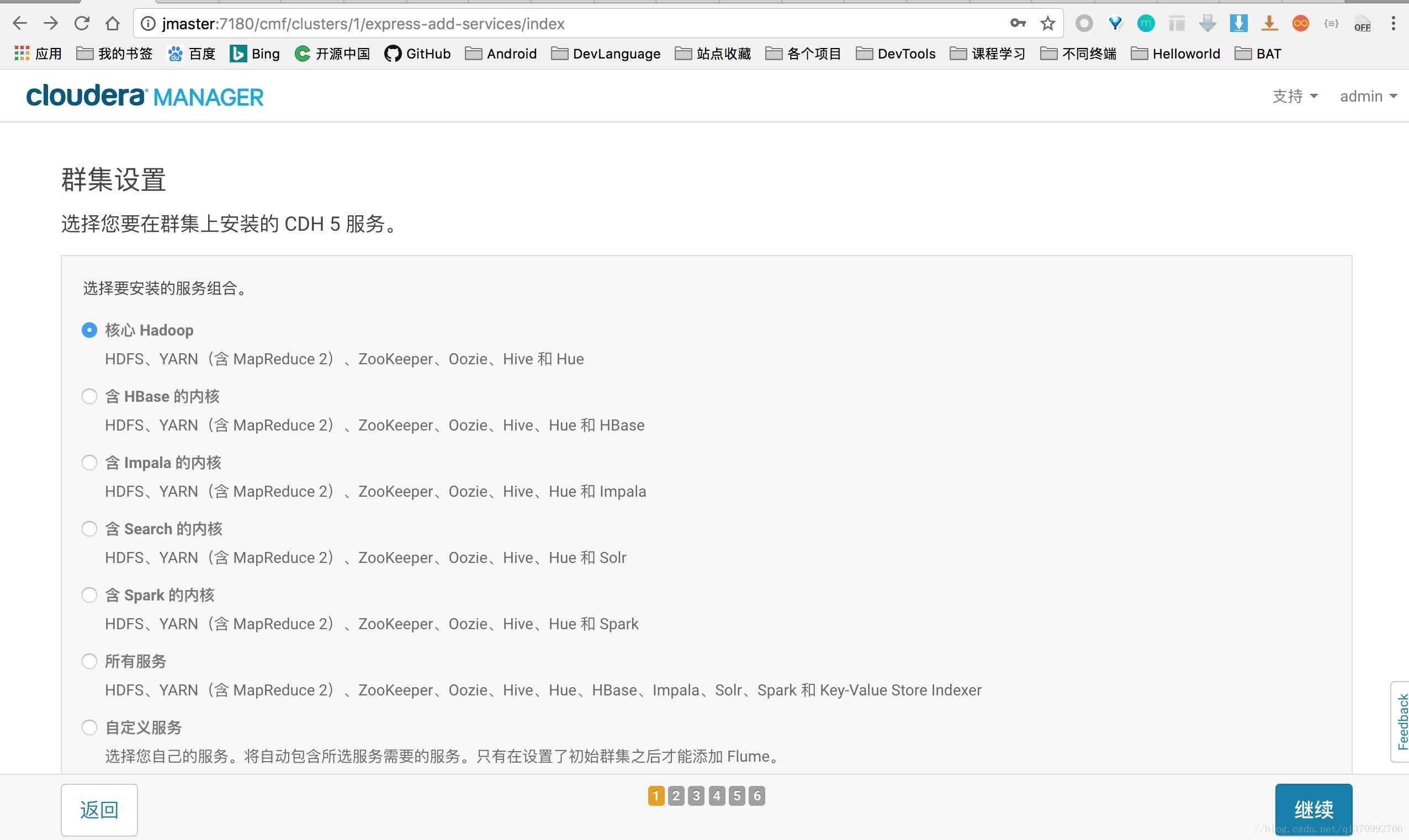
- 选择安装服务
仅选择了核心服务,如果后续需要增加,可以通过管理界面操作。
- 数据库配置
数据库配置是最容易出错的地方,配置数据库之前,首先需要创建数据库,只需要在hadoop-master节点上配置数据,包括四个数据库(hive,rman,ozzie,hue)和四个用户名(hive,rman,ozzie,hue),配置的命令如下
mysql -uroot -p123456 #创建数据库 create database hive DEFAULT CHARSET utf8; create database rman DEFAULT CHARSET utf8; create database oozie DEFAULT CHARSET utf8; create database hue DEFAULT CHARSET utf8; #创建用户名 grant all on hive.* TO 'hive'@'%' IDENTIFIED BY '123456'; grant all on rman.* TO 'hive'@'%' IDENTIFIED BY '123456'; grant all on oozie.* TO 'hive'@'%' IDENTIFIED BY '123456'; grant all on hue.* TO 'hue'@'%' IDENTIFIED BY '123456';
安装Kafka
CDH5.14安装Kafka过程:
