福大软工1816 · 第五次作业 - 结对作业2
一、结对同学的博客链接、本作业博客的链接、Fork的同名仓库的Github项目地址
二、具体分工:
基本功能部分:郑孔宇
测试及附加题部分:俞凯欣
三、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 540 | 620 |
| Development | 开发 | 0 | 0 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 60 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 20 | 20 |
| · Coding | · 具体编码 | 220 | 360 |
| · Code Review | · 代码复审 | 40 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 0 | 0 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 3 |
四、需求分析

五、功能实现
1.主函数
- 获取命令行中的所有指令,并执行相关函数
int main(int args, char* argv[])
{
char* a = NULL;
char* b = NULL;
char* c = NULL;
char* d = NULL;
char* e = NULL;
string cstr, dstr, estr;
int i;
int w = 0, m = 0, n = 0;
for (i = 0; i < args; i++)
{
if (strcmp(argv[i], "-i") == 0) //检测-i指令
{
a = argv[i + 1];
}
if (strcmp(argv[i], "-o") == 0) //检测-o指令
{
b = argv[i + 1];
}
if (strcmp(argv[i], "-w") == 0) //检测-w指令
{
c = argv[i + 1];
cstr = c;
w = atoi(cstr.c_str());
}
if (strcmp(argv[i], "-n") == 0) //检测-n指令
{
d = argv[i + 1];
dstr = d;
n = atoi(dstr.c_str());
}
if (strcmp(argv[i], "-m") == 0) //检测-m指令
{
e = argv[i + 1];
estr = e;
m = atoi(estr.c_str());
}
}
readtxt(a); //读取文件并获取所有字符数
divide_n(w); //获取行数 单词数 排除Title: Abstract: 和编号后的字符数,并分割、存入和排序单词
if (m == 0)
{
writetxt_n(b, n); //输出无-m时候的格式
}
else
{
readtxt2(a); //读取文件不改变字符数,用于重新分割
divide_m(w, m); //分割单词若满足词组条件则存入并排序
writetxt_m(b); //输出有-m时候的格式
}
}
2.词频统计(divide_n) (writetxt_n)

void divide_n(int w)
{
size_t length;
string wordstring;
char wordchar[999];
int w2 = 1;
int i, j, k = 0;
int pos = 0;
const char *sep = "./;'[] \\<>?:\"{}|`~!@#$%^&*()_+-=\n"; //需要分割的字符
char *p;
char *buf;
p = strtok_s(s, sep, &buf);
while (p)
{
wordstring = p;
strcpy_s(wordchar, wordstring.c_str());
if (strcmp(wordchar, "Title") == 0)
{
charnum -= 11;
linenum++;
w2 = w;
} // 出现Title 权重为w;
else if (strcmp(wordchar, "Abstract") == 0)
{
charnum -= 10;
linenum++;
w2 = 1;
}// 出现Abstract 权重为1;
else
{
length = wordstring.length();
for (i = 0; i <= length; i++)
{
if (wordchar[i] >= 'A' && wordchar[i] <= 'Z')
{
wordchar[i] = wordchar[i] + 32;
}
}
wordstring = wordchar;
if (wordstring.length() >= 4)
{
for (j = 0; j <= 3; j++)//判断该单词是否符合前四位为字母
{
if (wordchar[j] >= 'a' && wordchar[j] <= 'z')
pos = 1;
else
{
pos = 0;
break;
}
}
}
if (pos == 1)
{
wordnum++;
if (w_c.count(wordstring) == 0)
{
w_c.insert(make_pair(wordstring, w2));
}
else
{
w_c[wordstring] += w2;
}
pos = 0;
}
}
p = strtok_s(NULL, sep, &buf);
}
for (w_c_iter = w_c.begin(); w_c_iter != w_c.end(); w_c_iter++)
{
w_c2.push_back(make_pair(w_c_iter->first, w_c_iter->second));
}
sort(w_c2.begin(), w_c2.end(), Comp);
}
void writetxt_n(char *b, int n)
{
char charnum_s[10], wordnum_s[10], linenum_s[10];
char num_s[10];
string res;
char res_c[200000];
_itoa_s(charnum + 2, charnum_s, 10);
_itoa_s(wordnum, wordnum_s, 10);
_itoa_s(linenum, linenum_s, 10);
res = res + "characters: " + charnum_s + "\n";
res = res + "words: " + wordnum_s + "\n";
res = res + "lines: " + linenum_s + "\n";
if (n == 0)
{
n = 10;
}
if (w_c2.size() >= n)
{
for (w_c2_iter = w_c2.begin(); w_c2_iter != w_c2.begin() + n; w_c2_iter++)
{
_itoa_s(w_c2_iter->second, num_s, 10);
res = res + "<" + w_c2_iter->first + ">: " + num_s + "\n";
}
}
else
{
for (w_c2_iter = w_c2.begin(); w_c2_iter != w_c2.end(); w_c2_iter++)
{
_itoa_s(w_c2_iter->second, num_s, 10);
res = res + "<" + w_c2_iter->first + ">: " + num_s + "\n";
}
}
strcpy_s(res_c, res.c_str());
FILE *fp1;
errno_t err;
err = fopen_s(&fp1, b, "w");
fwrite(res_c, res.length(), 1, fp1);
}
3.词组统计(divide_m) (writetxt_m)

