
机器学习基石笔记1——在何时可以使用机器学习(1)
转载请注明出处:http://www.cnblogs.com/ymingjingr/p/4271742.html
目录
机器学习基石笔记1——在何时可以使用机器学习(1)
机器学习基石笔记2——在何时可以使用机器学习(2)
机器学习基石笔记3——在何时可以使用机器学习(3)(修改版)
机器学习基石笔记4——在何时可以使用机器学习(4)
机器学习基石笔记5——为什么机器可以学习(1)
机器学习基石笔记6——为什么机器可以学习(2)
机器学习基石笔记7——为什么机器可以学习(3)
机器学习基石笔记8——为什么机器可以学习(4)
机器学习基石笔记9——机器可以怎样学习(1)
机器学习基石笔记10——机器可以怎样学习(2)
机器学习基石笔记11——机器可以怎样学习(3)
机器学习基石笔记12——机器可以怎样学习(4)
机器学习基石笔记13——机器可以怎样学得更好(1)
机器学习基石笔记14——机器可以怎样学得更好(2)
机器学习基石笔记15——机器可以怎样学得更好(3)
机器学习基石笔记16——机器可以怎样学得更好(4)
先简单介绍下这门课程,这门课是在著名的MOOC(Massive Online Open Course大型在线公开课)Coursera上的一门关于机器学习领域的课程,由国立台湾大学的年轻老师林轩田讲授。这门叫做机器学习基石的课程,共8周的课程为整个机器学习课程的上半部分,更偏重于理论和思想而非算法,主要分为四大部分来讲授。
When can Machine Learn?在何时可以使用机器学习?
Why can Machine Learn? 为什么机器可以学习?
How can Machine Learn?机器可以怎样学习?
How can Machine Learn Better?怎样能使机器学习更好?
每一大块又分为几周来讲授,每周的课时分为两个大课,每个大课一般又分为四个小块来教学,一个小块一般在十分钟到二十分钟之间。
以VC bound (VC限制)作为总线将整个基础课程贯通讲解了包括PLA(Perceptron learning algorithm感知器)、pocket、二元分类、线性回归(linear regression)、logistic回归(logistic regression)等等。
以下不用大课小课来叙述了,写起来感觉怪怪的,就用章节来分别代表大课时和小课时。
一、The learning problem
机器学习问题。
-
Course Introduction
课程简介。
第一小节的内容就是课程简介,如上已进行了详细的介绍,这里就不多赘述。
1.2 What is Machine Learning
什么是机器学习?
在搞清这个问题之前,先要搞清什么是学习。
学习可以是人或者动物通过观察思考获得一定的技巧过程。
而机器学习与之类似,是计算机通过数据和计算获得一定技巧的过程。
注意这一对比,学习是通过观察而机器学习是通过数据(是计算机的一种观察)。
对比图如图1-1。(本笔记的图和公式如不加说明皆是出自林老师的课件,下文不会对此在做说明)


图1-1 学习与机器学习对比图 a)学习 b)机器学习
那么紧接着就是要解决上述中出现的一个新的名词"技巧"(skill)。
什么是技巧呢?技巧是一些能力表现的更加出色。
机器学习中的技巧如预测(prediction)、识别(recognition)。
来一个例子:从股票的数据中获得收益增多的这种技巧,这就是一种机器学习的例子。
那既然人也可以通过观察获得一个技巧,为什么还需要机器学习呢?
这就是为什么需要机器学习,简单来说,就是两大原因:
一些数据或者信息,人来无法获取,可能是一些人无法识别的事物,或是数据信息量特别大;
另一个原因是人的处理满足不了需求,比如:定义很多很多的规则满足物体识别或者其他需求;在短时间内通过大量信息做出判断等等。
上面说的是为什么使用机器学习,那么什么情况下使用机器学习呢?是不是所有的情况都使用机器学习呢?