在CDH官网中关于Kafka的安装和升级中已经说到,在CDH中,Kafka作为一个分布式的parcel,单独出来作为parcel分发安装包。只要我们把分离开的kafka的服务描述jar包和服务parcel包下载了,就可以实现完美集成了。
注意集成之前请阅读官方文档,特别是版本支持方面。
查看kafka与CDH版本对应:
https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html#pcm_kafka
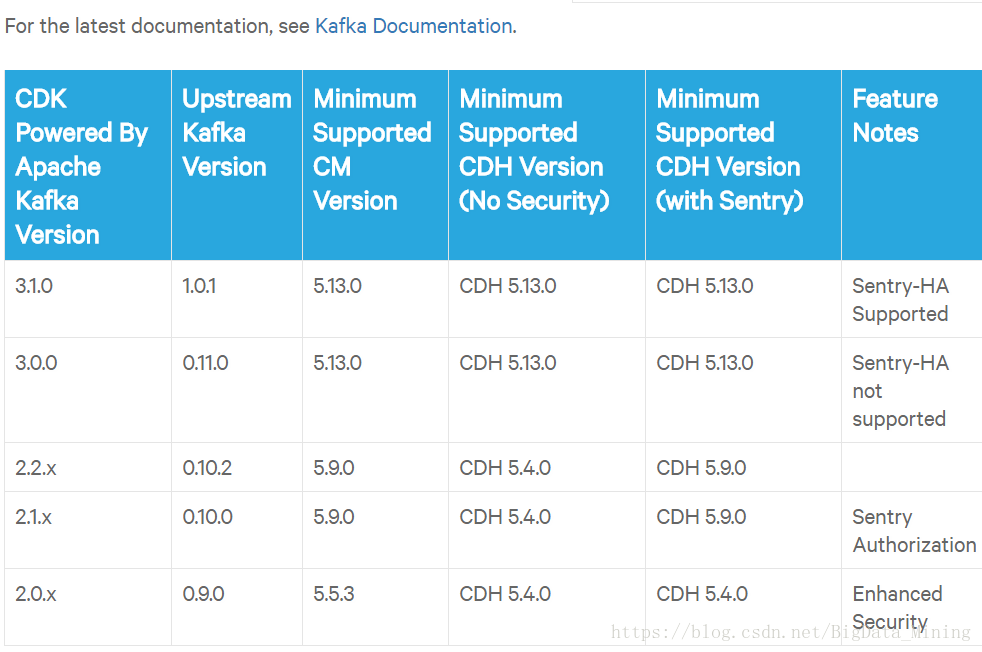
我的CDH是5.14的所以选择3.1的版本。
到:http://archive.cloudera.com/kafka/parcels/latest/
这个网址下载你需要的kafka的parcel版本。我的虚拟机是Centos7的,下载对应的版本,其版本对应如下
EL is short for Red Hat Enterprise Linux (EL). EL6 is the download for Red Hat 6.x, CentOS 6.x, and CloudLinux 6.x. EL5 is the download for Red Hat 5.x, CentOS 5.x, CloudLinux 5.x. EL7 is the download for Red Hat 7.x, CentOS 7.x, and CloudLinux 7.x. The UNIXy Varnish Plugins run on all the above platforms.