void divide_m(int w, int m)
{
size_t length;
int cznum = 0;
string cz;
string wordstring;
char wordchar[999];
int w2 = 1;
int i, j, k = 0;
int pos = 0;
const char *sep = "./;'[] \\<>?:\"{}|`~!@#$%^&*()_+-=\n"; //需要分割的字符
char *p = NULL;
char *buf;
p = strtok_s(s, sep, &buf);
while (p)
{
wordstring = p;
strcpy_s(wordchar, wordstring.c_str());
if (strcmp(wordchar, "Title") == 0)
{
w2 = w;
while (cz_q1.empty() == 0)
{
cz_q1.pop();
}
while (cz_q2.empty() == 0)
{
cz_q2.pop();
}
} // 出现Title 权重为w;
else if (strcmp(wordchar, "Abstract") == 0)
{
w2 = 1;
while (cz_q1.empty() == 0)
{
cz_q1.pop();
}
while (cz_q2.empty() == 0)
{
cz_q2.pop();
}
}// 出现Abstract 权重为1;
else
{
length = wordstring.length();
for (i = 0; i <= length; i++)
{
if (wordchar[i] >= 'A' && wordchar[i] <= 'Z')
{
wordchar[i] = wordchar[i] + 32;
}
}
wordstring = wordchar;
if (wordstring.length() >= 4) //合法pos=1 不合法pos=0
{
for (j = 0; j <= 3; j++)//判断该单词是否符合前四位为字母
{
if (wordchar[j] >= 'a' && wordchar[j] <= 'z')
{
pos = 1;
}
else
{
pos = 0;
break;
}
}
}
else
{
pos = 0;
}
if (pos == 1)
{
if (cz_q2.size() == 0)
{
cz = "";
}
cz_q1.push(wordstring); //将合法单词入队q1
cz_q2.push(wordstring); //将合法单词入队q2
if (cz_q2.size() == m)
{
cz_q1.pop(); //若满足条件称为词组 则q1的首个单词出队
for (i = 1; i <= m; i++) //q2的所有单词存入cz中 用于输出并清空q2
{
if (i == m)
{
cz = cz + cz_q2.front();
cz_q2.pop();
}
else
{
cz = cz + cz_q2.front() + " ";
cz_q2.pop();
}
}
if (cz_c.count(cz) == 0) //查询map中是否有该词组 无则将 词组,频率 引入 有则将原有 词组的频率累加
{
cz_c.insert(make_pair(cz, w2));
cz = "";
}
else
{
cz_c[cz] += w2;
cz = "";
}
for (j = 1; j <= cz_q1.size(); j++) //将q1中剩余单词存入pop[]中 同步存入q2
{
pop[j] = cz_q1.front();
cz_q1.pop();
cz_q1.push(pop[j]);
cz_q2.push(pop[j]);
}
}
}
else if (pos == 0) //当遇到非法单词 将两个队列清空
{
while (cz_q1.empty() == 0)
{
cz_q1.pop();
}
while (cz_q2.empty() == 0)
{
cz_q2.pop();
}
}
}
p = strtok_s(NULL, sep, &buf);
}
for (cz_c_iter = cz_c.begin(); cz_c_iter != cz_c.end(); cz_c_iter++)
{
cz_c2.push_back(make_pair(cz_c_iter->first, cz_c_iter->second));
}
sort(cz_c2.begin(), cz_c2.end(), Comp);
}
void writetxt_m(char *b)
{
char charnum_s[10], wordnum_s[10], linenum_s[10];
char num_s[10];
string res;
char res_c[200000];
_itoa_s(charnum + 2, charnum_s, 10);
_itoa_s(wordnum, wordnum_s, 10);
_itoa_s(linenum, linenum_s, 10);
res = res + "characters: " + charnum_s + "\n";
res = res + "words: " + wordnum_s + "\n";
res = res + "lines: " + linenum_s + "\n";
if (cz_c2.size() >= 10)
{
for (cz_c2_iter = cz_c2.begin(); cz_c2_iter != cz_c2.begin() + 10; cz_c2_iter++)
{
_itoa_s(cz_c2_iter->second, num_s, 10);
res = res + "<" + cz_c2_iter->first + ">: " + num_s + "\n";
}
}
else
{
for (cz_c2_iter = cz_c2.begin(); cz_c2_iter != cz_c2.end(); cz_c2_iter++)
{
_itoa_s(cz_c2_iter->second, num_s, 10);
res = res + "<" + cz_c2_iter->first + ">: " + num_s + "\n";
}
}
strcpy_s(res_c, res.c_str());
FILE *fp1;
errno_t err;
err = fopen_s(&fp1, b, "w");
fwrite(res_c, res.length(), 1, fp1);
}
六、测试结果
- 输入