这里给出了三个ML(机器学习的英文缩写)的关键要素:
1、存在一个模式或者说表现可以让我们对它进行改进提高;
2、规则并不容易那么定义;
3、需要有数据。
1.3 Applications of Machine Learning
机器学习的应用。
这一小节主要介绍的就是机器学习能用在哪些方面。个人感觉不是理论介绍的重点(不是说应用不重要,刚好相反,其实个人认为机器学习甚至整个计算机学科最重要的还是应用),就简述下机器学习可以应用在在衣食住行育乐,包含了人类生活的方方面面,所以机器学习的应用场景很广泛很有市场。
1.4 Components of Machine Learning
机器学习的组成部分。
这一小节是第一章的重点,因为它将机器学习的理论应用符号及数学知识进行表示,而以下各章内容也都是在这小节内容的基础上展开的。
从一个银行是否会发信用卡给用户的例子引出了机器学习可以分为哪几个部分(组件)。
1.输入(input):x∈X(代表银行所掌握的用户信息)
2.输出(output):y∈Y (是否会发信用卡给用户)
3.未知的函数,即目标函数(target function):f:X→Y(理想的信用卡发放公式)
4.数据或者叫做资料( data),即训练样本( training examples):D = {( ), (
), (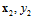 ), …, (
), …, (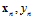 )}(银行的历史记录)
)}(银行的历史记录)
5.假设(hypothesis),即前面提到的技能,能够具有更好地表现:g:X→Y (能够学习到的公式)
可以通过一个简单的流程图表示,如图1-2所示。

图1-2 机器学习的简单流程图
从图中可以清楚机器学习就是从我们未知但是却存在的一个规则或者公式f中得到大量的数据或者说资料(训练样本),在这些资料的基础上得到一个近似于未知规则g的过程。
这么说还是有点抽象,特别是目标函数f又是未知的,那为什么还能找到一个假设g能够接近f呢?
还是以一个更加详细的流程图来说明这一问题,如图1-3。
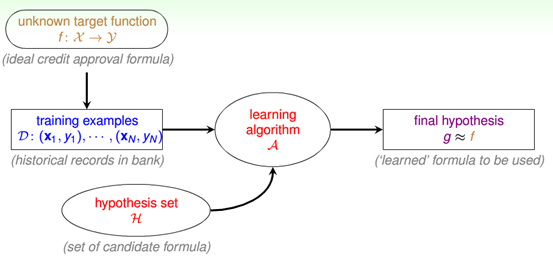
图1-3 详细的机器学习流程图
这个流程图和图1-2有些不同,其中ML被更详细的定义为机器学习算法(learning algorithm)一般用A表示。还多出来一个新的项目,就是假设空间或者叫做假设集合(hypothesis set)一般用H表示,它是包含各种各样的假设,其中包括好的假设和坏的假设,而这时A的作用就体现了,它可以从H这个集合中挑选出它认为最好的假设作为g。
注:
1、这里还要说明的是机器学习的输入在这个流程图中就变成了两个部分,一个是训练样本集,而另一个就是假设空间H。
2、还有一点需要注意的是,我们所说的机器学习模型在这个流程图中也不仅仅是算法A,而且还包含了假设空间H。
3、要求得g来近似于未知目标函数f。
4、给出了机器学习的一个更准确点的定义,就是通过数据来计算得到一个假设g使它接近未知目标函数。
图1-3是还是一个相对比较简单的机器学习流程图,在往后的章节中会不断的根据新学的知识继续扩展这幅图的元素。
1.5 Machine Learning and Other Fields
机器学习与其他各个领域的关系。
1.5.1 ML VS DM (Data Mining)
机器学习与数据挖掘者叫知识发现(KDD Knowledge Discovery in Dataset)。
上一节中已经给出了机器学习的概念,因此只介绍下数据挖掘的概念,就是从大量的数据中找出有用的信息。
从定义出发,我们可以将两者之间的关系分为3种。
-
两者是一致的:能够找出的有用信息就是我们要求得的近似目标函数的假设。
-
两者是互助的:能够找出的有用信息就能帮助我们找出近似的假设,反之也可行。
-
传统的数据挖掘更关注与从大量的数据中的计算问题。
总的来时,两者密不可分。
1.5.2 M L VS AI (artificial intelligence)
机器学习与人工智能。
人工智能的大概概念就是电脑能够表现出一些智慧行为。
从定义可以得到,机器学习是实现人工智能的一种方式。
1.5.3 ML VS statistic
机器学习与统计。
统计也需要通过数据,来做一个未知的推论。
因此统计是一种实现机器学习的方法。
传统的统计学习更关注与数学公式,而非计算本身。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号