打开manifest.json

找到这个hash值,将其复制到.sha 文件中去,替换掉原来的hash值。
然后将这三个文件,拷贝到parcel-repo目录下。如果有相同的文件,即manifest.json,只需将之前的重命名即可。
2:下载Kafka-1.2.0.jar
网址:http://archive.cloudera.com/csds/kafka/
上传CSD包KAFKA-1.2.0.jar,到服务器CDH目录下,路径为/opt/cloudera/csd。
然后关闭集群,选择主机->parcel->右上角->检查新的parcel 分配并激活
然后激活完毕之后,即可向集群中添加新的kafka服务。
如果在启动过程中broker启动失败,并且日志中显示java堆溢出,那么可以在kafka的配置中,配置java heap 大一些,再重启。
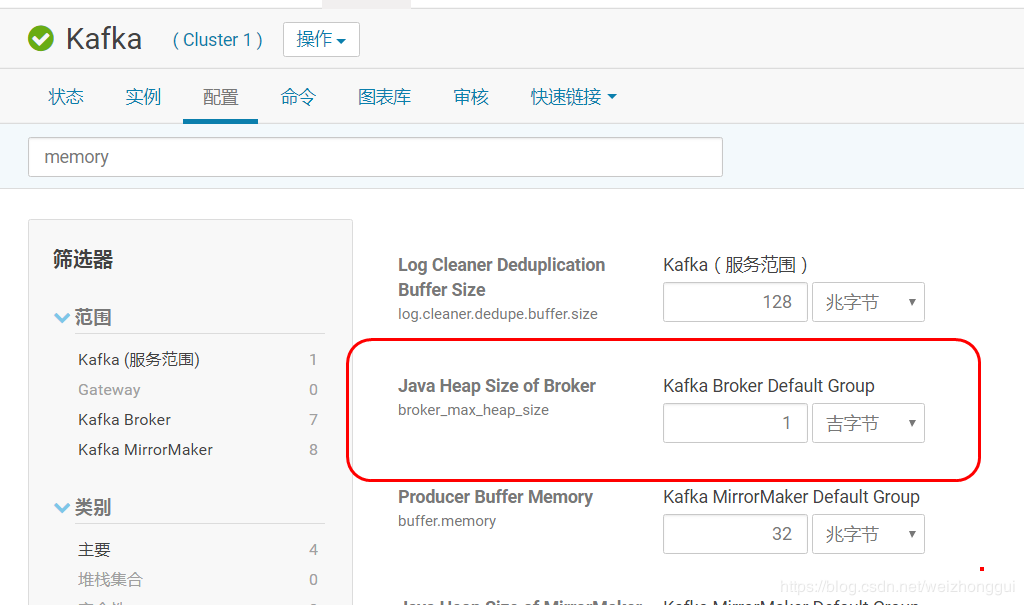
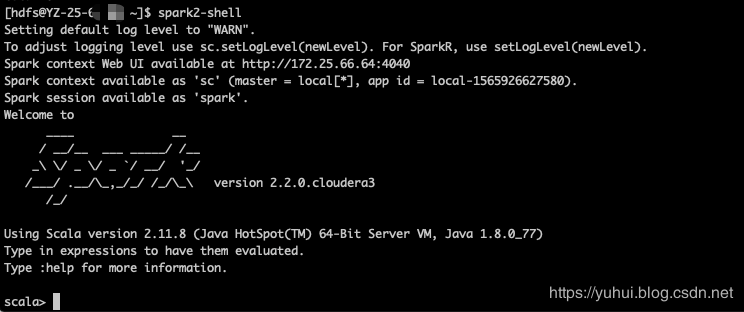
安装Spark2.0
在我的CDH5.14.4集群中,默认安装的spark是1.6版本,这里需要将其升级为spark2.x版本。经查阅官方文档,发现spark1.6和2.x是可以并行安装的,也就是说可以不用删除默认的1.6版本,可以直接安装2.x版本,它们各自用的端口也是不一样的( History Server port is 18089 instead of the usual 18088)。这里做一下安装spark2.2.0版本的步骤记录。
二、安装准备
csd包:http://archive.cloudera.com/spark2/csd/ SPARK2_ON_YARN-2.2.0.cloudera3.jar
parcel包:http://archive.cloudera.com/spark2/parcels/2.2.0.cloudera3/
SPARK2-2.2.0.cloudera3-1.cdh5.13.3.p0.556753-el6.parcel
SPARK2-2.2.0.cloudera3-1.cdh5.13.3.p0.556753-el6.parcel.sha1
manifest.json
注意,下载对应版本的包,比如:CentOS7系统,下载el7的包,若是CentOS6,就要下el6的包。
特别注意,如果你安装spark2.2,按照上面下载就是了,注意一下操作系统的版本;如果你不打算安装spark2.2,想安装其他版本,比如2.0,那么一定要注意下面的事项:
如果你仔细浏览过这些路径,会发现下图中,csd和parcel包会有.clouderal1和.clouderal2之分,和2.0与2.1版本之分,那么在下载parcel时也要注意,下载对应的包。即如果下载到的是.clouderal1的csd包,下载parcel包也要下载文件名中是.clouderal1的包,不能下载.clouderal2的包,同时csd2.0的包也不能用于parcel2.1的包,不然很可能安不上
三、开始安装
1.安装前可以停掉集群和Cloudera Management Service
2. 下面的操作,只需要在安装spark2的机器上面进行,我只选择CM server机器。
3. 上传CSD包到机器的/opt/cloudera/csd目录,并且修改文件的用户和组。注意如果本目录下有其他的jar包,把删掉或者移到其他目录
4.上传parcel包到机器的/opt/cloudera/parcel-repo目录下。
注意。如果有其他的安装包,不用删除 。但是如果本目录下有其他的重名文件比如manifest.json文件,把它重命名备份掉。然后把那3个parcel包的文件放在这里。
SPARK2-2.2.0.cloudera3-1.cdh5.13.3.p0.556753-el6.parcel
SPARK2-2.2.0.cloudera3-1.cdh5.13.3.p0.556753-el6.parcel.sha1 (把它重命名为SPARK2-2.2.0.cloudera3-1.cdh5.13.3.p0.556753-el6.parcel.sha)
manifest.json
5.如果刚刚没有停掉CM和集群,现在将他们停掉。然后运行命令。
6.把CM和集群启动起来。然后点击主机->Parcel页面,看是否多了个spark2的选项。如下图,你这里此时应该是分配按钮,点击,等待操作完成后,点击激活按钮
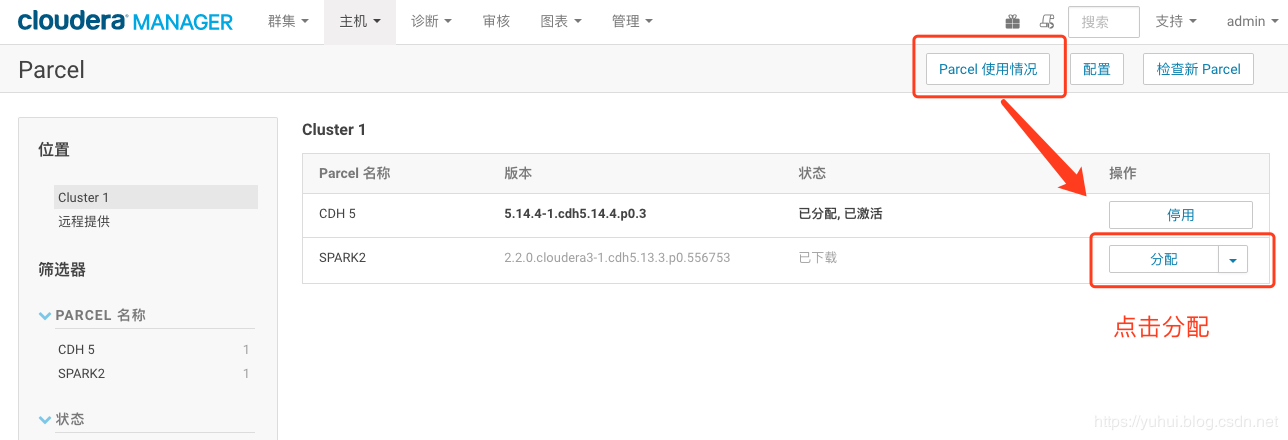
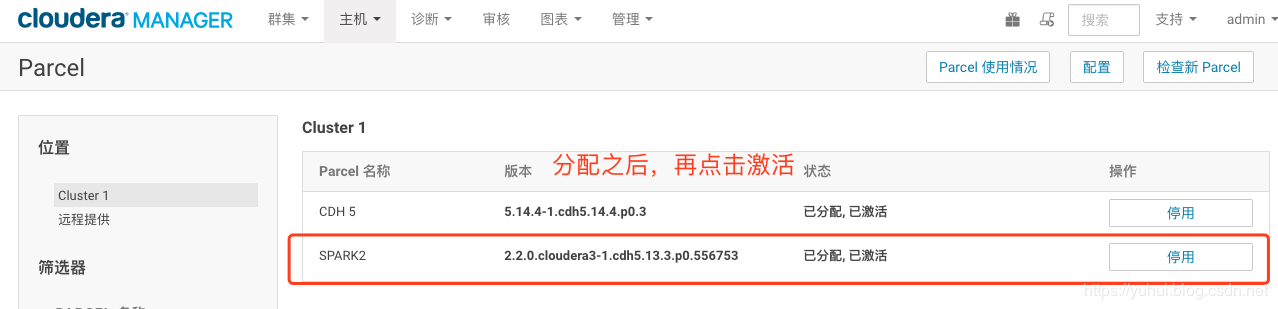
四、spark-shell启动问题
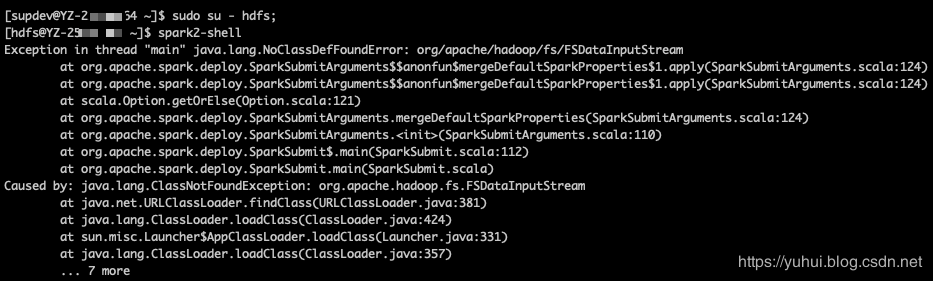
解决:
拷贝文件
cp /opt/cloudera/parcels/CDH/etc/spark/conf.dist/* /opt/cloudera/parcels/SPARK2/etc/spark2/conf.dist/