- 输出

七、性能分析
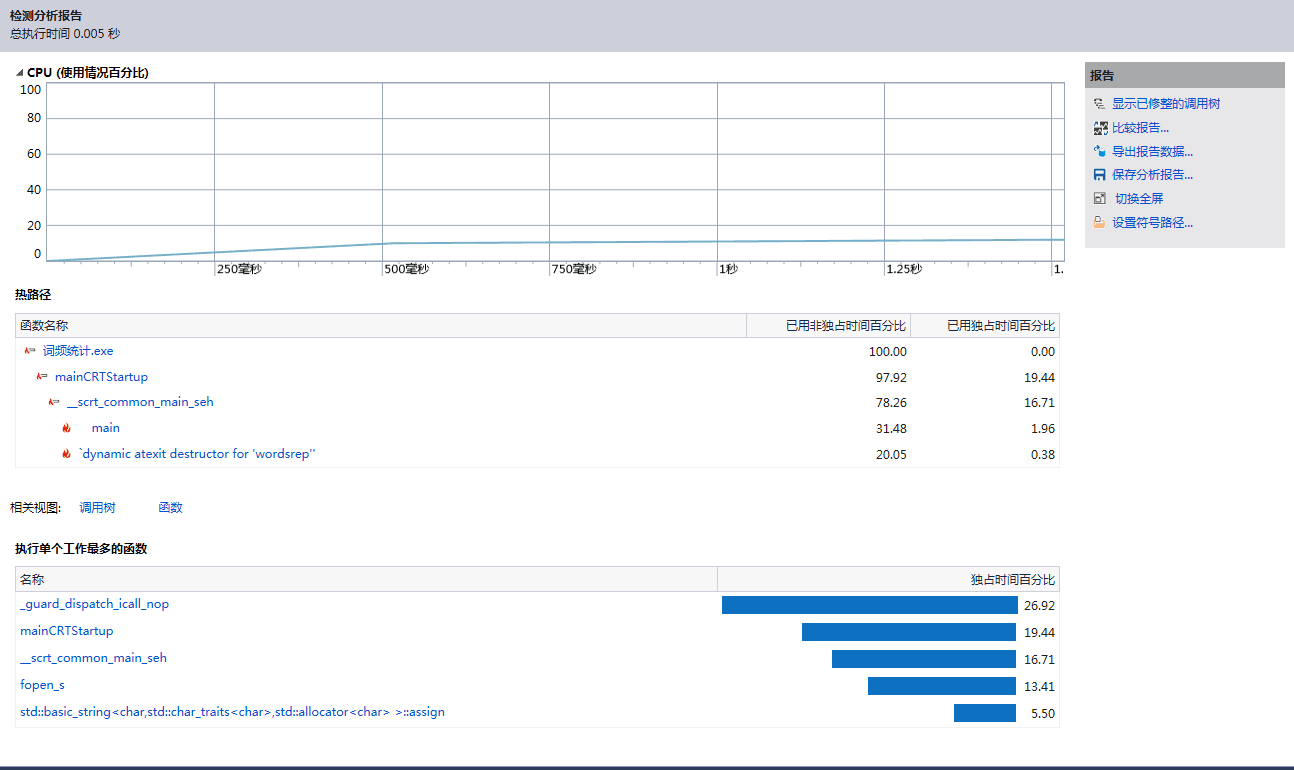

八、附加功能
* 代码
import json
from pyecharts import Bar, Line, Scatter, EffectScatter, Grid, WordCloud, Graph, Page
name = ["learning","with","image","from","network","that","deep","networks","this","video","visual","neural","detection","model","segmentation","multi"]
value = [2879,2744,2306,1826,1757,1757,1735,1510,1423,1088,1030,952,938,909,889,827]
wordcloud = WordCloud("CVPR热词图谱")
wordcloud.add("", name, value, word_size_range=[20, 100])
wordcloud.render()

九、评价队友
刻苦勤奋!
十、学习记录
| 第N周 | 新增代码 | 累计代码 | 本周学习时间 | 累计学习时间(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 5 | 5 | 对Axure的学习 |
| 5 | 200 | 400 | 7 | 12 | 函数学习 |
| 5 | 200 | 600 | 7 | 19 | 函数学习 |