配置spark-env.sh文件
vim /opt/cloudera/parcels/SPARK2/etc/spark2/conf.dist/spark-env.sh
export SPARK_DIST_CLASSPATH=$(hadoop classpath) //指定hadoop class文件目录 export HADOOP_CONF_DIR=/etc/hadoop/conf //指定hadoop配置文件目录
使用或安装过程的异常:
1.agent启动成功之后又退出,日志中报错
ProtocolError: <ProtocolError for 127.0.0.1/RPC2: 401 Unauthor.
解决办法:
[root@dip001 ~]# ps -ef | grep supervisord
root 24491 1 0 11月30 ? 00:00:34 /usr/lib64/cmf/agent/build/env/bin/python /usr/lib64/cmf/agent/build/env/bin/supervisord
root 30335 30312 0 20:27 pts/0 00:00:00 grep --color=auto supervisord
[root@dip001 ~]# kill -9 24491
[root@dip001 ~]# ps -ef | grep supervisord
root 30338 30312 0 20:27 pts/0 00:00:00 grep --color=auto supervisord
2.上传文件,可能会报permission denied 错误,此时要先进入 hdfs 用户,再进行相应的操作
比如上传文件时:

原因是:当前的用户没有操作hdfs的权限,因此需要使用hadoop指定的用户hdfs去操作,或者直接把权限配置设置为false
方法一:
使用 su hdfs 切换到hdfs用户,然后进行相关操作。
root@node01:/etc/hadoop/conf# su hdfs hdfs@node01:/etc/hadoop/conf$ hdfs dfs -rm hdfs://node00:8020/user/core-site.xml
方法二:
配置hdfs-site.xml 中dfs.permissions为false,关闭权限控制。
3.安装hue时出现Unexpected error. Unable to verify database connection.
查看cm server下的日志/opt/cm-5.14.0/log/cloudera-scm-server,发现django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: libmysqlclient.so.20: cannot open shared object file: No such file or directory
原因是hue是基于django的,其加载需要mysql的 libmysqlclient.so.20文件,但是我们缺少了,方法是把这个文件放到/usr/lib下,如果/usr/lib/mysql下找不到,则另外下载。
安装成功后,如果需要在loadblancer上安装httpd,否则会启动失败,
sudo apt-get install apache2 sudo apt-get install apache2-dev
查看状态
sudo systemctl status apache2
4.cloudera manager报错“客户端配置 (id=2) 已使用 1 退出,而预期值为 0
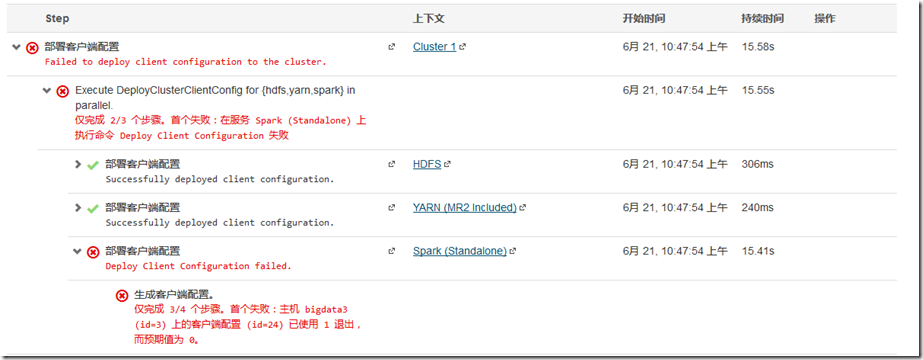
你应该能在日志文件中找到:export JAVA_HOME=/usr/java/default、JAVA_HOME=/usr/java/default、Error: JAVA_HOME is not set and could not be found等关键词,
所以明确了是jdk没有装好,为什么没装好,因为我的是使用tar.gz的jdk包安装的,没有往/usr/java中添加软链接,而这里默认是去/usr/java/default中找环境变量,才会报找不到java_home。
安装jdk的方法:把jdk软连接到/usr/java/default首先查看是否有/usr/java目录,没有的话新建此目录:mkdir /usr/java。然后添加软连接到/usr/java/default,命令如下:ln -s /home/monitor/apps/jdk1.7.0_45 /usr/java/default
为什么要添加软连接到/usr/java/default?这是因为有些软件,不会去找环境变量的java,而是找/usr/java下的,比如说cloudera manager在部署最后的spark时,一直报“上的客户端配置 (id=3) 已使用 1 退出,而预期值为 0”这个错误,其中一个原因就是访问java访问不到,参考:cloudera manager报错“客户端配置 (id=3) 已使用 1 退出,而预期值为 0”
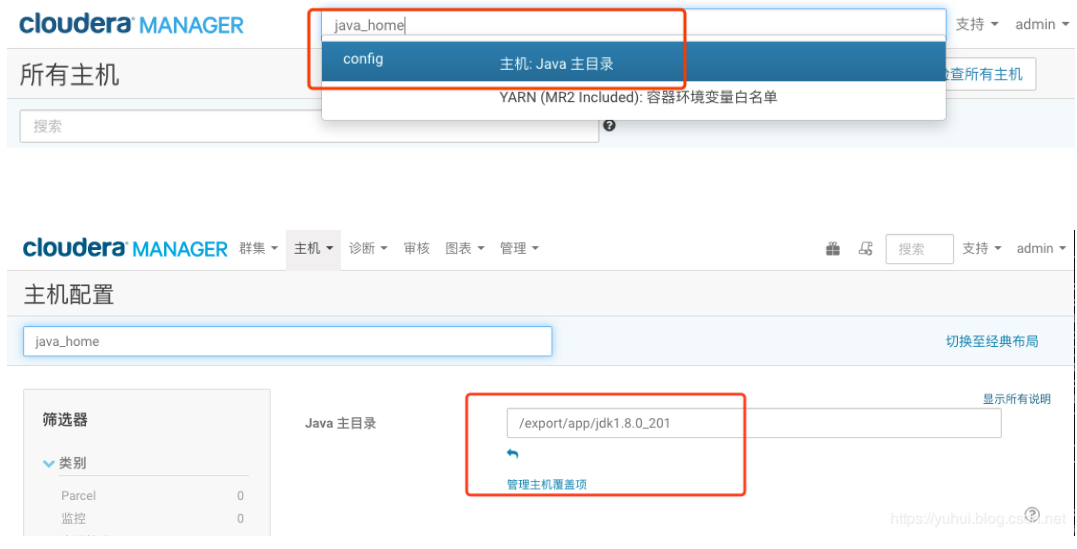
最简单的办法是:在cm的管理页面,搜索java_home,设置所有主机的java目录
文件路径
jar包路径
/opt/cloudera/parcels/CDH-5.14.0-1.cdh5.14.0.p0.24/lib
配置文件路径 /etc/hadoop/
/etc/hbase/
....
kafka的bin目录
/usr/bin/
/opt/cloudera/parcels/KAFKA/bin
Kafka Broker 日志目录
/var/log/kafka
部署目录
/etc/kafka
其他bin目录(包括flume-ng/hadoop/hbase/hive/hdfs/zookeeper等)
/opt/cloudera/parcels/CDH-5.14.0-1.cdh5.14.0.p0.24/bin/
